

- NVIDIA CUDAはGPUの並列計算能力を引き出すための計算基盤エコシステム
- CPUが制御 GPUが大量計算を担う役割分担とスレッド ブロック グリッド構造
- 生成AI開発ではPyTorchやTensorFlowを通じた事実上の業界標準
生成AIの開発やシミュレーションなどの現場において、処理が重くて作業がなかなか進まずに困っている方は多いのではないでしょうか?
そんな時は、NVIDIAがGPUの並列処理向上を目的に開発した「NVIDIA CUDA」の出番です。
今回は、NVIDIA CUDAの概要や活用シーンについて詳しく解説していきます。
最後まで目を通していただくと、NVIDIA CUDAについての理解が深まり、生成AI開発などの分野で生産性の向上が見込めます。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
NVIDIAとは
NVIDIAとは、アメリカ・カリフォルニア州に本社を置く半導体メーカーです。1993年に設立され、今ではGPUの開発で世界的な知名度を有しています。
個人が使用するパソコン用のGPUを開発しているのはもちろん、企業のデータセンター向けに大規模なGPUを提供しているのも特徴。
NVIDIA CUDAのほかに、自動運転プラットフォームの「NVIDIA DRIVE」も運営するなど、生成AI分野にもかなり力を入れています。
AI時代を支えるGPUコンピューティングプラットフォーム
NVIDIA CUDAは、単なる技術仕様を超えて、現代のAI革命を支える「エコシステム」として機能しています。
2006年の登場以降、NVIDIA CUDAは科学技術計算の分野で着実に実績を積み重ねてきましたが、2015年頃からのディープラーニングブームを機に、その重要性は飛躍的に高まりました。
ディープラーニングの本質は「大量の行列演算」です。ニューラルネットワークの学習では、何百万ものパラメータを同時に更新する必要があり、この処理はまさにGPUの並列計算能力が最も活きる領域。NVIDIA CUDAは、この膨大な計算を効率的に処理するための「土台」として、PyTorch、TensorFlow、JAXといった主要なAIフレームワークすべてに採用されています。
実際、現在のAI開発現場において、NVIDIA CUDAなしでの大規模モデル訓練は難しいです。ChatGPTやStable Diffusionなどの生成AIモデルも、その学習プロセスでNVIDIA CUDA対応GPUを大量に使用しており、AI時代の進展はNVIDIA CUDAの進化と密接に結びついています。
なお、NVIDIAのAI基盤モデル「Cosmos」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

NVIDIA CUDAでできること・主なメリット
NVIDIA CUDAを活用することで、開発者や研究者は従来のCPU単体では到達できなかったレベルの計算性能を引き出せます。ここでは、NVIDIA CUDAがもたらすメリットを解説します。
CPU単体と比べた圧倒的な高速化
NVIDIA CUDAの最大のメリットは、CPU単体と比較して数十倍から数百倍以上の処理速度向上を実現できる点です。
特にディープラーニングの学習では、GPUがCPUに比べて10倍以上高速に動作するケースが多く、画像認識モデルのトレーニングでは数日かかっていた処理が数時間で完了することも珍しくありません。
この劇的な高速化は、GPUの並列処理アーキテクチャによって実現されています。CPUが数個から数十個のコアで順次処理を行うのに対し、NVIDIA GPUは数千個のNVIDIA CUDAコアを搭載し、大量の計算を同時に実行。
行列演算や畳み込み演算といったAI開発で頻繁に登場する処理は、まさにこの並列処理能力が活きる領域であり、NVIDIA CUDAはその性能を最大限に引き出すための鍵となっています。
900以上の専門ライブラリによる開発効率化
NVIDIA CUDAは、単なるプログラミングプラットフォームではありません。
