

- Pandasは表形式データを直感的かつ高速に扱えるPythonデータ分析の中核ライブラリ
- Arrow対応やCopy-on-Writeなど、2.x以降で大きく進む性能改善と内部刷新
- 基本操作から実務事例・エラー対策まで、実践で使えるノウハウを体系的に習得可能
データ分析の世界では、「とりあえずPandas使って」という言葉をよく耳にする方も多いのではないでしょうか?
しかし、実際に手を動かそうとすると、SeriesとDataFrameなどの型の違い、インストール方法、バージョンごとの新機能など、細かな疑問が次々に湧いてくるものです。
そこで、この記事では、初学者〜中級者の読者がつまずきやすいポイントを一気に整理し、データ分析ですぐに活用できる情報をお届けします。
ぜひ最後までご覧ください。
- Pandasの概要、メリット、最新トレンドを体系的に理解
- コピペで動くコードで基本操作やよく使うメソッドを習得
- よくあるエラーや大規模処理のコツを把握
\生成AIを活用して業務プロセスを自動化/
Pandasとは?

Pandas(Python Data Analysis Library)とは、ラベル付き表形式データを、高速かつ直感的に操作・分析できるオープンソースのPythonライブラリのことです。
Pandasを学ぶ3つの理由
Pandasを学ぶための理由は大きく3つあります。
まず1点目が、Excelで行っていた集計・加工をわずか数行のコードに置き換えられる点です。例えば groupby と agg を使えば「部門×月別売上」のような多段集計を一瞬で再現することができます。
2点目に、scikit-learn や Matplotlib といった周辺エコシステムのハブになれることです。DataFrame をそのまま機械学習モデルに渡したり、可視化ライブラリへ連携したりと、前後工程をシームレスにつなげることができるのもPandasが選ばれる理由の1つです。
最後に3点目が、日本語記事・チュートリアル・Q&A が圧倒的に豊富であることです。Stack Overflow だけでなく Qiita や Zenn など国内コミュニティでも膨大なサンプルが蓄積されており、問題解決までの時間を最小化することができます。


Pandas最新動向
データ分析の基盤として長く使われてきたPandasですが、2024年に登場したpandas2.x系以降、Arrow対応やCopy-on-Writeなど、Pandas3.0にむけて内部構造そのものが刷新されつつあります。
これまで当たり前だった書き方や性能特性が変わり始めており、今後は実務のコードに直接影響するアップデートが予定されています。Pandas を日常的に使っている人ほど「どのバージョンで何が変わるのか」を把握しておくことが重要です。
Pandas 2.2(高速化と互換性強化)
Pandas2.2系は、Pandas3.0へとアップデートする大きな節目となりました。特に注目すべきは、Arrowバックエンドの正式サポートです。
