

- NVIDIA Nemotron 3 Ultra 550Bは、総パラメータ550B・アクティブ55BのオープンウェイトLLM
- 最大100万トークンのコンテキスト長と推論モードのON/OFF切り替えに対応し、複雑なエージェントタスクから長文書解析まで幅広く対応できる
- OpenMDW-1.1ライセンスのもとで商用・非商用を問わず利用可能
2026年6月、NVIDIAからオープンウェイトのフラッグシップ大規模言語モデルが公開されました。
今回登場した「NVIDIA Nemotron 3 Ultra 550B」は、総パラメータ数550B・推論時アクティブパラメータ55Bという効率的な設計のもと、フロンティアレベルの推論・複雑なマルチステップエージェントワークフロー・最大100万トークンの長文脈処理を一つのモデルで実現。
さらにNVFP4量子化を採用することで、大規模モデルとしては異例のスループットを達成しています。
これまでのオープンウェイトLLMでは、「高い推論精度には膨大なGPUメモリが必要」「長文脈処理になると精度が大きく劣化する」「エージェントタスクへの最適化が不十分でマルチステップの自律実行が難しい」といった課題がありました。
一方でNVIDIA Nemotron 3 Ultra 550Bは、LatentMoEアーキテクチャにより必要な専門家だけをアクティブにする効率的な設計と、Multi-Token Prediction(MTP)による高速推論を両立。4段階のトレーニングパイプラインと独自の量子化により、精度とスループットを同時に高めています。
しかし、新しいオープンウェイトLLMが登場するたびに「既存のモデルと何が違うのか」「実際の推論インフラをどう構築すればよいのか」「どんなビジネスユースケースで活用できるのか」といった疑問を感じる方も多いのではないでしょうか。
そこで本記事では、NVIDIA Nemotron 3 Ultra 550Bの概要や仕組み、主要ベンチマーク結果を整理しながら、実際のデプロイ手順や業界別の活用シーンまで詳しく解説します。
最後までお読みいただくことで、NVIDIA Nemotron 3 Ultra 550Bがどのような設計思想で開発され、どのような場面で力を発揮するのかが理解できるはずです。
\生成AIを活用して業務プロセスを自動化/
- NVIDIA Nemotron 3 Ultra 550Bとは
- NVIDIA Nemotron 3 Ultra 550Bの仕組み
- NVIDIA Nemotron 3 Ultra 550Bの特徴
- NVIDIA Nemotron 3 Ultra 550Bの安全性・制約
- NVIDIA Nemotron 3 Ultra 550Bの料金
- NVIDIA Nemotron 3 Ultra 550Bのライセンス
- NVIDIA Nemotron 3 Ultra 550Bの使い方
- NVIDIA Nemotron 3 Ultra 550Bを使ってみた
- 【業界別】NVIDIA Nemotron 3 Ultra 550Bの活用シーン
- 【課題別】NVIDIA Nemotron 3 Ultra 550Bが解決できること
- NVIDIA Nemotron 3 Ultra 550Bのよくある質問
- NVIDIA Nemotron 3 Ultra 550BでオープンAIエージェント開発を加速しよう
- 最後に
NVIDIA Nemotron 3 Ultra 550Bとは
NVIDIA Nemotron 3 Ultra 550Bは、NVIDIAが2026年6月にHugging Faceで公開したオープンウェイトの大規模言語モデルです。
