

- Qwen3.7-Plusは、Alibaba Cloudが公開したマルチモーダル対応のフラグシップAIモデル
- LM ArenaのVision Arenaで世界第16位にランクイン
- テキストに加えて画像・動画の入力にも対応しており、推論と視覚認識を両立するバランス型モデル
Qwen3.7-Plusは、Alibaba CloudのQwenチームが開発したQwen3.7シリーズのマルチモーダルモデルです!
— Qwen (@Alibaba_Qwen) June 1, 2026
Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
テキスト専用の推論特化モデルであるQwen3.7-Maxの兄弟モデルとして位置づけられており、画像入力にも対応している点が大きな特徴となっています。
LM ArenaのVision Arenaでは世界第16位を記録し、Alibabaをビジョン分野でラボランキング世界第5位にまで押し上げました。「どうやって使うの?」「Maxとの違いは?」「料金はいくら?」と気になっている方も多いのではないでしょうか?
そこで本記事では、Qwen3.7-Plusの概要や仕組み、特徴、料金体系、具体的な使い方まで詳しく解説します。ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Qwen3.7-Plusとは?

Qwen3.7-Plusは、2026年6月2日にAlibaba Cloudが公開したQwen3.7シリーズのマルチモーダルAIモデルです。
Qwenシリーズは、中国のテック大手アリババグループのクラウド部門であるAlibaba Cloudが開発を手がける大規模言語モデルのファミリーで、2023年4月に初代モデルがリリースされて以来、精力的にアップデートが続けられてきました。
2026年に入ってからはリリースペースがさらに加速しており、2月のQwen3.5シリーズ、4月のQwen3.6シリーズに続いて、わずか1ヶ月ほどで今回のQwen3.7シリーズが登場しています。
Qwen3.7シリーズには「Max」と「Plus」の2つのバリエーションがあり、それぞれ異なる用途に最適化されています。
Qwen3.7-Plusの仕組み
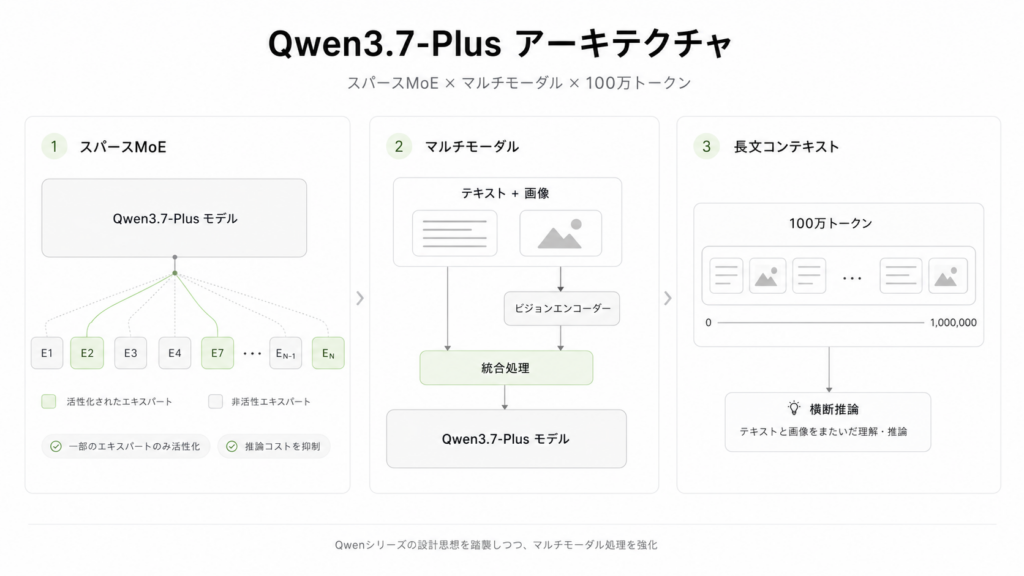
Qwen3.7-Plusのアーキテクチャは、Qwenシリーズ従来の設計思想を踏襲しつつ、マルチモーダル処理を強化したものとなっています。