従来のPythonオブジェクトベースの文字列カラムよりも圧倒的に軽く、CSV 読み込みや文字列操作の平均速度が約 1.8 倍向上するという実測結果が報告されており、ビッグデータ分析などでは特に効果を発揮しています。
さらに、Pandas2.2.2ではNumPy2.0との互換性が確保され、これまで頻発していた依存関係のエラーが大幅に減少しました。その影響で、機械学習や科学計算ライブラリとの組み合わせ運用も安定し、開発環境の構築がより簡単になりました
Pandas 2.3(機能の安定化とPandas3.0への準備)
Pandas2.3系は、Pandas3.0の仕様が実践的に形になり始めた重要なバージョンです。特に大きいのがStringDtypeの強化が挙げられます。
Pandas2.3のリリース後、3回のアップデートが行われていますがいずれも「StringDtypeの改善と修正」が含まれています。
大きなアップデートというよりは、2.2でリリースした機能の安定化をベースに次世代のPandas3.0に向けたプレビュー機能が含まれているバージョンでもあります。
Pandas 3.0(Arrowベースのstring dtypeへ)
Pandas3.0では、長年使われてきたPythonオブジェクト型ベースの文字列列ではなく、Arrowベースのstring dtypeがデフォルトになる予定です。
文字列列がArrowsベースになることにより、メモリ使用量が約40%削減されることが見込まれています。
これにより、大規模テキストデータの処理がより効率的になり、メモリ制約のある環境でも快適に分析作業を進められます。
また、Copy-on-Write動作が標準となることや非推奨APIの完全削除などが盛り込まれる予定です。
ユーザーにとってはPandas3.0へ移行すると、既存コードの一部修正が必要になる可能性がありますが、それを上回るパフォーマンスとメモリ効率の恩恵を受けることができるでしょう。
既存コードを更新する際は、非推奨警告に十分注意し、公式の移行ガイドを参照しながら作業を行うことをおすすめします。
Pandasのデータ構造
Pandasの基本単位は、1次元の Series と2次元の DataFrame です。
Seriesはラベル付き配列で、NumPyと同じベクトル演算APIを持ちます。
# Seriesの基本的な作成方法
s = pd.Series(data, index=index)DataFrameは行と列の両方にラベルを持つ表で、loc(ラベル指定)とiloc(整数位置指定)の2つのアクセス方法が用意されています。
# DataFrameの基本的な作成方法
df = pd.DataFrame(data, index=index, columns=columns)3次元データを扱う旧 Panel は非推奨となっており、現在は MultiIndex や xarray での管理が推奨されています。
最新バージョンでは、DataFrame内にリストや構造体を直接格納することができ、Arrowバックエンドが高速に処理します。
