

- Llamaindexは、社内文書やDBなどの独自データをLLMと連携させるための強力なオープンソースフレームワーク
- 単なるデータ検索にとどまらず、データ読み込みからエージェント型ワークフロー構築まで包括的にサポート
- API機能と組み合わせることで、高精度な社内文書検索や自律的なAIエージェントの開発が可能
みなさん、膨大な社内文書について「ChatGPTに質問できたらいいのに……」と思ったことはありませんか?
そこで朗報です。月間1,000万ダウンロードを超えるオープンソースフレームワーク・Llamaindexを使えば、ChatGPTに社内データや最新情報を参照して回答させられるんです!
当記事ではそんなLlamaindexの概要や、それを使った開発の手法・事例を紹介していきます。最後まで読んでいただくと、社内用チャットボットの開発のハードルが下がるはずです。ぜひLlamaindexの底力をご覧ください。
\生成AIを活用して業務プロセスを自動化/
Llamaindexとは
Llamaindexは、自社のデータとLLM(大規模言語モデル)をつなぎ合わせるためのオープンソースフレームワークです。Python向けのライブラリとして広く使われており、RAG(検索拡張生成)や社内文書検索のプロトタイプをPythonで手軽に作り始められる点が大きな魅力といえます。
もともとはデータの出し入れに特化したツールでしたが、開発が進むにつれて役割も変化してきました。今ではデータの取り込みや検索機能にとどまらず、自律的に動くエージェント機能(Workflows)まで備えた「AIエージェント構築フレームワーク」へと進化しています。
実際に業務で使うシステムを組む際は、Pineconeなどのベクターストアや外部APIとの連携をセットで設計していくのが一般的なアプローチです。Llamaindex自体は生成AIやLLMではなく、あくまで開発用のフレームワークです。ChatGPTなどのLLM(大規模言語モデル)と組み合わせて使うことで、初めてその真価を発揮します。LLMが本来持っていない最新の知識や自社独自の事実を、Llamaindexが検索して補ってくれるのです。
Llamaindexについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Llamaindexにできること
Llamaindexを使ってできることは主に以下の領域に整理されます。
- データコネクタによる多様なデータソースの取り込み
- 高度な検索とインデックス作成
- エージェント型ワークフローの構築
これらLlamaindexの機能が具体的にどのようにすごいのか、LLMとどのように噛み合うのかを以下で見ていきましょう!
さまざまなデータを読み込み、インデックス化して扱える
LlamaIndexでは、さまざまな形式のデータを読み込み、インデックス化して扱えます。データベースの定番SQLはもちろん、テキスト・PDF・CSV、そしてなんとAPIのデータまで扱えるのです。
さらに、データのインデックス化(検索用に整理して保存すること)において、Llamaindexは用途に応じた複数の手法を提供しています。
| 手法 | 説明 |
|---|---|
| VectorStoreIndex(ベクターストア) | 文章を意味の近いもの同士が近くに配置される「ベクトル」という数値データに変換して保存する方式。Googleなどの検索エンジンにも採用されている考え方です。 |
| SummaryIndex(旧リスト) | 文書全体をそのまま保持し、要約を生成する際などに適した方式。 |
| KnowledgeGraphIndex | データ間の関係性をネットワーク状に整理して保存する方式。この中でも、RAG(検索拡張生成)の構築において中心となるのはVectorStoreIndexです。 |
現在の主流であり、LLMとの連携時に最もよく使われるのが「VectorStoreIndex(ベクターストア)」です。
類似度検索ができる
Llamaindexのベクターストアは、データを取りだす際の利便性にも優れています。
各データをベクトルで表現していて、その方向性が近い、つまり似ているもの同士を近くに集めているのがベクターストアの特徴です。これを備えたLlamaindexはクエリを渡すと、類似度検索を行って関連性の高いデータだけを瞬時に返してくれます。
この長所はLLMとの連携時に活きてきます。最新情報や事実のうち関連性の高いものだけをベクターストアから取り出して、テキスト断片やメタデータとしてプロンプトの文脈に埋め込めるのです。
LlamaindexはOllamaと組み合わせて開発できる
Llamaindexは、ローカル環境でLLMを動かすためのツール「Ollama」と強力に連携できます。Pythonコード上でOllamaのモデルを指定するだけで、外部APIにデータを送信することなく、機密性の高い社内文書を安全に処理するRAGシステムを構築可能です。
クラウドのAPI費用を抑えつつ、オンプレミスでのセキュアなAI開発を実現したい企業にとって、この組み合わせは非常に有効です。
LlamaindexはRAG開発に向いている
Llamaindexは、データの取り込みから検索、LLMへのコンテキスト提供までの一連の流れ(RAGパイプライン)を構築することに特化して設計されています。特に、複雑なドキュメントのチャンク化(分割)やメタデータの付与、ベクトル検索の最適化など、RAGの精度を高めるための機能が豊富に揃っています。そのため、社内規定やマニュアルなどの大量の文書をベースにしたQ&Aシステムを開発する用途において、無類の強さを発揮します。