基盤となるのはSparse Mixture-of-Experts(スパースMoE)アーキテクチャで、モデル全体のパラメータ数は非公開ながら、推論時にはその一部のエキスパートのみが活性化する仕組みです。これにより、巨大なモデルの知識を保持しながらも、推論コストを抑えた効率的な動作を実現しています。
マルチモーダル入力については、Qwen3-VLシリーズで培われた技術が活かされています。ビジョンエンコーダーがテキストと画像を統合的に処理し、100万トークンのコンテキストウィンドウ内でテキストと画像を横断した推論が可能です。


Qwen3.7-Plusの特徴
Qwen3.7-Plusの最大の強みは、視覚認識と言語推論の両方を高いレベルで両立している点にあります。
LM ArenaのVision Arenaでは世界第16位にランクインし、Alibabaはビジョン分野でラボランキング世界第5位に到達しました。
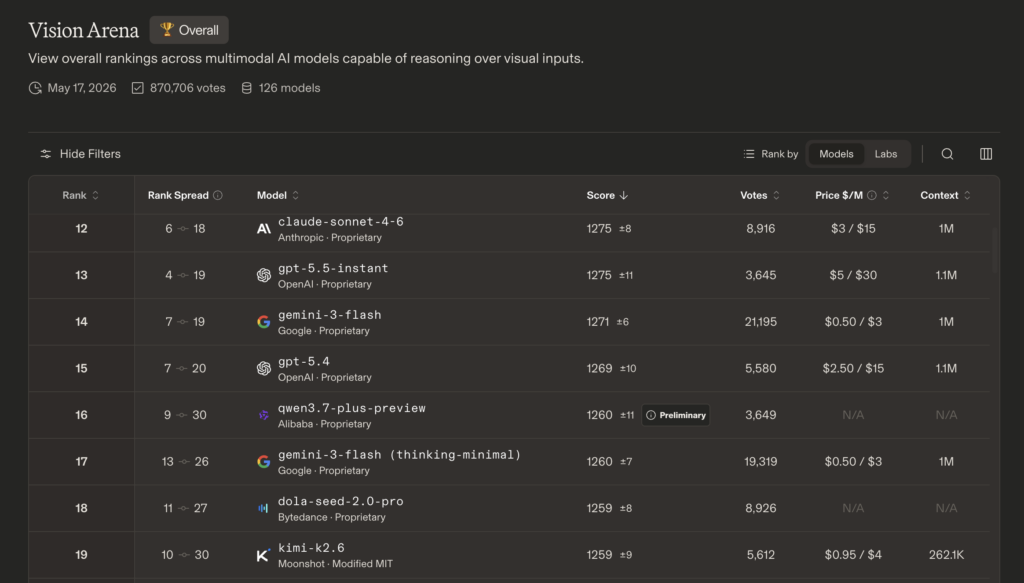
これは、画像理解の分野で長年リードしてきた欧米のAIラボを複数社上回った結果であり、中国発のモデルとしては過去最高水準のポジションです。
テキスト分野においても、兄弟モデルのQwen3.7-Maxが同時にLM ArenaのText Arenaで世界第13位(Elo 1,475)を記録しています。Maxは数学分野で第7位、エキスパートプロンプトで第9位、ソフトウェア/ITで第9位、コーディングで第10位という結果を残しており、Qwen3.7シリーズ全体の地力の高さがうかがえます。
Qwen3.7-Plusの安全性・制約
Qwen3.7-Plusを利用する際に把握しておきたい制約がいくつかあります。
まず、本モデルはクローズドウェイトのプロプライエタリモデルであり、モデルの重みをダウンロードして自社のGPUで動かすことはできません。利用はAlibaba Cloud Model StudioやQwen Studio(chat.qwen.ai)経由のAPIアクセスに限定されます。
データの取り扱いについては、APIリクエストがAlibaba Cloudのインフラを経由する点にも注意が必要です。
Qwen3.7-Plusの料金
Qwen3.7-PlusのAPI料金は、Alibaba Cloud Model Studio(DashScope)およびサードパーティプラットフォーム経由で利用可能です。Qwenシリーズはフロンティアモデルの中でもかなりコストパフォーマンスの高い価格帯を実現しており、同性能帯の欧米モデルと比較して大幅に安い料金でAPI呼び出しが可能です。
| モデル | 入力(100万トークンあたり) | 出力(100万トークンあたり) | キャッシュ入力 |
|---|---|---|---|