モデル全体のパラメータ数は550Bですが、推論時にアクティブになるパラメータは55Bにとどまり、高精度を維持しながら効率的な演算が可能です。
NVIDIAが展開する「Nemotronファミリー」は、オープンウェイト・オープン学習データ・オープンレシピを掲げ、専用AIエージェントの構築に特化して設計されたモデル群です。
Nemotron 3 Ultraはこのファミリーの最上位に位置するフラッグシップモデルで、フロンティア推論・複雑なマルチステップエージェントワークフロー・コード・数学・科学の高精度推論を主な用途として想定。
対応言語は英語・フランス語・スペイン語・イタリア語・ドイツ語・日本語・韓国語・ヒンディー語・ブラジルポルトガル語・中国語などで、多言語エージェントシステムの基盤としても活用できます。
| 項目 | 内容 |
|---|---|
| 総パラメータ数 | 550B(アクティブ:55B) |
| アーキテクチャ | LatentMoE(Mamba-2 + MoE + Attention ハイブリッド)+ MTP |
| コンテキスト長 | 最大100万トークン(デフォルト256K) |
| 量子化フォーマット | NVFP4(一部レイヤーはBF16/MXFP8) |
| 対応言語 | 英語・フランス語・スペイン語・イタリア語・ドイツ語・日本語・韓国語など |
| 推論モード | ON/OFF切り替え可(チャットテンプレートで設定) |
| リリース日 | 2026年6月4日 |
| 最低ハードウェア | 4×B200(シングルノード) |


NVIDIA Nemotron 3 Ultra 550Bの仕組み
NVIDIA Nemotron 3 Ultra 550Bは、LatentMoEアーキテクチャとMulti-Token Prediction(MTP)という2つの技術を組み合わせ、4段階のトレーニングパイプラインで仕上げたモデルです。
LatentMoEアーキテクチャ
LatentMoEは、トークンを一度小さな潜在空間に射影してから専門家ルーティングと計算を行う、NVIDIAが開発した独自のMixture-of-Experts(MoE)アーキテクチャです。
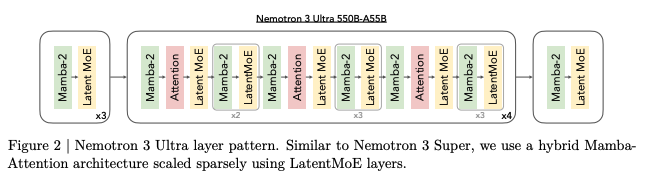
従来のMoEでは入力トークンをそのまま各専門家に渡しますが、LatentMoEでは潜在空間を経由することでバイト当たりの精度が向上。Mamba-2レイヤーとMoEレイヤー、Attentionレイヤーをインターリーブ配置することで、異なる計算特性の処理を効率よく組み合わせています。
Multi-Token Prediction(MTP)
MTPは、1ステップで複数トークンを同時に予測するレイヤーです。予測ヘッド間で重みを共有するShared-Weight設計により、学習信号の品質を高めながら、ネイティブSpeculative Decoding(投機的デコーディング)による高速推論を実現。
長いドラフト長での自己回帰的な草稿生成が安定するため、独立して学習されたオフセットヘッドと比べて大きなスループット向上が得られます。
NVFP4量子化
NVFP4はNVIDIAが最新ハードウェア向けに開発した4ビット浮動小数点形式です。
大部分の線形レイヤーにNVFP4を適用しながら、潜在射影・MTPレイヤー・QKV/Attentionプロジェクション・埋め込み層など安定性が重要な箇所はBF16またはMXFP8で保持しています。