Llamaindexを使った開発の流れ
ここからはLlamaindexとLLMを使って、社内用のAIツールを開発する際の流れを紹介します。まずは下記、開発進行の順序をご覧ください。
- 学習元データ or データソースの準備
- 学習元データの整形
- ベクターストアの構築
- LLMとの連携・検証
以降の見出しでは、より詳しい作業内容をお伝えします。開発に何が必要か、どのような注意点があるのかなどをみていきましょう!
学習元データ or データソースの準備
LlamaindexとLLMを繋ぐよりも前に、データの準備が最優先です。自社のシステム・サービス・文書など、プロンプトに埋め込みたいデータを用意しましょう。
まず下記の形式にあてはまるデータであれば、そのままLlamaindexに格納ができます。
- テキスト(.txt)
- ドキュメント(.docx)
- CSV
- SQL
さらに自社で運用しているX(Twitter)やSlackの内容は、API経由でLlamaindexへの取り込みが可能です。またランディングページやメールなどHTML形式のデータも、次に紹介する整形を行えばLlamaindexで使えます。
学習元データの整形
Llamaindexにおけるデータ整形(Ingestion)は、精度の高いRAGを構築するための重要なプロセスです。公式のパイプライン(IngestionPipeline)では、以下の3段階で処理が行われます。
| 段階 | 内容 | 説明 |
|---|---|---|
| 1 | Load(読み込み) | 各種データソースからドキュメントを取得します。 |
| 2 | Transform(変換) | ドキュメントを適切なサイズのノードに分割(Chunking)し、メタデータの抽出(Metadata Extraction)やベクトル化(Embedding)を行います。 |
| 3 | Index and store(インデックス化と保存) | 処理されたノードをベクターストアに格納します。 |
特にTransformの工程では、重複検知や更新時の再処理(Upsert)など、実運用を見据えたドキュメント管理機能も備わっています。
ベクターストアの構築
データの準備・整形が終わり次第、Llamaindexのベクターストアにデータを格納していきます。
方法自体は簡単で、数行のPythonコードを実行するだけでベクターストアの構築が完了します。格納先についてはLlamaindex純正のベクターストアのほか、下記のような外部のベクトルデータベースも選択可能です。
- Pinecone:処理精度が高く、数十億のベクトルを10ミリ秒で検索できる
- Weaviate:オープンソースの検索エンジンで、自分でホストできる
- Chroma:オンラインメモリでも使える
このあたりは用途に応じて、使い分けるとよいでしょう。
LLMとの連携・検証
最後にLlamaindexとLLMを、API経由で連携させます。
このときに注意していただきたいのはLLM本体のAPI以外に、埋め込み用のAPIも要るという点です。埋め込み用のAPIを使うことで、トークンの消費が抑えられます。
OpenAIのモデルを利用して開発する場合、以下のAPIが必要になりやすいです。
| API | 用途 |
|---|---|
| Responses APIまたはChat Completions API | プロンプトを送受信し、回答を生成する際に使う(新規開発ではより柔軟なResponses APIが推奨されています) |
| Embeddings API | データをベクトルとして埋め込む際に使う |
連携体制が完成し次第、検証も行います。データベースの内容をLLMに回答させて、正誤判定を行うことでLlamaindexの動作を確認します。
Llamaindexを使った開発の費用相場
弊社ではLlamaindex搭載型AIツールの開発にあたって、プロトタイプ開発とソリューション開発の2プランを用意しております。それぞれの費用相場や開発期間については、下表をご覧ください。
| プロトタイプ開発 | ソリューション開発 | |
|---|---|---|
| 費用相場(総額) | 3,600,000 ~ 4,800,000 円 | 個別お見積 |
| 期間 | 3ヶ月 | 4ヶ月 ~ |
| 開発手法 | ウォーターフォール方式 | ハイブリッド方式 (設計&検証はウォーターフォール方式で、各機能の開発はアジャイル方式) |
| 開発できるもの | 既存の基盤モデルを使った、社内向けAIツール | 基盤モデルまで特注の、社外向けAIサービス |
| 内容 | ・学習元データクレンジング ・自社データを学習したチャットボット開発 ・AIと自社システムの連携 ・業務のAI化 | ・AI基盤開発 ・Web開発 ・ネイティブアプリ開発 ・クラウドインフラ開発 |
この2プランのうち、おすすめはローコスト・短期間で取り組めるプロトタイプ開発です。まずは社内業務のAI化・DXからお試しください。
開発費用を抑える方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。