| Qwen3.7-Max | $2.50 | $7.50 | $0.25 |
| Qwen3.7-Plus(参考:前世代Qwen3.6-Plus相当) | $0.325〜$0.50 | $1.95〜$3.00 | ー |
| (参考)Claude Opus 4.8 | $15.00 | $75.00 | ー |
| (参考)GPT-5.5 | $5.00 | $30.00 | ー |
Qwen3.7-Plusのライセンス
Qwen3.7-Plusはプロプライエタリ(独自のクローズドライセンス)モデルであり、オープンウェイトでは提供されていません。商用利用はAPIを通じた範囲内で可能ですが、モデルの重み自体を改変・再配布するといった用途には対応していない点に注意が必要です。
| 利用形態 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 |  |
| 再配布 | |
| 特許利用 | |
| 私的利用 | |
Qwen3.7-Plusの使い方
Qwen3.7-Plusの利用方法はいくつかありますが、ここでは代表的な2つの方法をステップ・バイ・ステップで紹介します。
Qwen Studio(chat.qwen.ai)でチャット形式で使う
最も手軽にQwen3.7-Plusを試せるのが、Qwenチームが提供するWebチャットインターフェースです。
ブラウザで Qwen Studio にアクセスし、アカウントを作成してログインします。Googleアカウントやメールアドレスでのサインアップに対応しています。
チャット画面上部のモデル選択メニューから「Qwen3.7-Plus」を選択します。
テキストを入力するか、画像をアップロードしてプロンプトを送信します。画像を添付する場合は、チャット入力欄のクリップアイコンからファイルを選択できます。
Alibaba Cloud Model Studio(API)で使う
本番環境での導入やアプリケーション統合を想定する場合は、Alibaba Cloud Model StudioのAPIを利用します。
ダッシュボードからAPIキーを取得します。

OpenAI互換のAPIエンドポイントに対してリクエストを送信します。以下はPythonでの呼び出し例です。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
)
response = client.chat.completions.create(
model="qwen3.7-plus",
messages=[
{"role": "user", "content": "Qwen3.7-Plusの特徴を教えてください"}
]
)