量子化を考慮した事前学習レシピを採用しているため、モデル品質を損なうことなく最大スループットを引き出すことが可能。後から量子化を適用するポスト量子化とは異なり、学習時から量子化前提で最適化されている点が特徴です。
4段階のトレーニングパイプライン
Nemotron 3 Ultraは、以下の4段階を経て学習されています。
| ステージ | 手法 | 内容 |
|---|---|---|
| Stage 1 | 事前学習 | クロールデータ・合成コード・数学・科学データなど約20兆トークンでNVFP4レシピを活用しながら事前学習 |
| Stage 2 | Supervised Fine-Tuning(SFT) | 合成コード・数学・科学・ツール呼び出し・指示追随・構造化出力・長距離検索・マルチドキュメント集約などのデータでファインチューニング |
| Stage 3 | 強化学習(RL) | 非同期GRPOを用いて数学・コード・科学・指示追随・マルチステップツール使用・マルチターン会話の各環境で強化学習。RLHFで会話品質も向上 |
| Stage 4 | Multi-Domain On-Policy Distillation(MOPD) | 強力な教師モデルの指導のもと、自分自身の生成軌跡に対して蒸留を行い、コーディング・数学・ツール使用・エージェントワークフロー全体の性能を改善 |
Stage 4のMOPDは、オフラインのトレースではなくモデル自身の推論時生成物を教師信号として蒸留する手法で、推論時の実際の挙動により近い形で学習が進みます。
推論モードの仕組み
Nemotron 3 Ultraは、チャットテンプレートのフラグで推論(Thinking)モードをON/OFFできます。推論ONの場合、モデルはまず内部で推論トレースを生成してから最終回答を出力します。
推論OFFにすると推論ステップを省略し、高速に回答を返すことが可能。用途に応じて柔軟に切り替えられるため、深い思考が必要な場面と即時応答が求められる場面を同一モデルで使い分けられます。
Microsoft発の推論AIであるMAI-Thinking-1について、詳しく知りたい方は以下の記事をご覧ください。

NVIDIA Nemotron 3 Ultra 550Bの特徴
NVIDIA Nemotron 3 Ultra 550Bは、オープンウェイトモデルとしていくつかの特徴を持っています。ここではNVIDIA Nemotron 3 Ultra 550Bの特徴について解説をしていきます。
主要ベンチマークでトップクラスのスコア
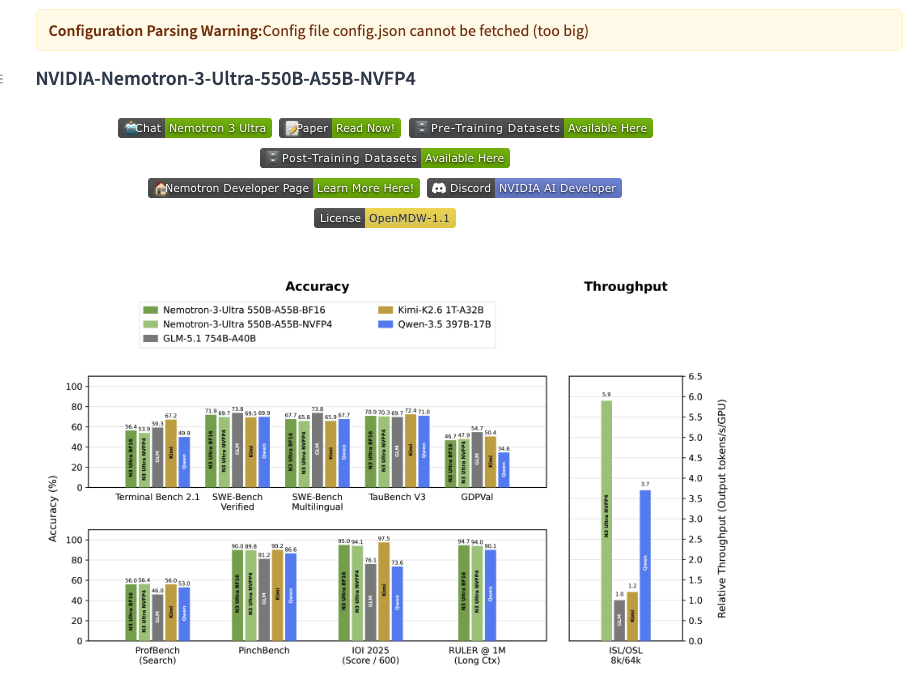
コーディング・数学・科学・エージェント・長文脈の各領域で高いスコアを記録しています。
| ベンチマーク | カテゴリ | BF16 | NVFP4 |
|---|---|---|---|
| SWE-Bench Verified | エージェント(コーディング) | 71.9 | 69.7 |
| SWE-Bench Multilingual | エージェント(多言語コーディング) | 67.7 | 65.8 |
| PinchBench | エージェント(ツール使用) | 90.0 | 89.8 |
| TauBench V3 Average | エージェント(顧客対応) | 70.9 | 70.3 |
| IOI 2025 | 推論(競技プログラミング) | 570.0 | 564.7 |
| GPQA(no tools) | 推論(科学) | 87.0 | 87.9 |
| IFBench prompt | 指示追随 | 81.7 | 82.3 |