900以上のCUDA Xライブラリという膨大なソフトウェア資産を擁しており、開発者はこれらを活用することで、ゼロからコードを書くことなく最先端の性能を引き出せます。
AIフレームワークとの統合
現代のAI開発において、PyTorch、TensorFlow、JAXといった主要フレームワークはすべてNVIDIA CUDA前提で最適化されています。
これらのフレームワークは内部でcuDNNやcuBLASといったCUDA Xライブラリを呼び出しており、開発者が直接CUDAコードを書かなくても、自動的にGPUの性能を最大限に引き出せる仕組みです。
例えば、PyTorchではmodel.cuda()やtensor.to(‘cuda’)といったシンプルなコマンドでGPU処理に切り替えられ、バックグラウンドで複雑な最適化が自動的に実行可能。
TensorFlowも同様に、NVIDIA CUDA対応GPUが検出されると自動的にGPU計算に切り替わり、cuDNNを利用した高速化が適用されます。
この「フレームワークレベルでの深い統合」により、AI開発者はハードウェアの詳細を意識することなく、アルゴリズムやモデル設計に集中できます。
GPUとは

GPUとは、Graphics Processing Unitの略で、画像や映像の描画処理を担当しているパーツです。同時に複数の処理を実施する並列処理が得意なため、ディープラーニングなども快適に行えます。
なお、CPUでも画像や映像の処理はできますが、並列処理はGPUほど快適にできません。CPUの力だけでは画像や映像の処理に多くの時間がかかってしまうため、動画編集や生成AI開発の分野ではGPUの力が必要不可欠です。


NVIDIA CUDAとは
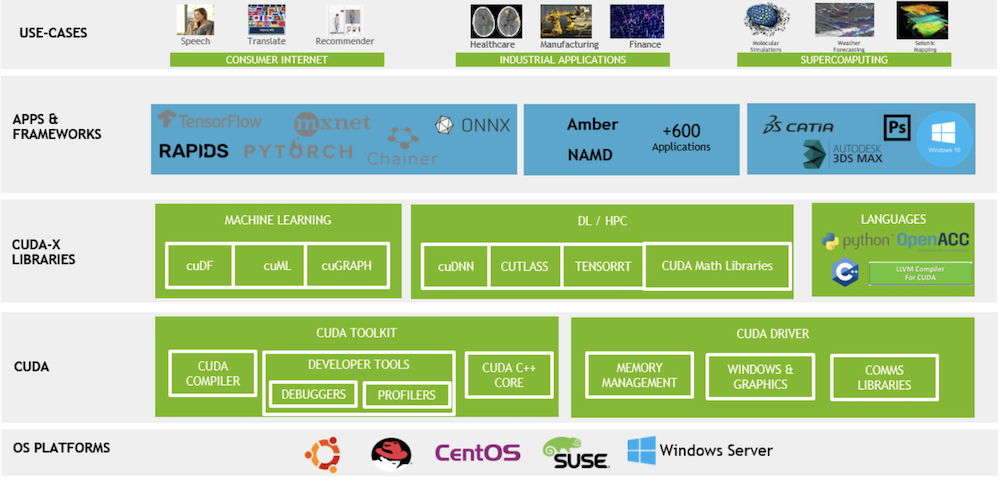
NVIDIA CUDAとは、NVIDIAが提供しているコンピューティングプラットフォームです。NVIDIA製GPUの性能を最適化し、並列処理の向上を実現できます。
元々GPUは画像処理や映像処理を目的に開発されていますが、NVIDIA CUDAの登場によって一般的な計算処理(GPGPU)にも応用できるようになりました。
具体的には、機械学習や科学技術計算などに応用可能で、現在でも現場の第一線で活用されています。
NVIDIA CUDAの仕組み

NVIDIA CUDAの仕組みは、GPU上で大量のスレッドを同時に実行し、高速な並列処理を可能にする点にあります。並列処理を高速化できるのは、NVIDIA CUDA対応GPUが数千の小さなコアを持ち、それぞれが独立した処理を実行するためです。
なお、NVIDIA CUDAは、主に以下4つの要素で構成されています。
| 項目 | 内容 |
|---|---|
| CUDA C/C++ | GPU向けの並列処理を記述するためにC/C++を拡張した言語。CPUとGPU両方にまたがるコードを一つのプログラムで書ける。 |
| CUDAランタイム | GPUとのやり取りを担うライブラリ群で、GPUメモリの確保やデータ転送、カーネルの実行などを簡単に扱えるようにする。 |
| CUDAドライバ | GPUをハードウェアとして制御するソフトウェア。プログラム実行時にGPUリソースの割り当てや管理を行う。 |
| CUDAツールキット | GPU開発に必要なツール一式(コンパイラnvcc、デバッガ、性能分析ツールなど)を含む開発用パッケージ。 |
プログラマーはCやPythonなどを使ってCUDA向けに記述したコードを、CPUからGPUに渡します。その後GPUは多数のスレッドを生成し、各データに対して同時に演算を実行します。
この並列処理構造により、大規模な計算タスクでも高速に処理できるのがNVIDIA CUDAの強みです。
CPUとGPUの役割分担
NVIDIA CUDAのプログラミングモデルは、ホスト(Host/CPU)とデバイス(Device/GPU)という2つの主要な要素を中心に構成されています。
ホスト(CPU)は、プログラム全体の制御を担当。
