

- Gemini Omni Flashは、テキスト・画像・動画を入力に高品質な動画生成と会話型編集ができるGoogleのマルチモーダルAIモデル
- 自然言語で指示するだけで動画を修正でき、1秒あたり$0.10という低コストで利用可能
- 画像モデルNano Banana 2 Liteと連携させることで、画像生成から動画化までを一気通貫で構築できる
2026年6月、Googleから新たな動画生成・編集AIモデルが発表されました。
今回登場した「Gemini Omni Flash」は、Geminiのマルチモーダル推論と動画生成・編集を融合させた新しいAIモデルです。テキスト・画像・動画・音声を組み合わせて入力し、高品質な動画の生成と会話型の編集をネイティブにこなせます。
Introducing Nano Banana 2 Lite
— Logan Kilpatrick (@OfficialLoganK) June 30, 2026and Gemini Omni Flash
, our new generative media models in the Gemini API and AI Studio!
Nano Banana 2 Lite is extremely fast (<4s image) & cheap ($0.034 / 1K image).
Omni Flash is SOTA at video editing at $0.10 / sec, same as Veo 3.1 Fast! pic.twitter.com/qDxRpqpX5E
これまでの動画生成AIでは、「一度生成した動画を細かく直しづらい」「シーンやキャラクターの一貫性を保てない」「生成コストが高く反復に向かない」といった課題がありました。
一方でGemini Omni Flashは、自然言語での対話を通じて動画を反復的に磨き込めます。さらにVeo 3.1 Fastと同等の1秒あたり$0.10という価格設定で、コスト効率も重視した設計です。
しかし、新しいモデルが登場するたびに「従来の動画生成AIと何が違うのか」「どこまで編集を任せられるのか」「実際にどのように使うのか」といった疑問を感じる方も多いのではないでしょうか。
そこで本記事では、Gemini Omni Flashの概要や仕組み、特徴を解説しながら、料金や具体的な活用方法までを詳しく紹介します。
最後までお読みいただくことで、Gemini Omni Flashがどのような思想で設計され、どのような場面で力を発揮するのかが理解できるはずです。ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/

- Gemini Omni Flashとは
- Gemini Omni Flashの仕組み
- Gemini Omni Flashの特徴
- Gemini Omni Flashの安全性・制約
- Gemini Omni Flashの料金
- Gemini Omni Flashのライセンス
- Gemini Omni Flashの使い方
- 【業界別】Gemini Omni Flashの活用シーン
- Gemini Omni Flashを実際に使ってみた
- Gemini Omni Flashの活用事例
- 【課題別】Gemini Omni Flashが解決できること
- Gemini Omni Flashのよくある質問
- Gemini Omni Flashで動画制作を加速しよう
- 最後に
Gemini Omni Flashとは
Gemini Omni Flash(gemini-omni-flash-preview)は、Googleが2026年6月に発表した高品質・低コストな動画生成・編集AIモデルです。
もともとはGoogle I/Oで「Geminiのマルチモーダル推論が動画生成・編集と出会うモデル」として発表されており、今回開発者向けにGemini APIとGoogle AI Studioで提供が始まりました。
テキスト・画像・動画・音声を組み合わせた入力から、動画の生成と会話型編集をネイティブにサポートする点が最大の特徴。単に一発で動画を作るだけでなく、対話しながら少しずつ仕上げていける点が従来モデルとの大きな違いといえるでしょう。
Gemini APIやGoogle AI Studioに加えて、GeminiアプリやGoogle Flowでも利用可能です。
| 項目 | Gemini Omni Flash |