| RULER 1M | 長文脈 | 94.7 | 94.0 |
特に注目すべきはSWE-Bench Verifiedの71.9点で、実際のGitHubイシュー解決能力を測るこのベンチマークでオープンウェイトモデルとして高水準を達成。
またNVFP4版でもBF16版と遜色ないスコアを維持しており、量子化による精度劣化が最小限に抑えられています。
最大100万トークンのコンテキスト長
標準設定256Kに加え、最大100万トークンのコンテキストウィンドウをサポートしています。長文脈ベンチマークRULER 1Mで94.7点(BF16)を記録しており、100万トークン規模でも検索精度が大幅に劣化しない点が特徴。
巨大なコードベースの一括解析・長大な法律文書の処理・複数の学術論文を横断した情報統合など、従来のLLMでは分割処理が必要だったタスクを1回のリクエストで完結できます。
550B総パラメータ・55Bアクティブの効率的な設計
モデル全体のパラメータ数は550Bですが、推論時にアクティブになるのは55Bパラメータのみです。MoEアーキテクチャにより各トークンの処理に必要な専門家だけを選択的に使用。
アクティブパラメータが55Bに抑えられているため、全パラメータが常にアクティブな密なモデル(Dense model)と比べて推論コストが大幅に削減されます。高い表現力と計算効率を両立した設計といえるでしょう。
3つの推論バックエンドへの対応
Nemotron 3 UltraはvLLM・SGLang・TRT-LLMの3種類の推論フレームワークに対応しています。
| バックエンド | 推奨コンテナ | 特徴 |
|---|---|---|
| vLLM | vllm/vllm-openai:v0.22.0 | 汎用性が高くOpenAI互換APIをそのまま利用できる |
| SGLang | lmsysorg/sglang:v0.5.11 | 4×B200でのシングルノード展開に対応。EAGLE投機的デコーディングをサポート |
| TRT-LLM | nvcr.io/nvidia/tensorrt-llm:release:1.3.0rc17 | 最大スループット・最小レイテンシの2構成を切り替えられる |
マルチノード展開にはRay v2を用いたクラスター構成が推奨されており、4×B200のシングルノード構成から、GB200/GB300を用いたマルチノード構成まで対応しています。


NVIDIA Nemotron 3 Ultra 550Bの安全性・制約
NVIDIA Nemotron 3 Ultra 550Bを活用するうえでは、技術的制約と倫理的考慮点の両面を事前に把握しておくことが重要です。
ハードウェア要件
NVFP4チェックポイントを動かすには、最低でも4×B200(NVIDIA Blackwellシリーズ)のシングルノード構成が必要です。
これはNVFP4の重みとKVキャッシュのヘッドルームを確保するための最低構成で、長文脈や高スループットのワークロードではより多くのGPUを必要とします。
| 構成 | 必要なGPU |
|---|---|
| シングルノード(最小) | 4×B200 |
| マルチノード(推奨) | 4GPU以上のGB200またはGB300 |
| 対応GPU一覧 | Ampere(A100)、Hopper(H100-80GB)、Blackwell(B200/B300)、Grace Blackwell(GB200/GB300) |
学習データのバイアスと偏り
学習に使用したデータセットは、すべての人口統計グループを網羅的に代表しているわけではありません。