データの準備やGPU処理の起動指示、結果の受け取りと後処理といった「指揮者」の役割を果たします。複雑な条件分岐や逐次処理が必要な部分はCPUで実行され、プログラムの流れを管理。
一方、デバイス(GPU)は、大量の計算を並列で処理する「実行部隊」としての役割を担います。数千個のNVIDIA CUDAコアを活用し、同じような演算を一斉に実行することで、行列演算や画像処理といった計算集約的なタスクを高速化。
この協調動作は、次のような流れで実現されます。
まずホストがCPUメモリからGPUメモリへデータを転送し、GPU上で実行する処理を起動。デバイスは受け取った指示に従って並列計算を実行し、完了後、結果をホストに返却。ホストは受け取った結果を使って次の処理に進む、という具合です。
この「CPUが全体を管理し、計算負荷の高い部分だけをGPUに委譲する」という設計こそが、NVIDIA CUDAの高速化を支える基盤となっています。
スレッド・ブロック・グリッドとは?CUDAプログラミングの基本
NVIDIA CUDAの並列処理は、スレッド(Thread)、ブロック(Block)、グリッド(Grid)という3層の階層構造で分けられます。
最小単位であるスレッドが個々の処理を担当し、複数のスレッドがブロックにまとめられ、さらに複数のブロックがグリッドを構成。同じブロック内のスレッドは「共有メモリ」という高速メモリ領域を使って協調動作が可能です。
例えば、100万要素のベクトル加算では、256スレッド×約3,907ブロックという構成で並列実行します。カーネル関数は<<<グリッドサイズ, ブロックサイズ>>>という特殊な構文で起動され、一気に膨大な数のスレッドが各要素を同時に処理します。
// カーネル関数の定義
__global__ void vectorAdd(float *A, float *B, float *C, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}
// カーネル起動(100万要素を256スレッド×約3,907ブロックで処理)
vectorAdd<<<3907, 256>>>(d_A, d_B, d_C, 1000000);開発者は「1つのスレッドが何をするか」を記述するだけで、GPUが自動的に数千〜数万のスレッドを並列実行し、劇的な高速化を実現します。
NVIDIA CUDAを構成する主なコンポーネントと代表ライブラリ
NVIDIA CUDAは、開発環境・ランタイム・ライブラリが統合された包括的なエコシステム。
中核となるのがCUDA Toolkitで、nvcc(コンパイラ)、Nsightツール群(デバッガ・プロファイラ)、基本的な数学ライブラリ(cuBLAS、cuFFTなど)を含む開発者向けパッケージです。
2025年現在の最新版はCUDA Toolkit 13.xで、タイルベースプログラミングやBlackwellアーキテクチャに対応しています。
さらに、CUDA Xライブラリとして900以上の専門分野特化型ライブラリが提供されています。代表例は、ディープラーニングのcuDNN、線形代数のcuBLAS、AI推論のTensorRT、データフレーム処理のcuDF、最適化計算のcuOpt、医療画像処理のMONAIなど。
多くの開発者は直接CUDA C/C++コードを書きません。
PyTorchやTensorFlowが内部で自動的にこれらのライブラリを呼び出すため、高レベルフレームワークを使うだけで最適化されたGPU処理が実現できます。
低レベルCUDAコードを記述するのは、独自アルゴリズム開発や極限的な性能最適化が必要な専門家に限られます。
CUDA ToolkitとCUDA Xライブラリの関係
CUDA Toolkitは、GPU開発の土台となる開発環境で、コンパイラ、デバッガ、プロファイラ、基本的な数学ライブラリを含みます。
一方、CUDA Xライブラリは、この土台の上に構築された専門分野特化型のライブラリ群で、CUDA Toolkitの基本ライブラリを内部で活用しながら、さらに高度な機能を実装。