データ型としては、数値・文字列・カテゴリカル・ブール・日付時刻などがあり、category を用いたエンコードやArrow dtypeの活用でメモリ効率と検索速度を劇的に改善できます。
Pandasのインストールと環境構築
Pandasは、ローカル環境、クラウド環境、IDEなど様々な環境で実行できますが、今回は容易に試行できるGoogleColabを使っていきます。
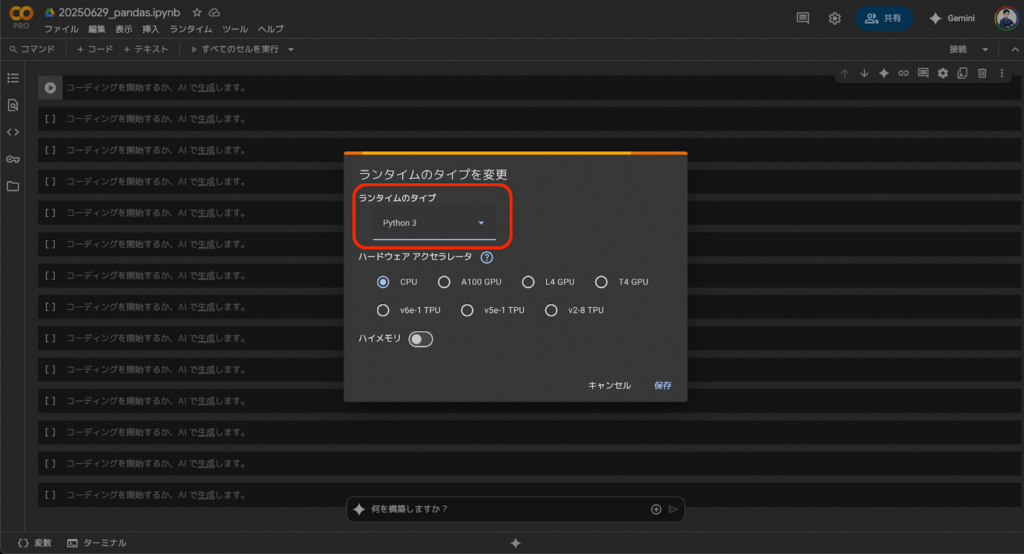
まずは、GoogleColabで新しいノートブックを作成し、「ランタイム>ランタイムのタイプを変更」でPython3を選択して保存ボタンを押して接続しましょう。
ハードウェアアクセラレータは、今回はデフォルトのCPUで問題ありません。
その後、以下のコードを実行して最新版を導入します。
# Colab はデフォルトで pandas が入っているがバージョンアップ
!pip install -q --upgrade pandas pyarrow
import pandas as pd, pyarrow
print(pd.__version__)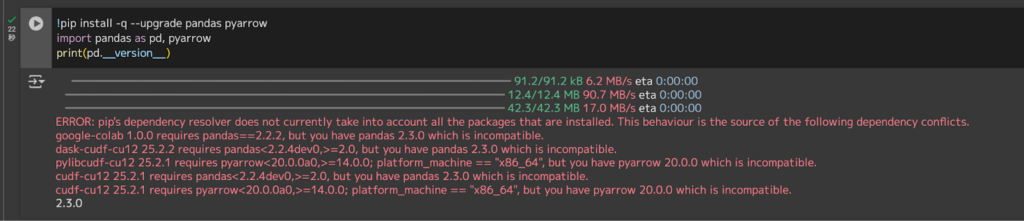
筆者環境ではバージョンの互換性で怒られていますが、以降の実装に影響はないのでスルーしていきます。
もし。Google Drive上のファイルを扱いたい場合は、下記のようにマウントします。CSVやExcelをDriveに置けば、そのままpd.read_csv() 等で読み込めます。
from google.colab import drive
drive.mount('/content/drive')また、GoogleColabのマシンは再起動すると環境がリセットされる点に注意してください。必要なライブラリのインストール手順をセルに残しておくと、次回以降ワンクリックで復元できます。


まずは触ってみる!基本操作チュートリアル
それでは実際にいくつかの基本操作を試していきましょう。
実装前にデータを準備する必要がありますが、今回はChatGPT-4oモデルでサンプル購買リストを生成します。
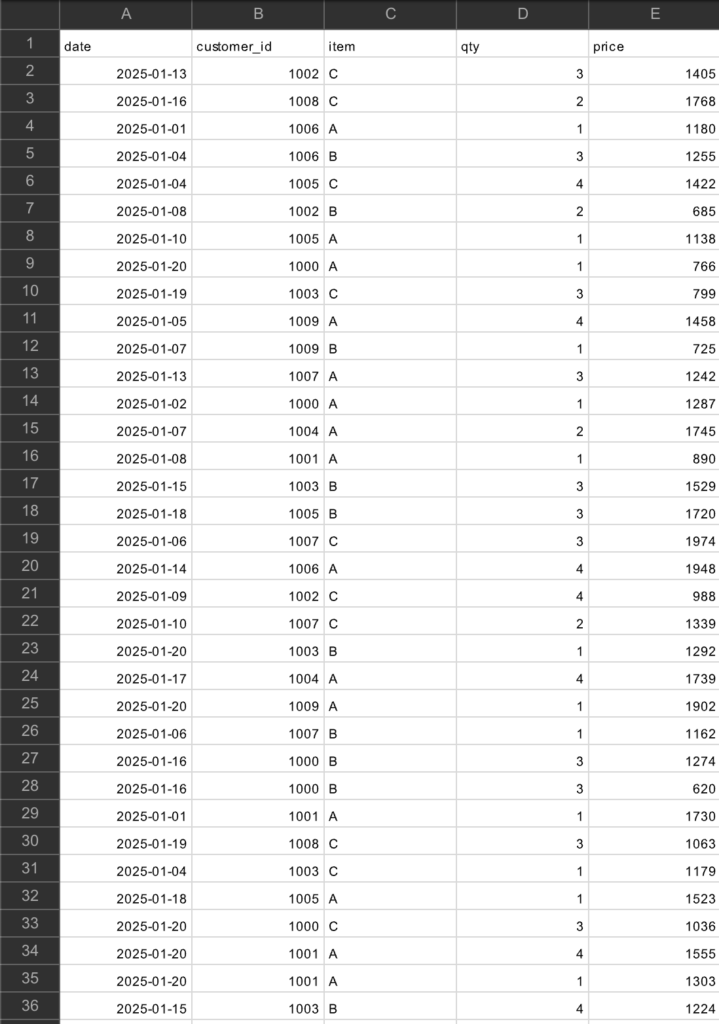
もし使いたいcsvデータがある場合はそちらをご使用ください。
なお、ChatGPT-4oについて気になる方は、以下の記事を参考にしてみてください。

データ加工テクニック
まずは、先ほど生成したcsvデータをGoogleColab上で読み込みます。
# 読み込み
sales = pd.read_csv('purchases.csv', parse_dates=['date'])# 先頭5行を表示
sales.head()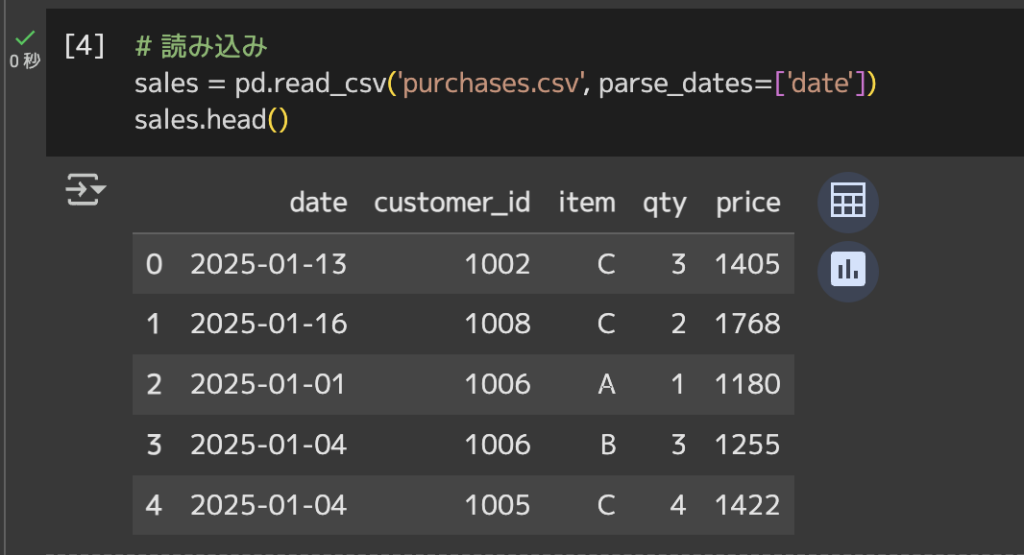
列・行の追加削除
追加・削除する前に比較できるように元データを確認しておきます。
# 行数カウントsales.count()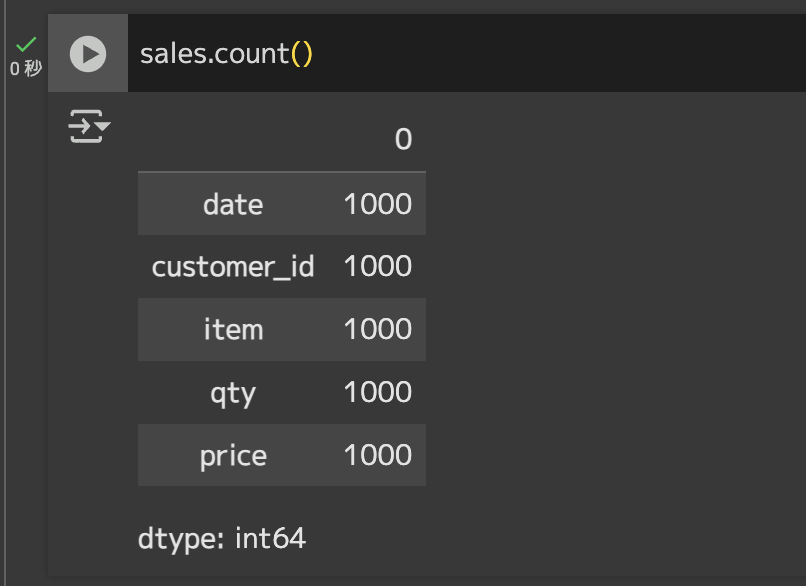
# カラム確認
sales.columns# 列追加