Llamaindexで開発できるもの
Llamaindexを使えば、自社のデータとAIを連携させた実用的なアプリを手軽に作れます。業務の効率化やサポート対応の改善に役立つ、代表的な5つの開発例を見ていきましょう。
社内文書検索
PDFやWord、社内Wikiなど、あちこちに散らばっているデータをLlamaIndexに読み込ませることで、自然言語で横断的に検索できる仕組みを構築できます。従来のようにフォルダを一つひとつ開いて探す必要がなくなり、「〇〇の手順を教えて」といった曖昧な質問にも対応可能です。
また、検索結果には該当箇所の要約や参照元リンクを含めることができるため、情報の信頼性も担保できます。これにより、ナレッジの属人化を防ぎつつ、業務効率を大幅に向上させることが期待できます。
社内文書検索を生成AIで実現する方法について、詳しく知りたい方は、以下の記事もご確認ください。

検索基盤
大量の製品マニュアルや過去の問い合わせ対応履歴、FAQなどをあらかじめベクトル化しておくことで、カスタマーサポート向けの高度な検索基盤を構築できます。従来のキーワード検索では見つけにくかった情報でも、ユーザーの質問内容に含まれる文脈や意味をもとに、関連性の高い情報を柔軟に抽出できる点が特徴です。
また、検索結果をそのまま回答生成に活用することで、オペレーターの対応時間短縮や回答品質の均一化にもつながります。結果として、顧客満足度の向上と業務効率化の両立が期待できます。
生成AIをカスタマーサポートとして活用する方法について、詳しく知りたい方は、以下の記事のご確認ください。

文書QA
読み込ませた契約書やマニュアル、社内規程などのドキュメントに対して、「この契約書の解約条件は?」といった自然な質問を投げるだけで、該当箇所を引用しながら回答するQAアプリケーションを構築できます。単に該当箇所を検索するだけでなく、内容を要約した上で分かりやすく提示できる点も特徴です。
また、参照元の明示により情報の信頼性を担保できるため、法務やカスタマーサポートなど正確性が求められる業務にも適しています。即座に検索できるため、情報確認にかかる時間を大幅に削減し、業務効率の向上が期待できます。
社内ヘルプデスクでの生成AI活用は下記で解説

複数のドキュメントを読み込ませてまとめることができるNotebookLMについて、以下の記事でまとめています。詳しく知りたい方は、併せてご確認ください。

SQL連携
LlamaIndexのText-to-SQL機能を活用することで、「先月の売上トップ商品は?」といった自然言語の質問を入力するだけで、裏側で自動的にSQLクエリを生成し、データベースから必要な情報を取得する仕組みを構築できます。
この機能により、SQLの知識がない非エンジニアでもデータを簡単に活用できるようになります。また、複雑な条件指定や集計処理にも柔軟に対応できるため、分析業務の効率化や意思決定の迅速化にもつながります。結果として、データ活用のハードルを下げ、組織全体の生産性向上が期待できます。
LLMとデータベースをつなぐことが出来るMindsDBについて、詳しく知りたい方は、以下の記事も併せてご確認ください。