|---|---|
| 提供元 | Google(Google DeepMind) |
| モデル名 | gemini-omni-flash-preview |
| 主な用途 | 動画生成・会話型の動画編集 |
| 入力 | テキスト・画像・動画・音声のマルチモーダル入力 |
| 料金 | 動画出力1秒あたり$0.10(Veo 3.1 Fastと同等) |
| 提供形態 | Gemini API・Google AI Studio・Geminiアプリ・Google Flow・Gemini Enterprise Agent Platform |


Gemini Omni Flashの仕組み
Gemini Omni Flashは、Geminiが持つマルチモーダル推論能力を動画の生成・編集に応用したモデルです。
テキスト・画像・動画・音声という複数の入力を横断的に理解し、それらを組み合わせながら1本の動画へと落とし込みます。単なる映像生成にとどまらず、歴史・生物学・物語の論理といったGeminiの知識を土台に映像を構成できる点が特徴です。
Gemini Omni Flashが動画を生成・編集する基本的な流れは以下のとおりです。
- テキスト・画像・動画などのマルチモーダル入力を受け取り、シーンの意図や文脈を理解する
- Geminiの実世界知識と物語論理をもとに、映像として成立する構成を組み立てる
- 参照した画像や動画をもとに、シーンの一貫性を保ちながら高品質な動画を生成する
- ユーザーが自然言語で出した修正指示を反映し、対話的に動画を磨き込んでいく
特に注目したいのが、Interactions APIを使ったマルチターン編集です。セッションの履歴とコンテキストを保持できるため、ユーザーは最大3回まで連続した編集を積み重ねられます。
Gemini Omni Flashの特徴
Gemini Omni Flashの強みは、会話型編集・マルチモーダル参照・実世界知識・テキスト同期という4つの能力を1つのモデルで両立している点です。ここでは、その主な特徴を詳しく見ていきます。
| 特徴 | 内容 |
|---|---|
| 会話型動画編集 | 自然言語で指示するだけで動画を修正・編集できる |
| マルチモーダル参照 | 画像・テキスト・動画を組み合わせ、シーンの制御と一貫性を維持できる |
| 実世界知識 | 歴史・生物学・物語論理などGeminiの知識を活かして説得力のある動画を構成する |
| テキストとアクションの同期 | テキストや図形を動画のアクションに直接ひも付けられる |
自然言語で動画を直せる会話型編集
Gemini Omni Flash最大の魅力は、会話型の動画編集にあります。
専門的な編集ソフトを操作しなくても、「ここをこう直して」と話しかけるだけで動画を修正できる点が従来の制作フローと大きく異なります。生成した動画に対して、対話しながら少しずつ理想へ近づけていけます。
画像・動画を参照してシーンの一貫性を保つ
マルチモーダル参照によって、画像・テキスト・動画といった複数の入力を組み合わせながらシーンをコントロールできます。
参照素材をもとに映像を構成するため、キャラクターや世界観の一貫性を維持しやすい点がポイントです。ブランドの世界観を守りたい商用制作でも活かしやすいのではないでしょうか。
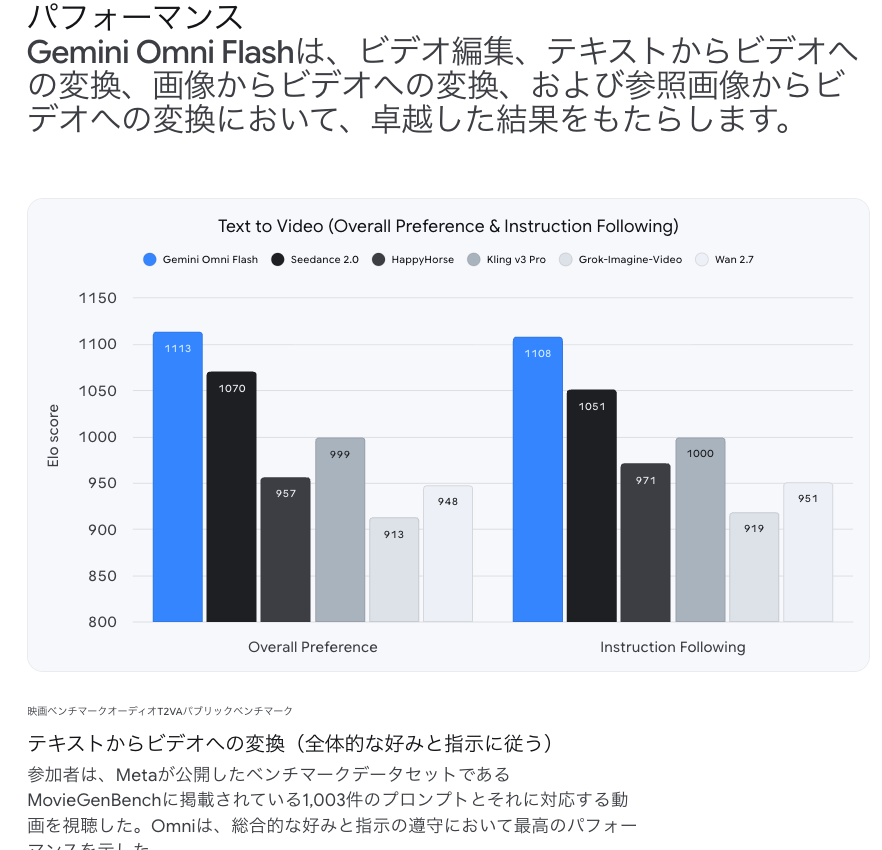
動画編集ベンチマークで競合を上回る評価
動画編集のベンチマークでは、Gemini Omni Flashが競合モデルを上回るEloスコアを記録しています。
| 評価項目 | Gemini Omni Flash | HappyHorse | Kling v3 Pro | Seedance 2.0 | Wan 2.7 |
|---|---|---|---|---|---|
| Overall Preference(総合評価) | 1087 | 1044 | 1010 | 946 | 900 |
| Instruction Following(指示追従) | 1082 | 1036 | 1029 | 946 | 900 |
総合評価・指示追従のどちらでも、Gemini Omni Flashが最高スコアを獲得しています。特に指示追従の高さは、会話型編集との相性の良さにつながっているといえるでしょう。
AIでアニメーション制作できるAnimate Anyoneについて、詳しく知りたい方は下記の記事もあわせてご覧ください。