sales['yoy_dummy'] = 1 # 列確認 sales.columns 
yoy_dummy列が追加されていることが分かります。
# 列削除
sales.drop(columns=['yoy_dummy'], inplace=True)
先ほど追加したyoy_dummy列が削除されていることが分かります。
# 行作成
new_row = pd.Series(['N1', 'N2', 'N3', 'N4','N5'], index = sales.columns)
# 行追加
sales = pd.concat([sales, new_row.to_frame().T], ignore_index=True)
# 行数カウント
sales.count()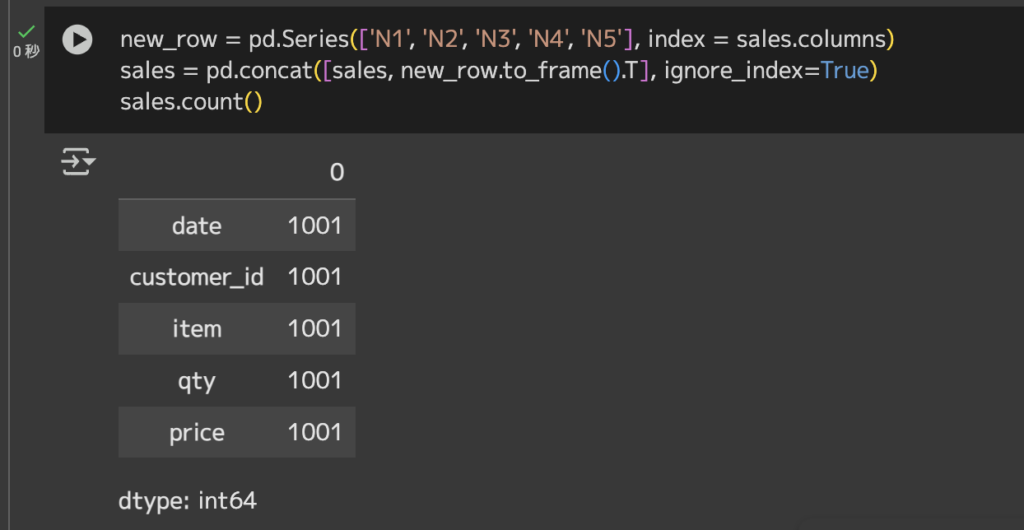
元の1,000行から1行増えていることが分かります。
# 最終行を削除
sales = sales.drop(sales.index[-1])# 行数カウントsales.count()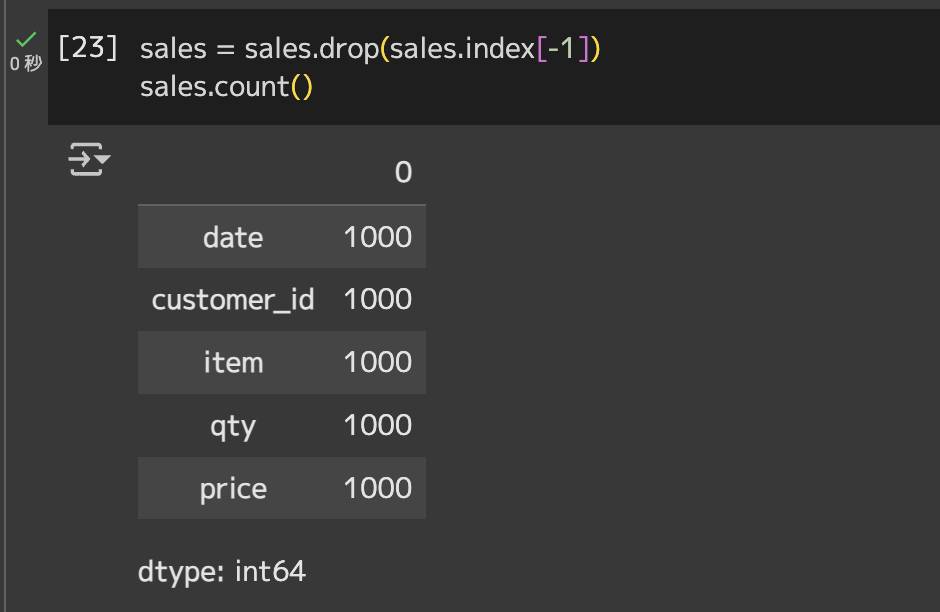
1,000行に戻っていることが分かります。
ソート
# ソートsales.sort_values(['customer_id', 'amount'], ascending=[True, False], inplace=True)# 上書きされたデータフレームを表示sales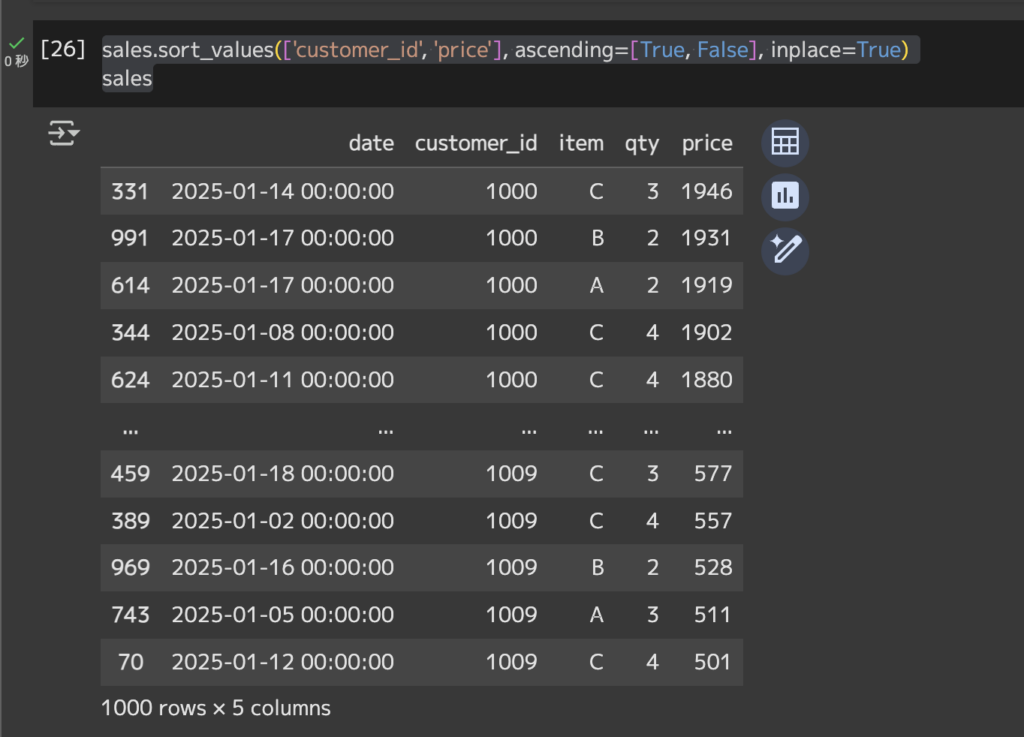
sales.sort_values(…)…salesデータフレームを特定の値で並び替えるメソッド。
[‘customer_id’, ‘price’]…並び替えの基準となる列を指定。customer_idを昇順でソートし、さらに同一のcustomer_id内でさらにpriceを降順でソート。
ascending=[True, False]…それぞれの列のソート順を指定。Trueが昇順でFalseが降順。
inplace=True…このソートをsalesデータフレーム自体に適用して結果を返さずに上書き。
欠損値処理
今回用意したデータに欠損値はありませんが、欠損値処理は以下のように行います。
# 数値をゼロ埋め
sales['amount'].fillna(0, inplace=True)
# itemが欠損している行を除外
sales.dropna(subset=['item'], inplace=True)結合・連結
結合用のサンプル顧客マスタをChatGPT-4oで生成します。
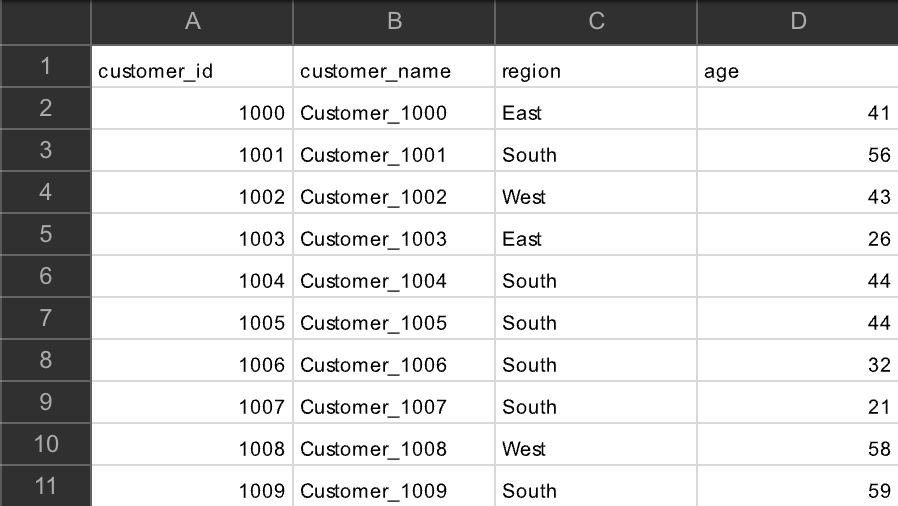
以下のようなコードで手動で作成してもOKです。
# 顧客マスタ生成
cust = pd.DataFrame({
'customer_id':[1000,1001,1002],
'pref':['Tokyo','Osaka','Nagoya']
})# サンプル顧客マスタcsvデータ読み込み