エージェント型ワークフロー
複数のデータソース(社内ドキュメントやデータベース、外部APIなど)を横断して情報を取得し、その結果をもとに次のアクションを自動で実行するAIエージェントを構築できます。例えば、問い合わせ内容に応じて関連情報を検索し、必要に応じて社内システムへの登録や通知処理までを一貫して行うことが可能です。
近年のLlamaIndexは、このような一連の処理を柔軟に設計できるワークフロー機能が強化されており、業務プロセスの自動化や高度化を実現しやすくなっています。自動化することで、人手に依存していた複雑な業務の効率化と省力化が期待できます。
AIエージェントで性能が優れているManusについて、詳しく知りたい方は、以下の記事も併せてご確認ください。

Llamaindexと同じようにローカルで動作するAIコーディングツールについて、以下の記事で解説しています。気になる方は、併せてご確認ください。

Llamaindexの開発事例4選
ここからはLlamaindexを使ったAIツールの開発事例を紹介していきます。ChatGPTと組み合わせたチャットボットではあるものの、それぞれ工夫したポイントや開発のねらいが違います。ですので以下を読めば、社内用チャットボット開発のヒントが得られるはずです。
自社サービスのQ&Aツール
GMOのグループ研究開発本部はLlamaindexとChatGPTを使って、自社のVPSサービスConohaのAPIについて答えてくれるQ&Aツールを開発しています。※1
その処理フローは以下のとおりです。
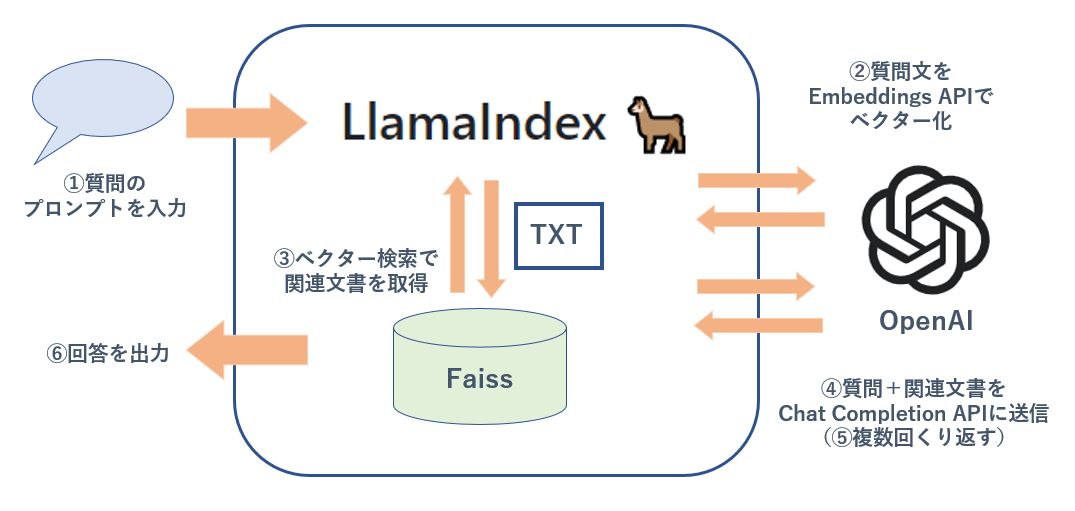