実際の開発では、PyTorch/TensorFlow → cuDNN/TensorRT → cuBLAS/cuFFT → CUDA Toolkitという階層構造で利用されます。
ほとんどの開発者は高レベルフレームワークを使うだけで自動的に最適化されたGPU処理が実行され、独自アルゴリズムを実装したい専門家のみがCUDA Toolkitで直接カーネル関数を記述します。
NVIDIA CUDAが活用される分野
NVIDIA CUDAが活用されるのは、おもに以下4つの分野です。
- 機械学習・ディープラーニング
- 画像・動画処理
- 数値的なシミュレーション
- マイニング
それぞれの分野におけるNVIDIA CUDAの活用法について、以下で詳しくみていきましょう。
機械学習・ディープラーニング
NVIDIA CUDAは、機械学習・ディープラーニングにおいて、大量の並列計算や行列演算を高速に処理するために活用されています。GPUの並列演算能力を最大限に引き出すことで、膨大なデータを扱う深層学習などの処理時間を大幅に短縮できるためです。
特に、PyTorchやTensorFlowなどの主要なライブラリはNVIDIA CUDAと連携しており、研究から実用化まで幅広いAI開発の基盤となっています。
画像・動画処理
NVIDIA CUDAは、画像や動画処理において、処理の高速化や高精度化を果たす目的でも活用されています。たとえば、ノイズ除去や画像の鮮明化、リアルタイム映像解析といった演算処理をGPUの並列計算によって効率化可能です。
高解像度映像を扱う際にもフレーム単位で処理が分散されるため、滑らかな動作と短い応答時間を実現できます。映像編集、医用画像処理、監視カメラのリアルタイム分析など、さまざまな現場で導入が進んでいます。
数値的なシミュレーション
NVIDIA CUDAは、数値的なシミュレーションにおいても、処理の高速化や高精度化を果たす目的で活用されています。たとえば、気象予測・流体力学・構造解析など、大量の数値計算を伴うシミュレーションでは、GPUによる並列処理が有効です。
複雑なモデルの演算を同時に行うことで、従来のCPUベースでは数日かかる計算も短時間で完了することが可能になります。工業分野や研究機関では、実験コスト削減や開発期間の短縮にもつながっています。
マイニング
NVIDIA CUDAは、ビットコインなどの暗号資産取引を承認し、ブロックチェーンに記録する「マイニング」のプロセスでも活用されています。
マイニングでは、大量のハッシュ計算を短時間で繰り返す必要があるため、CPUのみで実施すると計算が遅くなり、ブロック報酬を得られる確率が下がってしまいます。
しかし、NVIDIA CUDAを活用すれば演算効率が引き上げられるため、マイニングの効率と収益性が向上するというわけです。


NVIDIA CUDAを使うための準備と環境構築
NVIDIA CUDAを実際に使い始めるには、適切な環境構築が不可欠です。以下の4ステップで、スムーズにNVIDIA CUDA環境をセットアップできます。
ステップ1:対応GPUの確認
まず、使用しているGPUがNVIDIA CUDA対応かを確認。NVIDIA製GPUのほとんどがNVIDIA CUDAに対応していますが、世代によってサポート機能が異なります。
| GPUシリーズ | 発売時期 | アーキテクチャ | 必要なCUDAバージョン |
|---|---|---|---|
| GeForce RTX 50シリーズ | 2025年〜 | Blackwell | CUDA 12.8以降 |
| GeForce RTX 40シリーズ | 2022年〜 | Ada Lovelace | CUDA 11.8以降 |
| GeForce RTX 30シリーズ | 2020年〜 | Ampere | CUDA 11.1以降 |
| GeForce RTX 20シリーズ | 2018年〜 | Turing | CUDA 10.0以降 |
| データセンター向けGPU | – | A100、H100、B200など | 最新CUDA Toolkit対応 |