cus = pd.read_csv('customers.csv')
# 先頭5行表示
cus.head()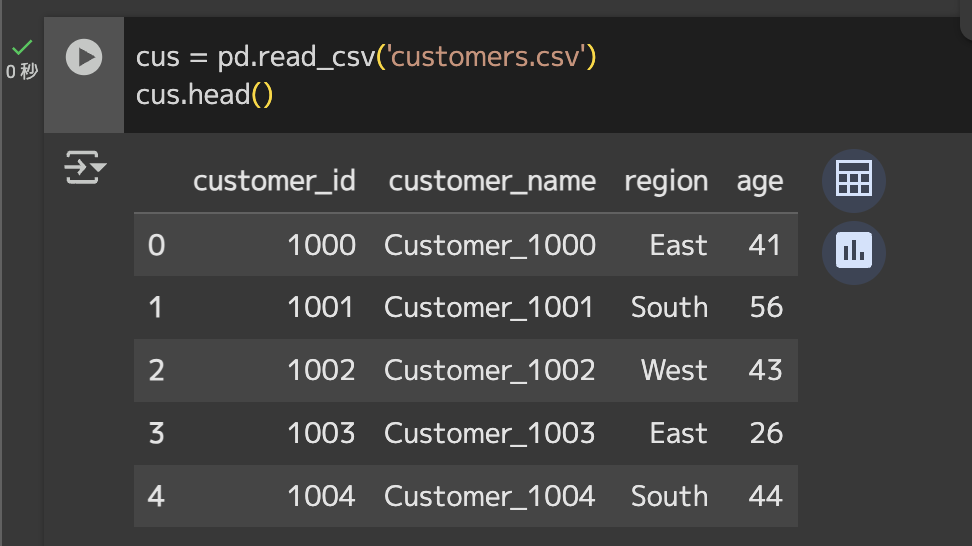
# 購買データに顧客マスタを結合
df = sales.merge(cus, on="customer_id", how="left")df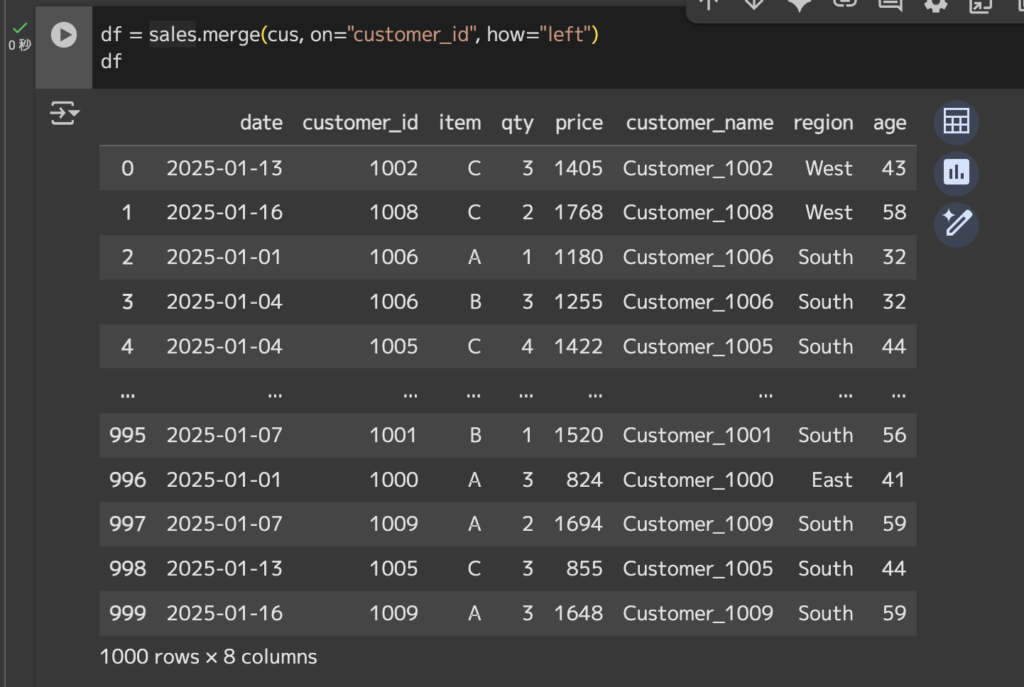
購買データをベースに、how=”left”(左結合)を指定しているため、購買データに存在しない顧客レコードは残りません。逆に顧客マスタにあって購買データにない行は集計対象外になるため注意してください。
集計・ピボット
結合後のdfから「地域ごとに売上金額」と「日別×商品別の売上金額」を集計します。
groupbyは行方向に集計軸を追加したいとき、pivot_tableはクロス集計したいときに使い分けると覚えやすいです。
# 金額列amountを作成(個数×金額)
df['amount'] = df['qty'] * df['price']
# データフレームのカラム確認
df.columns
# 地域ごとの総売上金額と平均購入単価
region_summary = (df
.groupby("region")
.agg(total_amount=("amount", "sum"),
avg_unit_price=("price", "mean"))
.reset_index())# region_summaryを表示
print(region_summary)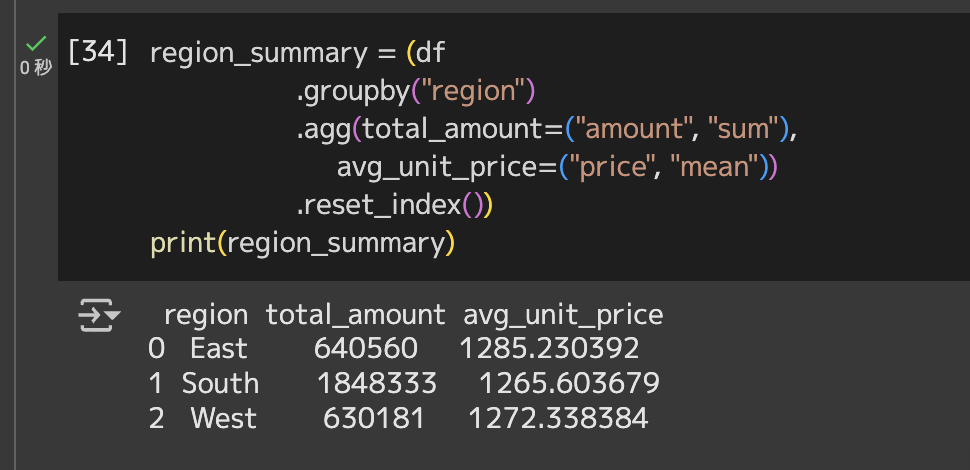
# 日×商品ごとのクロス集計
pivot_daily_item = (df
.pivot_table(index="date",
columns="item",
values="amount",
aggfunc="sum")
.fillna(0))
# pivot_daily_itemを表示
print(pivot_daily_item.head())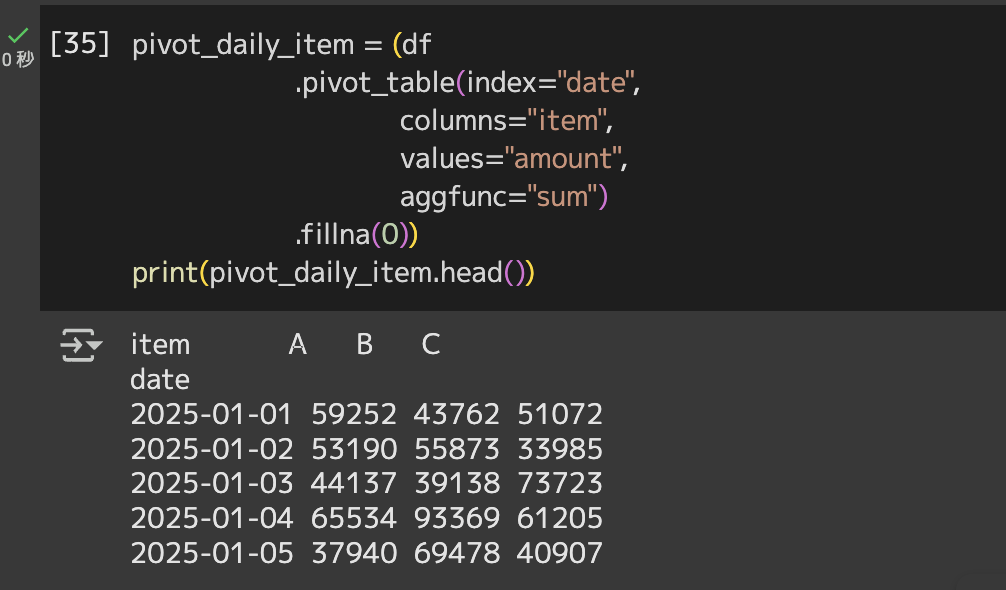
pivot_tableはExcelに近い感覚で使えます。
aggfunc=”sum”を”mean”に変えれば平均客単価を取得できますし、”count”に変えれば購入回数のヒートマップも作成できます。
様々な集計方法があるので、ご自身の分析/集計軸にあわせて試してみてください。
時系列
DatetimeIndexメソッドを使うことで、行インデックスそのものをカレンダーにできます。
今回は日次売上を月次売上に集約して、移動平均でトレンドをみてみましょう。
# インデックスを日付にセット
daily_sales = (df
.set_index("date")
.sort_index())
# 日次→月次へリサンプリング
monthly_sales = daily_sales.resample("M").sum(numeric_only=True)# monthly_salesを表示