Gemini Omni Flashの安全性・制約
Gemini Omni Flashは、Googleのセキュアなインフラ上に構築されています。
生成されたコンテンツにはSynthIDによる電子透かし(ウォーターマーク)が付与。GeminiアプリやChrome・検索上のGeminiを通じて、AIが生成したコンテンツかどうかを確認できます。
一方で、パブリックプレビュー段階のため、現時点ではいくつかの制約もあります。
| 制約項目 | 内容 |
|---|---|
| 動画の長さ | 現時点では10秒の動画生成に対応。より長い尺は今後対応予定 |
| 音声リファレンス | 音声リファレンスのアップロードとシーン拡張は、現時点でGemini API未対応 |
| 動画リファレンス | 最大3秒の動画リファレンスはAPIスキーマ上は受け付けるが、現時点では正しく処理されない |
| 一貫性の限界 | シーン切り替えやパン移動時のキャラクター一貫性に一部制約あり |


Gemini Omni Flashの料金
Gemini Omni Flashは、動画出力1秒あたり$0.10という料金体系です。
この価格はGoogleの動画生成モデルVeo 3.1 Fastと同等で、高品質な動画生成・編集を低コストで利用できる点が魅力といえるでしょう。会話型編集で何度も試行錯誤する使い方とも相性が良い価格設定です。
| 項目 | 内容 |
|---|---|
| 料金 | 動画出力1秒あたり$0.10 |
| 比較対象 | Veo 3.1 Fastと同水準 |
| 提供状況 | Google AI StudioとGemini APIでパブリックプレビュー提供中 |
xAIの最新画像to動画AIモデルであるGrok Imagine Video 1.5について、詳しく知りたい方は下記の記事もあわせてご覧ください。

Gemini Omni Flashのライセンス
Gemini Omni Flashは、Googleが提供するクローズドな商用APIサービスとして運用されています。
利用にあたってはGemini APIの利用規約および追加利用規約が適用されます。API経由での商用利用やプロダクトへの組み込みは想定されている一方で、モデル本体の重みは公開されていないため、改変や再配布はできません。
| 利用区分 | 可否 |
|---|---|
| 商用利用 |  (規約準拠) (規約準拠) |
| 私的利用 |  |
| 改変(モデル本体) |  |
| 再配布(モデル本体) | |
| 特許利用 | 不明 |
xAIの最新画像to動画AIモデルであるGrok Imagine Video 1.5について、詳しく知りたい方は下記の記事もあわせてご覧ください。
Gemini Omni Flashの使い方
Gemini Omni Flashは、Google AI StudioとGemini APIを中心に利用できます。まずは手軽に試せるGoogle AI Studioから使い始めるのがおすすめです。
Google AI Studioで試す
まずはブラウザ上で完結するGoogle AI Studioで動作を確認していきます。
Google AI Studioにアクセスし、Googleアカウントでログインします。
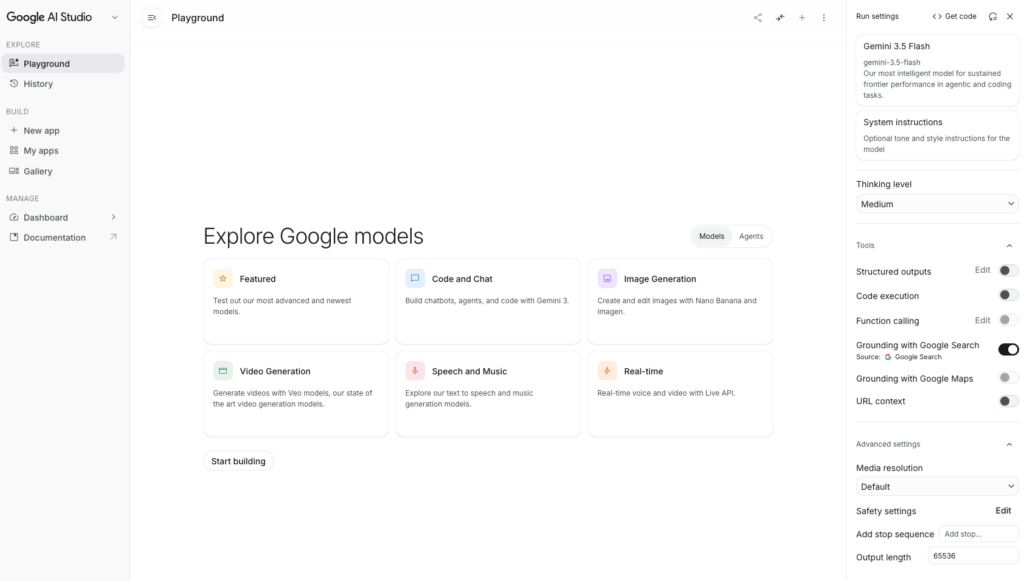
モデル選択画面でGemini Omni Flash(gemini-omni-flash-preview)を選びます。プレイグラウンド上で動画生成・編集を試せます。

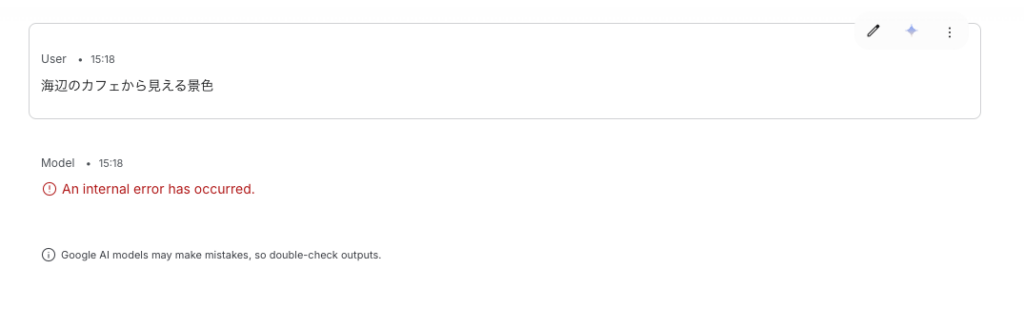
作りたい動画のイメージをテキストで入力し、必要に応じて画像や動画を参照素材として追加します。生成後は「ここをこう直して」と自然言語で指示し、会話型編集で仕上げていきましょう。
実際に「海辺のカフェから見える景色」というプロンプトを与えて動画生成を試みましたが、筆者の環境ではエラーになってしまい、使うことができませんでした。
1フレーム編集で動画全体を変えるRunwayの最新映像編集AIモデルであるAleph 2.0について、詳しく知りたい方は下記の記事もご覧ください。

【業界別】Gemini Omni Flashの活用シーン
Gemini Omni Flashが特に力を発揮するのは、動画の反復制作やスピードが求められる領域でしょう。ここでは、考えられる活用シーンを業界別に紹介します。
EC・マーケティング