print(response.choices[0].message.content)画像を含むリクエストを送る場合は、メッセージ内にbase64エンコードした画像データまたはURLを指定します。
【業界別】Qwen3.7-Plusの活用シーン
Qwen3.7-Plusはマルチモーダル対応の汎用モデルであり、さまざまな業界での導入が見込まれます。ここからは、特に活用が期待される業界別のユースケースを紹介します。
製造業・品質管理
製造業においては、製造ラインで撮影された製品画像をQwen3.7-Plusに入力し、外観不良の自動検知や品質基準との照合を行うことが考えられます。目視検査の負担を軽減しつつ、検査精度を一定水準に保てる可能性があり、特に多品種少量生産のラインで効果が見込めるでしょう。
製造業における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

不動産・建築
不動産業界においては、物件の写真や間取り図をアップロードして、物件情報の自動生成やレポート作成にQwen3.7-Plusを活用できます。マルチモーダル対応により、画像から読み取った情報をテキストに変換する作業を効率化できるため、不動産テック企業での導入価値が高い分野です。
不動産業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

教育・研究
教育業界においてQwen3.7-Plusは、論文中のグラフや数式の画像を入力として、内容の解説や要約を自動生成するといった活用方法が考えられます。100万トークンの長文コンテキストに対応しているため、長大な論文や教材を丸ごと処理できるのも強みといえるでしょう。
教育業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Qwen3.7-Plusが解決できること
マルチモーダル対応のQwen3.7-Plusは、従来テキストのみのLLMでは対応しきれなかった課題にもアプローチできます。ここからは課題別にQwen3.7-Plusが解決できることを確認していきましょう。
画像を含むドキュメントの処理自動化
請求書・領収書・契約書など、画像やPDFで届く書類の読み取りとデータ抽出を自動化することができるでしょう。OCR機能と言語理解を組み合わせることで、フォーマットの異なる多様な書類にも柔軟に対応できる点が強みです。
テキストLLMでは扱えなかったビジュアル分析
Qwen3.7-Plusを活用することで、グラフや表、設計図、UIモックアップなどの視覚的な情報を含むコンテンツの分析・レビューが可能になるでしょう。テキストだけでは文脈が伝わりにくい場面で、画像入力を組み合わせることで、より正確な指示出しや判断ができるようになるかと思います。