上記の図で注目していただきたいのがLlamaindexの下部、Facebook(現Meta)製のベクトルデータベース「Faiss」の箇所です。Llamaindexに備え付けのベクターストアの代わりにFaissを使うことで、データベースの容量を1/3に抑えています。
ブログのQ&Aチャットボット
Llamaindexを使えば、ChatGPTにブログの内容を答えさせることもできます。以下に示すのは、株式会社システムサーバーが開発したブログのQ&Aチャットボットの処理フローです。※2
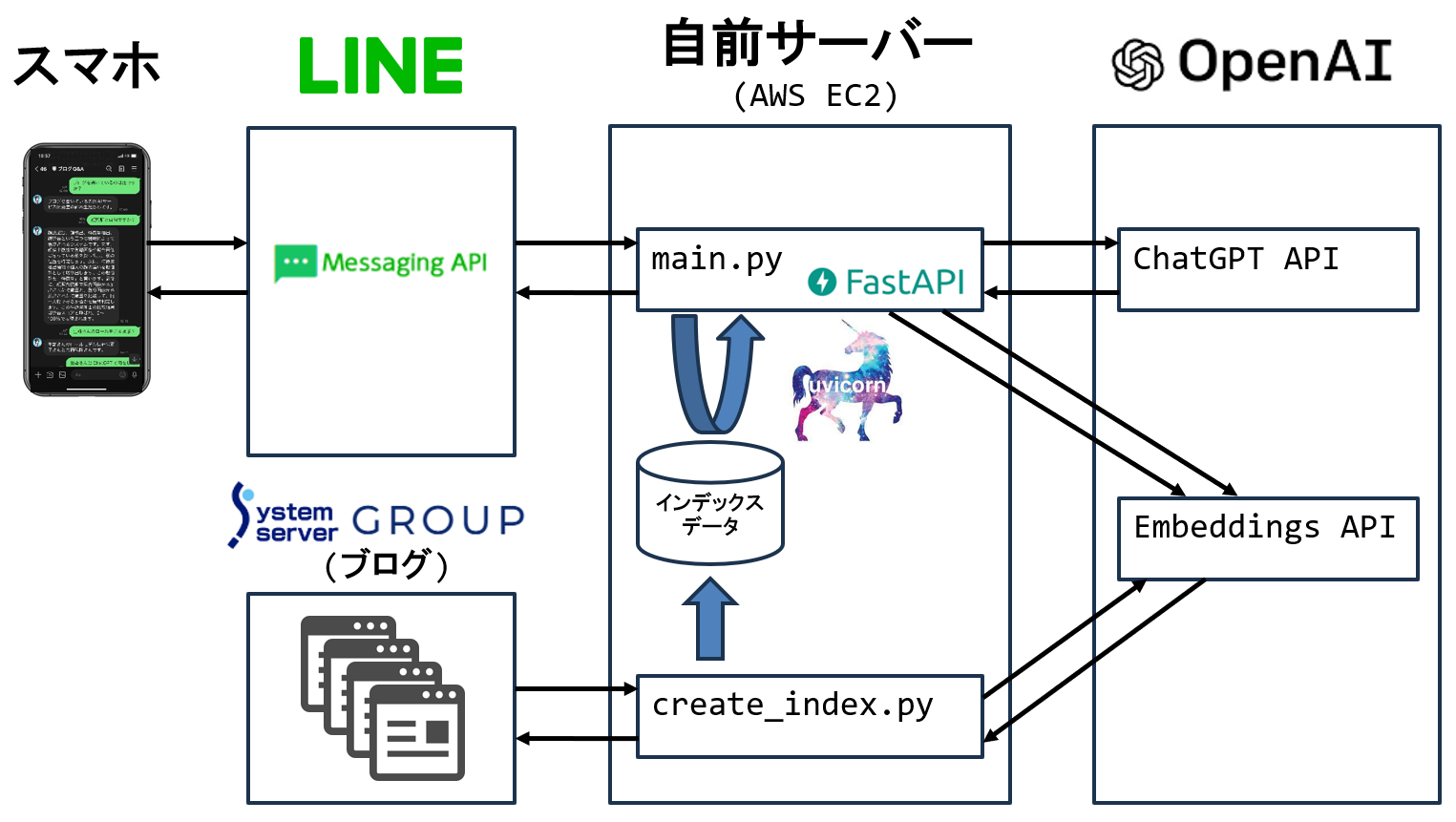
このようにMessaging APIを採用したことで、LINEのトークルーム上での質疑応答を実現しています。ドメイン登録などMessaging APIを使うための準備に手間がかかったそうですが、それでも1時間程度で開発が完了したとのことです。
取扱説明書の質問ボット
Web制作を請け負っている株式会社GIGでも、試験的にLlamaindex搭載型のチャットボットを開発しています。LlamaindexにTANITAの体重計の説明書PDFを格納したのち、独自の機能「乗るピタ」について連携先のChatGPTに質問しています。見事に正しい説明と補足が得られていました。※3
株式会社GIGの事例のようにLlamaindexとChatGPTを組み合わせれば、コンテンツの制作時に必要な専門知識へ一瞬でアクセスができるはずです。
AIチャットボットについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