EC・マーケティング分野では、商品動画の量産に活用できるでしょう。
実際にデモアプリ「Omni product studio」では、画像モデルNano Banana 2 Liteで作った静止画を、Gemini Omni FlashでシネマティックなEC動画へ変換しています。大量の商品ページ向け動画を、素早く低コストで生成できる点が魅力です。
生成AIを使ったマーケティング活用方法と事例について、詳しく知りたい方は下記の記事もあわせてご覧ください。

インテリア・空間デザイン
インテリアや空間デザインの分野でも、提案のビジュアル化に役立ちます。
デモアプリ「Space Lift」では、部屋の写真をアップロードするだけでさまざまなデザインコンセプトを生成し、動画ボタンを押すとGemini Omni Flashがシネマティックな映像として空間を提示します。完成前に新しい空間を「動き」で体験できる仕組みです。
室内デザインをAIが提案する生成AI×インテリアについて、詳しく知りたい方は下記の記事もあわせてご覧ください。

旅行・観光
旅行・観光分野では、体験型のビジュアルコンテンツ制作に活用できます。
デモアプリ「Anywhere」では、セルフィーや写真をアップロードするとNano Banana 2 Liteが世界の名所へ「瞬間移動」させ、画像をクリックするとGemini Omni Flashがその場所のアニメーションクリップへ変換します。観光地のプロモーションなどへの応用が期待できます。
観光業界が抱える問題も生成AIで解決する方法について、詳しく知りたい方は下記の記事をご覧ください。

Gemini Omni Flashを実際に使ってみた
先ほどはGoogle AI Studio上で利用を試みましたが、エラーでうまくいかなかったので、今度はAPIキーを利用してアプリに組み込んでみたいと思います。
今回はプロンプトを入力するとGemini Omni Flashで10秒動画を生成し、Colab上で再生する簡易アプリを作っていきます。
サンプルコードはこちら
!pip install -q google-genai ipywidgets requests
from google import genai
from IPython.display import display, Video
import ipywidgets as widgets
import base64
import requests
import time
import os
# =========================
# APIキーをハードコード
# =========================
API_KEY = "YOUR_GEMINI_API_KEY"
client = genai.Client(api_key=API_KEY)
# =========================
# プロンプト作成
# =========================
def build_prompt(user_prompt, style):
style_prompts = {
"cinematic": """
シネマティックな映像にしてください。
自然なカメラワーク、映画のようなライティング、滑らかな動き、高品質な質感を重視してください。
""",
"product": """
商品紹介動画のようにしてください。
商品が魅力的に見える構図、なめらかなカメラ移動、広告向けの明るい演出を入れてください。
""",
"sns_ad": """
SNS広告向けの短尺動画にしてください。
最初の1秒で目を引く構図にし、テンポよく視線を誘導してください。
""",
"travel": """
旅行Vlog風の映像にしてください。
自然な手持ちカメラ感、現地の空気感、没入感のある動きを重視してください。
""",
"anime": """
アニメ風の映像にしてください。
鮮やかな色彩、印象的なカメラワーク、キャラクターや背景の動きを自然に表現してください。
""",
"interior": """
インテリア紹介動画のようにしてください。
部屋の奥へゆっくり進むカメラワーク、家具や照明が美しく見える演出を入れてください。
"""
}
return f"""
以下の内容をもとに、10秒の短い動画を生成してください。
# 動画の内容
{user_prompt}
# スタイル指定
{style_prompts.get(style, "")}
# 共通条件
- 10秒の動画にしてください