使用中のGPU名は、Windowsなら「タスクマネージャー」→「パフォーマンス」→「GPU」で、Linuxならnvidia-smiコマンドで確認できます。
ステップ2:最新ドライバのインストール
NVIDIAドライバは、NVIDIA CUDAとGPUの橋渡しをする重要なソフトウェア。使用するCUDA Toolkitのバージョンに対応したドライバをインストールする必要があります。
| CUDAバージョン | 必要なドライババージョン |
|---|---|
| CUDA 12.8 | Windows: 570.65以降 Linux: 570.26以降 |
| CUDA 12.1〜12.7 | 530.30以降 |
| CUDA 11.8 | 450.80以降 |
NVIDIA公式サイトから、使用GPUに対応した最新ドライバをダウンロードし、インストール。インストール後、nvidia-smiコマンドで動作確認を行います。
ステップ3:CUDA Toolkitのインストール
最も重要なのは、使用するAIフレームワーク(PyTorch、TensorFlowなど)が推奨するNVIDIA CUDAバージョンを確認し、それに合わせてインストールすることです。バージョンによって変化はしますが、バージョンが合わない場合GPUが認識されず、学習が進まないトラブルが頻発します。
| フレームワーク | 推奨CUDAバージョン | 追加要件 | 公式サイト |
|---|---|---|---|
| PyTorch | CUDA 12.1または11.8 | – | pytorch.org |
| TensorFlow | CUDA 11.8 | cuDNN 8.6 | tensorflow.org/install/gpu |
NVIDIA CUDA Toolkit公式ページから、対応バージョンをダウンロードしてインストールします。インストール後、以下のコマンドでバージョンを確認できます。
nvcc --version # CUDA Toolkitのバージョン確認ステップ4:サンプルコード・ベンチマークの実行
環境構築が完了したら、動作確認を兼ねてサンプルコードやベンチマークを実行します。
PyTorchでの確認例
import torch
print(torch.cuda.is_available()) # True なら成功
print(torch.cuda.get_device_name(0)) # GPU名を表示CUDA Toolkitには、数百のサンプルプログラムが同梱されています。
例えば、deviceQueryサンプルはGPU情報を詳細に表示し、bandwidthTestはメモリ転送速度をベンチマークできます。
これらのステップを踏むことで、NVIDIA CUDA環境が正しく構築され、本格的なGPU開発やAI学習をスタートできます。
NVIDIA CUDAを活用する際の注意点
NVIDIA CUDAを活用する際は、以下の2点に注意が必要です。
- NVIDIA製のGPUでしか利用できない
- グラフィックボード(GPU)が高い
特に、NVIDIA CUDAは、同社が開発したNVIDIA製GPUでしか利用できない点に注意が必要です。
以下で注意点を詳しく解説するので、ぜひ参考にしてみてください。
NVIDIA製のGPUでしか利用できない
NVIDIA CUDAは、NVIDIAが独自に開発したGPU向けの並列コンピューティング技術です。そのため、NVIDIA CUDAを使ったプログラムはNVIDIA製のGPUでしか実行できません。
たとえば、AMD製のRadeonシリーズやIntelの統合グラフィックスでは、NVIDIA CUDAをサポートしていない点に注意しましょう。
グラフィックボード(GPU)が高い
NVIDIA CUDAを利用するにはNVIDIA製GPUが必要ですが、そもそもグラフィックボード(GPU)自体の価格が高いという問題があります。
特に、2025年1月に発売されたRTX 5000シリーズは品薄状態が続いており、価格も上昇傾向にあります。最高性能のRTX 5090は2025年12月時点で55万円以上に高騰し、在庫もほぼ入手困難な状況です。