print(monthly_sales[["amount"]].head())
# 7日間移動平均で売上トレンドを把握
daily_sales["amount_ma7"] = daily_sales["amount"].rolling(window=7).mean()
# 月次amountと7日間移動平均amountをプロットdaily_sales[["amount", "amount_ma7"]].plot(figsize=(12,4))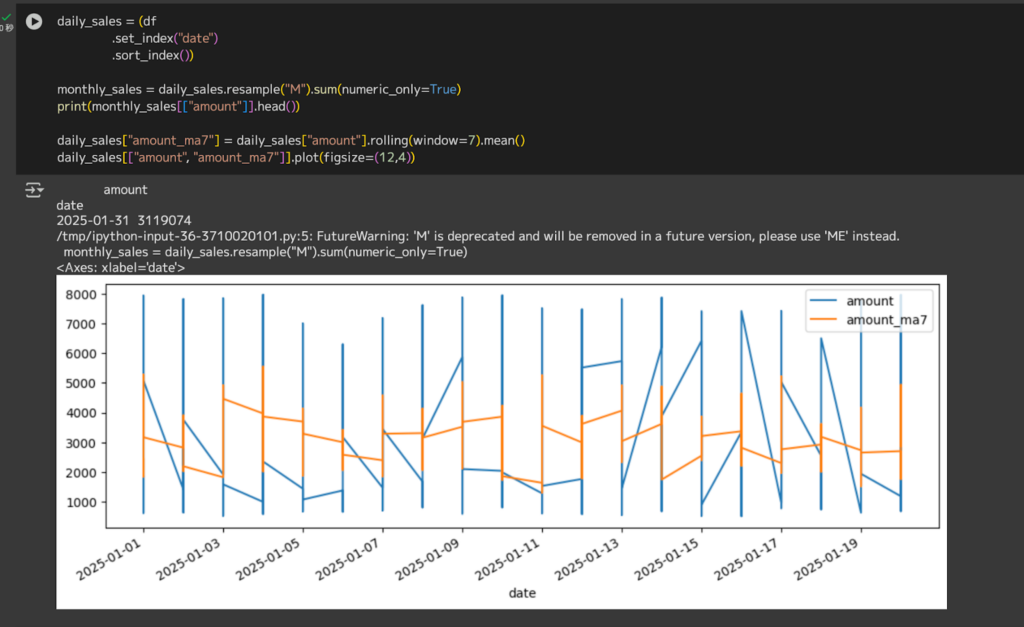
青線(amount)は日次売上額を示していて、1月上旬から中旬においては8,000前後のピークと500程度のボトムをジグザグと繰り返すような強い日次変動が確認できますね。
オレンジ線(amount_ma7)は7日間移動平均を示していて、急激な日次変動を平準化した滑らかなトレンドを描いてみました。序盤は5,000から3,000付近へ緩やかに下降して、その後3,000から4,000のレンジ内で横ばいないしは微増となっていますね。
また、resample(“M”)の結果として、2025-1月の総売上は3119074なので約311万円ということが分かります。日次平均だと約15万円ほどの売上規模ですね。
以上、いかがでしょうか?
Pandasライブラリならデータ分析や集計も非常にかんたんに実行することができるので、ぜひ本チュートリアルを参考にいろんなデータを分析してみてください。
実務でのPandas活用事例
ここからは実際のPandas活用事例を紹介します。
Netflix

映像配信大手Netflixのデータサイエンス部門では、新作タイトルが投入されるたびに数十万行規模の番組メタデータをPandasでクレンジングし、ジャンル・レーティング・国別比率などを自動チェックするワークフローを運用しています。
read_csvでAmazon S3からデータを取り込み、groupby→pivot_tableで集計、Matplotlibで可視化した結果を毎朝Slackに通知しています。運用前はExcelマクロで4時間以上かかっていた検証が15分に短縮されたようです。
データエンジニアは「SQL の再実行より Notebook のセル再実行が速い」とも語っており、BIツールに乗せる前の品質ゲートとして Pandasが定着しているのが分かりますね。
Uber
UberのMarketplace Optimizationチームは、Rides APIから得られる走行履歴・ピックアップ地点・天候情報を毎日5億行超取り込み、PandasとNumPyで需要ヒートマップを生成しています。
mergeで外部気象データを結合し、resample(“15min”)とrolling(window=4)で急激な乗車リクエストの立ち上がりを検出、異常値はquantile(0.995)で除外。結果は機械学習モデル(XGBoost)へ直接渡し、都市ごとに最適なサージ係数を15分間隔で更新しています。