- 1つの連続したシーンにしてください
- 動きは自然で滑らかにしてください
- 不自然な文字やロゴは入れないでください
- 被写体や背景の一貫性をできるだけ維持してください
"""
# =========================
# 動画保存関数
# =========================
def save_video(interaction, output_path="omni_flash_demo.mp4"):
"""
Gemini Omni Flashの返却形式に合わせて、以下を順番に試します。
1. interaction.output_video.data
2. interaction.output_video.uri
3. interaction.output 内の video.data
4. interaction.generated_videos 内の video.data
"""
print("\n動画データの保存を開始します...")
# -------------------------
# 1. interaction.output_video
# -------------------------
video_output = getattr(interaction, "output_video", None)
if video_output is not None:
print("\noutput_videoが見つかりました。")
print(video_output)
# base64データで返ってくる場合
data = getattr(video_output, "data", None)
if data:
print("\nbase64データから動画を保存します。")
if isinstance(data, str):
data = base64.b64decode(data)
with open(output_path, "wb") as f:
f.write(data)
return output_path
# URIで返ってくる場合
uri = getattr(video_output, "uri", None)
if uri:
print("\nURIから動画をダウンロードします。")
print("uri:", uri)
headers = {
"x-goog-api-key": API_KEY
}
response = requests.get(uri, headers=headers)
print("download status:", response.status_code)
print("content-type:", response.headers.get("content-type"))
if response.status_code == 200:
with open(output_path, "wb") as f:
f.write(response.content)
return output_path
print("URIからのダウンロードに失敗しました。")
print(response.text[:1000])
# -------------------------
# 2. interaction.output
# -------------------------
output = getattr(interaction, "output", None)
if output:
print("\ninteraction.outputを確認します。")
try:
for item in output:
video = getattr(item, "video", None)
if video:
data = getattr(video, "data", None)
if data:
print("\ninteraction.output内のvideo.dataから保存します。")
if isinstance(data, str):
data = base64.b64decode(data)
with open(output_path, "wb") as f:
f.write(data)
return output_path
uri = getattr(video, "uri", None)
if uri:
print("\ninteraction.output内のvideo.uriから保存します。")