多言語・マルチモーダルの顧客対応
Qwenシリーズは中国語と英語のバイリンガル性能に強みを持っており、日本語を含む多言語での対応力も向上しています。例えば、スクリーンショットを添付した不具合報告などの画像付きの問い合わせに対して、視覚と言語の両面から回答を生成できるため、カスタマーサポートの高度化に貢献してくれるでしょう。
Qwen3.7-Plusを使ってみた
それでは実際にQwen3.7-PlusをQwen Studio経由で使ってみましょう。今回の検証では、画像を含むマルチモーダルタスクを中心にテストしていきます。
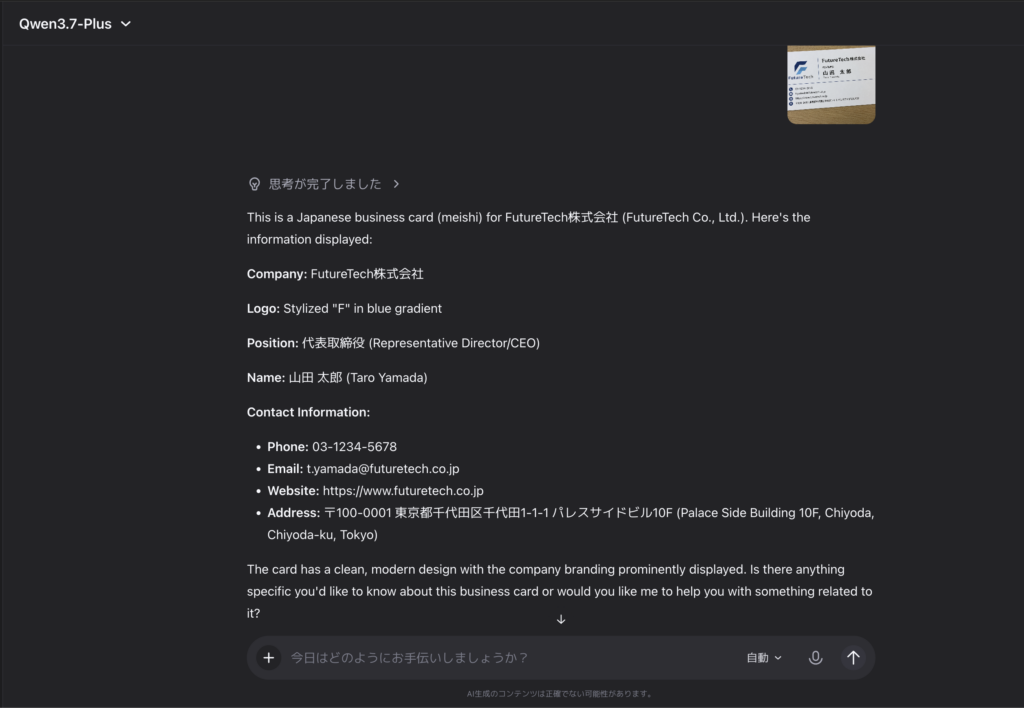
まず試したのは、日本語の名刺画像の読み取りです。架空の名刺をスマホで撮影してアップロードしたところ、氏名・会社名・役職・電話番号・メールアドレスといった情報を、ほぼ正確にテキスト化してくれました。
入力画像はこちら

結果はこちら
次に、売上データのグラフ画像を入力してみます。
プロンプトと入力画像はこちら
このグラフから読み取れるトレンドを分析してください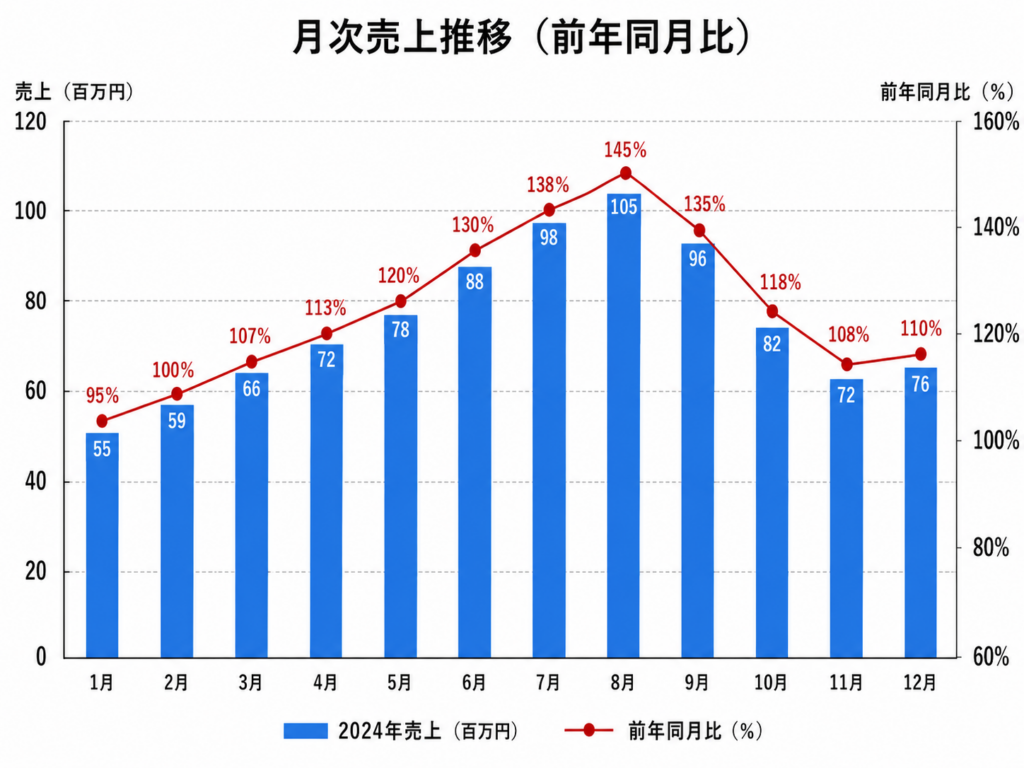
結果はこちら
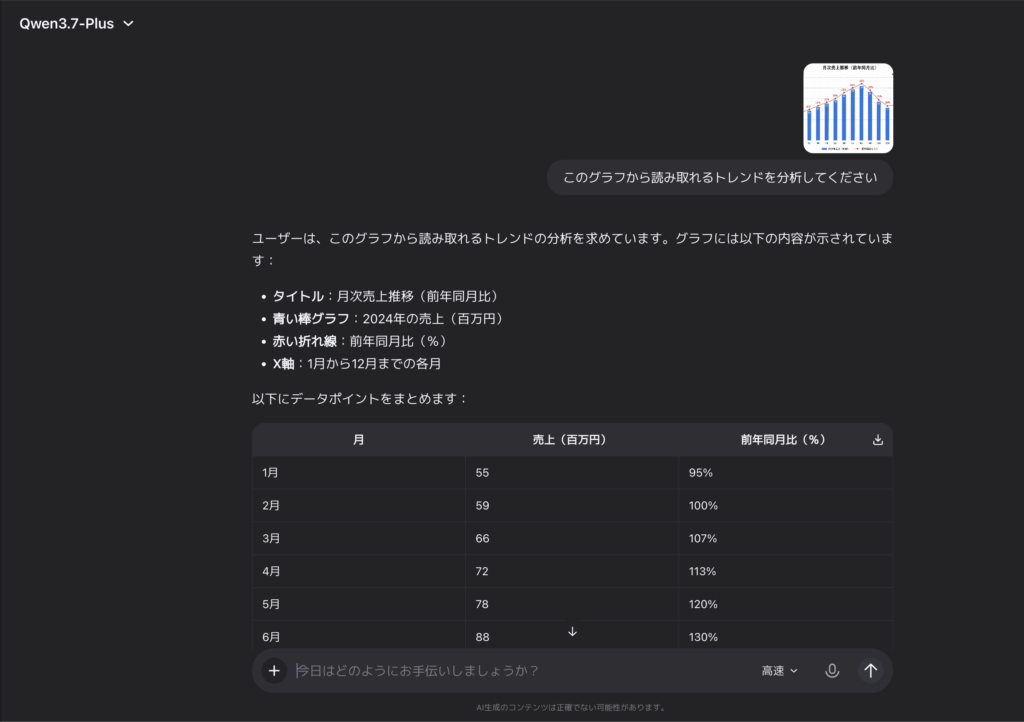

総じて、マルチモーダル対応のフロンティアモデルが、このコスト感で使えるという点では良いモデルだと感じました。画像入力が必要なワークフローを構築したい開発者にとって、非常に有力な選択肢になるのではないでしょうか。
よくある質問
最後に、Qwen3.7-Plusに関して、多くの方が疑問に感じるポイントをQ&A形式でまとめました。
Qwen3.7-PlusでマルチモーダルAIを使いこなそう!
Qwen3.7-Plusは、Alibaba Cloudが送り出したQwen3.7シリーズのマルチモーダルモデルであり、Vision Arenaでの世界トップクラスの性能を誇っている通り、画像理解と言語推論を高い次元で両立した実力派のAIです。
100万トークンのコンテキストウィンドウ、拡張思考モード、そしてフロンティアモデルの中でも圧倒的にリーズナブルな料金設定は、個人開発者から企業のAI導入担当者まで、幅広い層にとって魅力的な選択肢となるでしょう。
画像処理やマルチモーダルAIの導入を検討されている方は、まずはQwen Studioで無料で試してみてはいかがでしょうか。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