| モデル | 価格帯 | 備考 |
|---|---|---|
| RTX 5070 | 約10万円台~ | 比較的入手可能 |
| RTX 5070 Ti | 約15万円台後半~18万円台 | 先月比で約2万円値上がり |
| RTX 5080 | 約20万円~ | 在庫減少、値上がり傾向 |
| RTX 5090 | 約55万円~ | 在庫ほぼなし、高級モデルは60万円超 |
ただ、NVIDIA CUDAの利用で各タスクの生産性が上がることを考慮するなら、初期コストが多少高くてもNVIDIA製GPUを購入する価値はあります。
なお、NVIDIAが開発した「Chat with RTX」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

NVIDIA CUDAのデメリット
NVIDIA CUDAを使うことで得られる恩恵は多くありますが、その一方でNVIDIA CUDAのデメリットも存在します。ここではNVIDIA CUDAのデメリットをいくつか紹介します。
ベンダーロックイン(NVIDIA GPU専用)
CUDAはNVIDIA製GPU専用で、AMDやIntelのGPUでは動作しません。
一度CUDAベースのシステムを構築すると、他社GPUへの移行が困難になるベンダーロックインが生じます。
ただし最近はAMD ROCm、Intel oneAPI、Modularなどマルチベンダー対応技術が登場しており、PyTorchやTensorFlowといった高レベルフレームワークを使えば、低レベルCUDA依存を抑えて将来的な移行可能性を残せます。
GPU本体の価格が高い
最新世代GPUは高価です。
2025年発売のRTX 50シリーズ国内参考価格は、RTX 5070が約108,800円からRTX 5090が約550,000円を超えるものまで。データセンター向けGPU(A100、H100など)は数百万円規模です。
初期投資を抑えるには、AWSやGCPのクラウドGPUやスポットインスタンス(通常価格の30〜70%)を活用する方法があります。
学習コストと独自の考え方が必要
並列化設計やメモリ転送の最適化など、GPU特有の考え方を理解する必要があり、CPU向けプログラミングとは異なる学習コストがかかります。
初心者はPyTorchやTensorFlowから始め、NVIDIA Deep Learning Instituteなどの公式リソースで段階的に学ぶのが効率的です。
古いGPUは新CUDA Toolkitで非サポート化
NVIDIAは定期的に古いGPU世代のサポートを終了します。CUDA Toolkit 13.0以降では、Maxwell、Pascal、Voltaがサポート対象外です。古いGPUを使う場合はCUDA Toolkit 12.9以前を利用するか、GPUアップグレードやクラウドGPU移行を検討する必要があります。
NVIDIA CUDAと他GPUプラットフォームの違い
NVIDIA CUDAがGPUコンピューティング市場で圧倒的なシェアを持つ一方で、ベンダーロックインへの懸念から、マルチベンダー対応を目指す動きも活発化しています。
ここでは主要な代替技術と、それらがNVIDIA CUDAとどう異なるのかを解説します。
主要な代替GPUプラットフォーム
AMD ROCmは、AMDが提供するオープンソースのGPUコンピューティングプラットフォームです。
CUDAコードを移植するための互換レイヤーを備えており、AMD製GPUでの並列計算を可能にします。
Intel oneAPIは、GPU・CPU・FPGAなど複数のハードウェアに対応したオープンスタンダード。SYCLというC++ベースの並列プログラミング言語を採用し、Intel製GPUだけでなく、他社ハードウェアでも動作する移植性の高さが特徴です。
OpenCLはクロスプラットフォームの並列計算標準として長年存在していますが、NVIDIA CUDAに比べて開発者向けツールやライブラリのエコシステムが限定的で、実務での採用は限られています。
CUDA依存を減らすミドルウェアの動き