print("uri:", uri)
headers = {
"x-goog-api-key": API_KEY
}
response = requests.get(uri, headers=headers)
print("download status:", response.status_code)
print("content-type:", response.headers.get("content-type"))
if response.status_code == 200:
with open(output_path, "wb") as f:
f.write(response.content)
return output_path
print("URIからのダウンロードに失敗しました。")
print(response.text[:1000])
except Exception as e:
print("interaction.outputの確認中にエラーが発生しました。")
print(e)
# -------------------------
# 3. interaction.generated_videos
# -------------------------
generated_videos = getattr(interaction, "generated_videos", None)
if generated_videos:
print("\ngenerated_videosを確認します。")
try:
video_item = generated_videos[0]
video = getattr(video_item, "video", None)
if video:
data = getattr(video, "data", None)
if data:
print("\ngenerated_videos内のvideo.dataから保存します。")
if isinstance(data, str):
data = base64.b64decode(data)
with open(output_path, "wb") as f:
f.write(data)
return output_path
uri = getattr(video, "uri", None)
if uri:
print("\ngenerated_videos内のvideo.uriから保存します。")
print("uri:", uri)
headers = {
"x-goog-api-key": API_KEY
}
response = requests.get(uri, headers=headers)
print("download status:", response.status_code)
print("content-type:", response.headers.get("content-type"))
if response.status_code == 200:
with open(output_path, "wb") as f:
f.write(response.content)
return output_path
print("URIからのダウンロードに失敗しました。")
print(response.text[:1000])
except Exception as e:
print("generated_videosの確認中にエラーが発生しました。")
print(e)
print("\n動画ファイルを保存できませんでした。")
print("返却オブジェクトの確認用情報:")
print("type(interaction):", type(interaction))
print("dir(interaction):")
print(dir(interaction))
return None
# =========================
# UI
# =========================
prompt_box = widgets.Textarea(
value="白いスニーカーが水面の上に浮かび、周囲に光の粒子が広がる。カメラがゆっくり回り込み、最後にスニーカーが明るく照らされる。",
placeholder="生成したい動画の内容を入力してください",
description="Prompt:",
layout=widgets.Layout(width="100%", height="140px")