実装後、ニューヨークではピーク時の乗車成立率が7%向上し、乗り手の待ち時間は平均90秒短縮されたそうです。
トヨタテクニカルデベロップメント
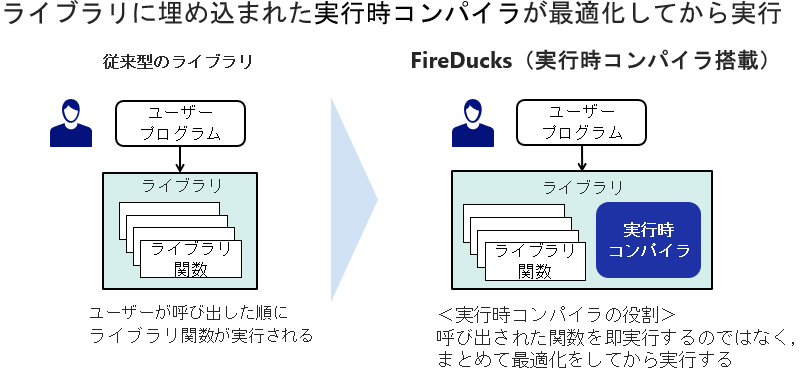
トヨタグループの開発会社TTDCでは、車両シミュレーションや実走試験で発生する数GBから数十GBのセンサーログをPandasで整形し、異常検知モデルに供給しています。
従来はシングルスレッド処理のボトルネックで、夜間バッチが終わらず分析待ちが常態化していたため、NECが開発したPandas API互換の高速化ライブラリ「FireDucks」を導入したところ、既存Notebook を書き換えずに並列化が実現し、前処理時間を平均6割削減したそうです。
よくあるエラーと回避策
こちらではよくあるエラーtop5とその回避策を紹介します。
SettingWithCopyWarning
フィルタ直後に列を代入した結果が元データに反映されない可能性を示す警告文です。
df.loc[…] = … の記述に統一し、pd.set_option(“mode.chained_assignment”, “raise”)で例外化することで早期検知しておくと安全です。
Out-Of-Memory(メモリ不足)
容量の大きいデータを丸ごと読み込むとRAMが枯渇してカーネルが落ちることがあります。
chunksizeで分割読み込みをして、dtype_backend=”pyarrow”や型変換するなどして列を軽量化しましょう。必要列だけをusecolsで指定したりするとさらに効果的です。
DtypeWarning(型が混在しているエラー)
数字と文字列が同じ列に混ざると自動推定が失敗し警告が出ます。
dtypeを辞書型で明示するか、読み込み後にpd.to_numeric(errors=”coerce”)で型を揃えて、欠損値をfillna()で補完できるとベストです。
ImportError(int64Indexなど互換性の衝突)
Pandas だけ最新版にして依存ライブラリが古い場合、「モジュールが見つからない」系の ImportError が頻発します。
仮想環境を作りpip install -U pandas numpy scipy matplotlib seaborn scikit-learnで一括更新するか、特定パッケージをアンインストールしてから再度インストールすると解決できます。
UnicodeDecodeError(文字化け)
日本語を含んだCSVをread_csvするとき、エンコーディング不一致でこのエラーが出ます。
Windoes由来のファイルはencoding=”cp932”、MacやLinux由来のファイルはencoding=”utf-8”を指定し、判別が出来ない場合はerrors=”replace”で読み込み、あとからdf.replace(‘\ufffd’, ‘’)などで欠落文字をクリーンアップすると復旧できます。
Pandas vs 他ライブラリ比較
NumPy