社内問い合わせ対応の自動化
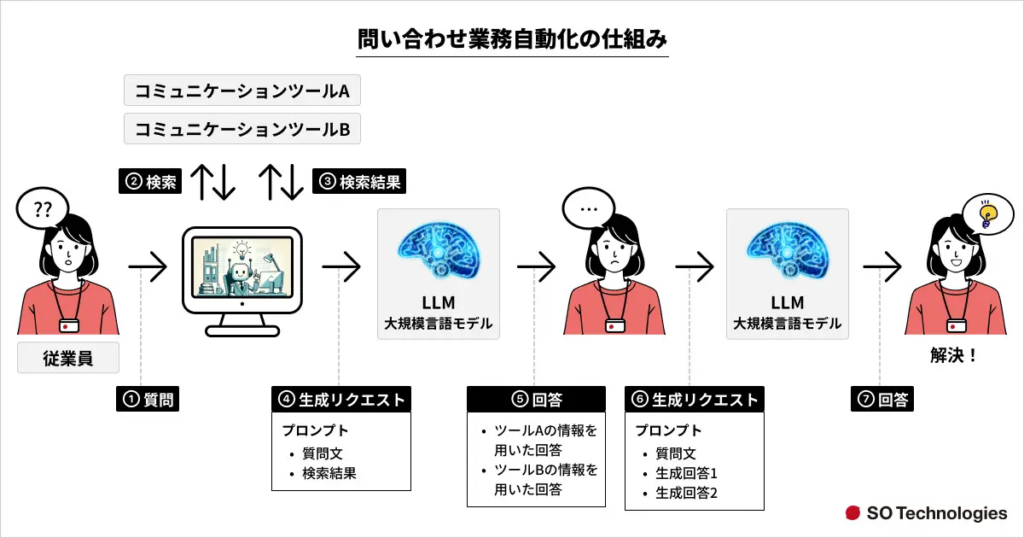
SO Technologies株式会社では、ChatGPT(GPT-4o)とLlamaindexを活用し、契約・取引、受発注、経理、総務などの社内問い合わせ対応を自動化する事業支援AIチャットボットを開発しました。
正確な事実が蓄積されたNotionと、流動的な情報が多いSlackから関連情報を取得し、精度の高い回答を生成する仕組みを構築することで、業務工数の削減を実現しています。
Llamaindexのよくある質問
Llamaindexなら高精度なチャットボットが開発できる
当記事ではLLMの弱点が補えるPythonのライブラリ・Llamaindexについて解説してきました。もう一度、Llamaindexにできることを以下に示します。
- さまざまなデータと連携して、自身に格納できる
- 類似度検索ができる
このような強みをもつLlamaindexを使えば、API経由でLLMに最新情報や事実が示せます。専門知識や社外秘について回答できるチャットボットを開発したい場合は、Llamaindexがおすすめです。
ちなみに弊社でもその開発を請け負っております。チャットボットを導入してみたいということであればぜひ、無料相談をお試しください。

最後に
いかがだったでしょうか?
Llamaindexを活用したRAG開発は、単なるチャットボット導入ではなく「社内ナレッジをどう活かすか」が重要になります。検索精度やベクターストア設計、運用コストまで含めて最適化することで、実務で使える生成AI基盤へと進化させることが可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

【監修者】田村 洋樹
株式会社WEELの代表取締役として、AI導入支援や生成AIを活用した業務改革を中心に、アドバイザリー・プロジェクトマネジメント・講演活動など多面的な立場で企業を支援している。
これまでに累計25社以上のAIアドバイザリーを担当し、企業向けセミナーや大学講義を通じて、のべ10,000人を超える受講者に対して実践的な知見を提供。上場企業や国立大学などでの登壇実績も多く、日本HP主催「HP Future Ready AI Conference 2024」や、インテル主催「Intel Connection Japan 2024」など、業界を代表するカンファレンスにも登壇している。