)
style_box = widgets.Dropdown(
options=[
("シネマティック", "cinematic"),
("商品紹介", "product"),
("SNS広告", "sns_ad"),
("旅行Vlog", "travel"),
("アニメ風", "anime"),
("インテリア紹介", "interior"),
],
value="cinematic",
description="Style:"
)
generate_button = widgets.Button(
description="10秒動画を生成",
button_style="primary"
)
output_area = widgets.Output()
# =========================
# 生成ボタン処理
# =========================
def on_generate_clicked(button):
with output_area:
output_area.clear_output()
user_prompt = prompt_box.value.strip()
style = style_box.value
if not user_prompt:
print("プロンプトを入力してください。")
return
full_prompt = build_prompt(user_prompt, style)
generation_config = {
"max_output_tokens": 65536,
"thinking_level": "high",
"video_config": {
"task": "text_to_video",
},
}
print("Gemini Omni Flashで動画を生成中です...")
print("少し時間がかかる場合があります。")
try:
interaction = client.interactions.create(
model="models/gemini-omni-flash-preview",
input=full_prompt,
generation_config=generation_config,
response_modalities=["video"],
response_format={
"type": "video",
"duration": "10s",
"delivery": "uri",
},
)
print("\n生成リクエストが完了しました。")
print("interaction id:", getattr(interaction, "id", None))
print("status:", getattr(interaction, "status", None))
output_text = getattr(interaction, "output_text", "")
if output_text:
print("\nテキスト出力:")
print(output_text)
video_path = save_video(interaction)
if video_path:
print(f"\n動画を保存しました: {video_path}")
display(Video(video_path, embed=True))
else:
print("\n動画ファイルを自動保存できませんでした。")
print("返却オブジェクトを確認してください。")
print(interaction)
except Exception as e:
print("エラーが発生しました。")
print(e)
generate_button.on_click(on_generate_clicked)
display(prompt_box, style_box, generate_button, output_area)実際に動かしている様子がこちらです。
実際に生成された動画がこちらです。
こちらの意図通りの動画を作ってくれました。ただ、靴のメーカーは指定していませんが見覚えのあるマークのスニーカーが生成されました。
Q3を超える新モデルであるSeedance 2.0ベースのVidu Omni Video Proについて、詳しく知りたい方は下記の記事もご覧ください。

Gemini Omni Flashの活用事例