NumPy は固定型配列を高速計算する低レベル基盤で、DataFrameの背後でも利用されています。
行列演算やブロードキャストが中心の科学計算では処理が速いですが、ラベル管理や欠損値処理はPandasの方が圧倒的に簡単にできます。
Polars
PolarsはRust製の列指向エンジンでマルチスレッド実行が可能です。最新ベンチマークではPandasの10〜30倍速いケースも報告されており、大規模ETLやリアルタイム集計で威力を発揮します。
ただし、学習コストやエコシステムの成熟度合いでいうとPandasが優勢です。
PySpark DataFrame
PySparkはApache Sparkの分 DataFrame APIで、TB(テラバイト)級データをクラスタ横断で処理することができます。
レイテンシが高めでも水平スケールが必要なバッチ処理に強みがあり、Pandas API on Sparkを通じてPandasと似た書き方で利用することができます。
Pandasと他ライブラリの使い分けについて
Pandasと上記3つのライブラリについて、どのように使い分ければいいのか用途やデータサイズなどでまとめて表にしましたのでご参考ください。
| 得意な処理・強み | 主な用途・使い分けの目安 | |
|---|---|---|
| Pandas | ラベル管理、欠損値処理、時系列データ操作、豊富なエコシステム(可視化、ML連携)。探索的データ分析 (EDA) の標準。 | 数GBのテーブルデータ。単一マシンでのクイック分析やプロトタイピング。 |
| NumPy | 行列演算、ブロードキャスト、科学計算。均一な数値データの高速処理とメモリ効率。 | Pandasの計算基盤。画像処理、数値シミュレーション、線形代数。 |
| Polars | デフォルトでのマルチスレッド実行、Lazy評価によるクエリ最適化。Pandas比10〜30倍の高速集計・ETL。 | 数十GB〜数百GBのデータ。単一マシンでのパフォーマンスが要求されるタスク。 |
| PySpark DataFrame | 水平スケール、分散処理。TB級以上のビッグデータを複数のクラスタマシンで処理。 | 大規模バッチ処理、ログ解析。クラスタ環境でのデータ処理。 |
よくある質問(FAQ)
まとめ
Pandasは「Excelの置き換えツール」を超え、Pythonエコシステム全体をつなぐハブとして進化し続けています。
2.2系で、Arrowバックエンドが整備され、2.3系では安定化と3.0への準備、そして今後3.0では文字列型の完全Arrow化も予定されています。つまりは、コードの少なさ・情報量・互換性という3つの強みがそろった超有用ツールといえます。本記事のサンプルを動かしながら、ぜひPandasを学んでみてください。

最後に
いかがだったでしょうか?
Excel業務の自動化や、Python×生成AIによる分析パイプラインの内製化に取り組みたい企業様に向けて、最初の一歩となる開発支援をご提供しています。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