最近では、特定のGPUベンダーに依存しないマルチベンダー向けソフトウェアレイヤーが登場しています。
Modularは、複数のハードウェアアーキテクチャに対応した新世代AIコンパイラとして注目を集めており、NVIDIA、AMD、Intelのいずれのプラットフォームでも動作するコードを記述できる将来性が期待されています。
また、ONNX Runtimeのように、学習済みモデルを異なるハードウェア間で相互運用できるフレームワークも普及しつつあり、NVIDIA CUDAへの直接依存を減らす選択肢が増えています。
NVIDIA CUDAをこれから学びたい人向けロードマップ
NVIDIA CUDAの学習は、いきなり低レベルのGPUプログラミングから始める必要はありません。まずは前述の「NVIDIA CUDAを使うための準備と環境構築」から進めていきましょう。
環境構築ができたら、PyTorch/TensorFlowをCUDA有効→CUDAサンプルを動かす→カーネル、スレッド、メモリモデルを学ぶ、という順に学習を進めていくのがおすすめ。
PyTorch/TensorFlowをCUDA有効で使ってみる
次に、PyTorchやTensorFlowなど高レベルフレームワークをインストールし、GPU処理を体験します。以下のコードでGPUが認識されているか確認できます。
import torch
print(torch.cuda.is_available()) # Trueなら成功
print(torch.cuda.get_device_name(0)) # GPU名を表示この段階では、NVIDIA CUDAの内部動作を意識する必要はありません。
フレームワークが自動的にcuDNNやcuBLASを呼び出し、GPU処理を最適化してくれます。画像分類や自然言語処理のチュートリアルを実行して、CPUとGPUの速度差を体感してみましょう。
CUDAサンプルを動かす
NVIDIA公式のCUDAサンプルから deviceQuery や bandwidthTest などの基本サンプルを実行します。これらのサンプルは、GPUの仕様やメモリ転送速度を確認できるため、GPU性能の把握に役立ちます。
カーネル、スレッド、メモリモデルを学ぶ
ここから、CUDA独自の並列処理モデルを学びます。
スレッド・ブロック・グリッドの階層構造、ホスト(CPU)とデバイス(GPU)の役割分担、グローバルメモリと共有メモリの違いなど、GPU特有の概念を理解します。
簡単なベクトル加算や行列積のカーネルを自分で記述してみることで、並列化設計の基礎を習得可能。
CUDA C++の基本文法と <<<グリッドサイズ, ブロックサイズ>>> による起動構文にも慣れていきましょう。
NVIDIA CUDAに関するよくある質問
ここではNVIDIA CUDAに関するよくある質問について回答していきます。
NVIDIA CUDAを活用してみよう
NVIDIA CUDAは、すでに生成AI開発・動画編集・シミュレーションなどの分野で広く活用されています。並列処理を高速で実行できるようになるため、CPU単体で処理していた作業が数倍早く終わるはずです。
ただし、NVIDIA CUDAは同社のGPU以外で利用できない点やそもそもGPU自体が高い点には注意しましょう。
それでも、生成AI分野の発達によりNVIDIA CUDAの重要性は益々上がっていくと考えられるため、生成AI開発や利用を効率化していきたい方は、ぜひ導入を検討してみてください。

最後に
いかがだったでしょうか?
クラウドに依存せず、社内環境でAIを動かしたいというニーズが高まっています。並列処理の仕組みを活用すれば、大規模な計算も効率よく実行可能に。運用環境に合わせた最適な構成を検討してみませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、通勤時間に読めるメルマガを配信しています。
最新のAI情報を日本最速で受け取りたい方は、以下からご登録ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