ここではGemini Omni Flashを使った活用事例をX上でリサーチして紹介いたします。皆さんがどのような使い方をしているのか参考にしてください。
テレビ風テロップ
こちらの投稿では素材とコンテを組み合わせることで、テレビ風のテロップを入れた動画を生成されています。
ChatGPT Images 2.0 × Gemini Omni Flash
— GENEL | AIを用いた動画制作 (@genel_ai) May 22, 2026
AIでテレビ風のテロップも生成可能
実際に使用したプロンプトはこちらの記事で紹介しています。 https://t.co/EsgR9Yv6gr pic.twitter.com/eiynv2TOsj

このようなテロップを簡単に入れられるようになると、ショート動画などが作りやすくなるのではないでしょうか。
人物変更
こちらの動画では元素材に写っている人物を別の人物に置換して動画を生成しています。
人物を置き換えているだけなので、動きは非常にリアリティがあり、生成AIで作ったとは思えない完成度です。
【課題別】Gemini Omni Flashが解決できること
Gemini Omni Flashが解決できる代表的な課題を紹介します。従来の動画制作では対応が難しかった課題に対して、どのようにアプローチできるかを見ていきます。
専門ソフトなしで動画を修正できる
従来の動画編集では、専門ソフトの操作スキルが必要でした。Gemini Omni Flashなら、自然言語で話しかけるだけで動画を修正できるため、編集の専門知識がなくても思いどおりの映像に近づけられます。
会話型編集によって、非エンジニア・非デザイナーでも動画制作に参加しやすくなる点が挙げられます。
動画制作のコストと時間を抑えられる
動画1秒あたり$0.10という料金で、反復的な制作を低コストで回せます。数日かかっていた制作サイクルを数分に短縮した事例もあり、時間面でのメリットも大きいといえるでしょう。
短期間で複数パターンの動画を検証したいマーケティング用途とも相性が良い点が特徴です。
画像から動画までを一気通貫で作れる
画像モデルNano Banana 2 Liteと組み合わせることで、画像生成から動画化までを1つのワークフローで構築できます。Nano Banana 2 Liteで高速に画像を生成し、その画像を参照としてGemini Omni Flashで動画化する流れです。
| 課題 | 解決できること | 現時点での限界 |
|---|---|---|
| 編集の専門性 | 自然言語で動画を修正できる | 複雑な演出は試行錯誤が必要 |
| コスト・時間 | 1秒$0.10で反復制作できる | 現時点で1本10秒までの尺 |
| 制作フローの分断 | 画像生成〜動画化を一気通貫にできる | 音声リファレンスは未対応 |
Gemini Omni Flashのよくある質問
ここではGemini Omni Flashのよくある質問について回答していきます。Gemini Omni Flashの使用を検討している場合には、ぜひ参考にしてみてください。
Gemini Omni Flashで動画制作を加速しよう
Gemini Omni Flashは、Geminiのマルチモーダル推論を動画生成・編集に応用した、高品質かつ低コストなAIモデルです。テキスト・画像・動画を組み合わせ、自然言語での会話型編集によって映像を仕上げられます。
単に動画を一発生成するだけのモデルではなく、対話しながら少しずつ理想へ近づけていける点が本質的な価値といえるでしょう。1秒あたり$0.10という価格も、反復前提のクリエイティブ制作を後押しします。
今後は動画の尺の拡張や音声リファレンス対応が進み、動画制作におけるAI活用の裾野はさらに広がっていくでしょう。画像モデルNano Banana 2 Liteとの連携によって、画像から動画までを一気通貫で作る体験も一般的になっていくと考えられます。
ぜひ皆さんも本記事を参考にGemini Omni Flashを使ってみてください!

最後に
いかがだったでしょうか?
Gemini Omni Flashを活用することで、動画の生成から編集までを対話的かつ低コストに進められます。一方で、パブリックプレビュー段階ゆえの制約は設計次第で効果が大きく変わるため、まずは小規模な検証から始めて自社に合った使い方を見極めることも重要な選択肢です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