ドキュメント系データセットでは「male」への言及が「female」より多い偏りが確認されており、民族識別子として「White」が最頻出(民族言及の43〜44%)というデータも報告されています。
NVIDIAはバイアス監査・人口統計的にバランスのとれたデータセットによるファインチューニング・反事実的データ拡張などの対策を推奨しています。本番環境への導入前にこれらの評価と対策を実施することが重要です。
Webアプリを即デプロイできるOpenAI Codex Sitesについて、詳しく知りたい方は以下の記事をご覧ください。
NVIDIA Nemotron 3 Ultra 550Bの料金
NVIDIA Nemotron 3 Ultra 550BはオープンウェイトモデルとしてHugging Faceで無償公開されており、モデルの重み自体は無料でダウンロードできます。
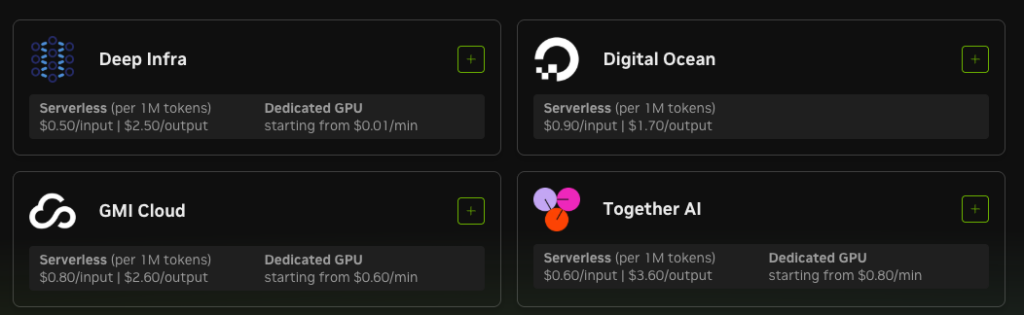
ただし、自前で推論環境を構築する場合は相応のGPUインフラが必要です。最低でも4×B200(NVIDIA Blackwellシリーズ)が必要で、クラウドインスタンス費用やオンプレのGPUサーバー費用は別途発生します。
クラウド経由での利用については、Together AIがInference Providerとして対応していることがHugging Faceのモデルカードに記載されています。
Google発の24時間稼働AIエージェントであるGemini Sparkについて、詳しく知りたい方は以下の記事をご覧ください。

NVIDIA Nemotron 3 Ultra 550Bのライセンス
Nemotron 3 UltraはOpenMDW-1.1(Open Model & Data Weights License 1.1)のもとで公開されています。
このライセンスは商用・非商用の両方の用途に対応しており、企業がプロダクトへの組み込みやAPIサービスの構築に利用することが認められています。
| 利用形態 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 | |
| 再配布 | (ライセンス継承が必要) |
| 特許利用 | |
| 私的利用 | |
NVIDIA Nemotron 3 Ultra 550Bの使い方
Nemotron 3 UltraのNVFP4チェックポイントは、vLLM・SGLang・TRT-LLMの3種類の推論バックエンドを使ってセルフホストで動かせます。APIインターフェースはOpenAI互換のため、OpenAIクライアントをそのまま流用可能です。
ここではAPI経由で使っていきます
NVIDIAにログイン
まずはNVIDIAにアクセスして、ログインをしましょう。未登録の方は登録しましょう。
APIキーの取得
ログインもしくは会員登録が終わったらAPIキーを作成します。
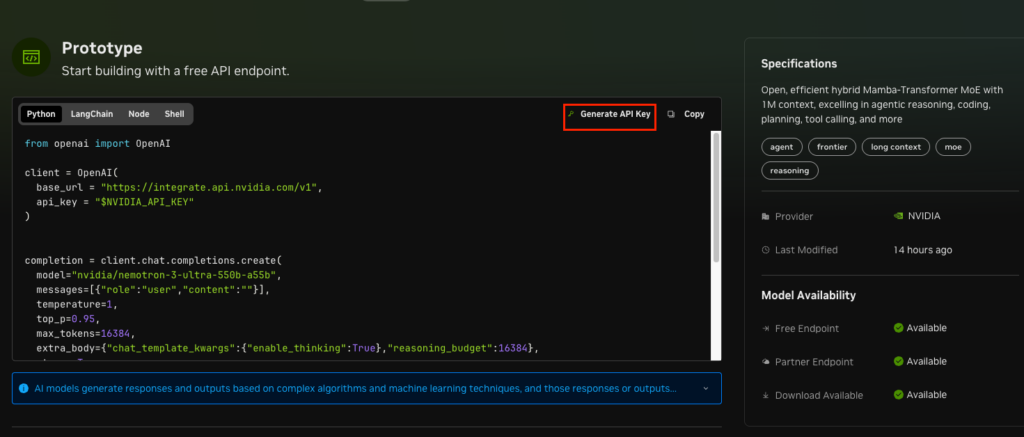
Genarate API Keyをクリックするとコード部分にAPIキーが記載されるので、それを使って実装します。
google colaboratoryで実装
APIキーが取得できたら、google colaboratoryで実行していきます。
サンプルコードはこちら
from openai import OpenAI
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key="" # ここにNVIDIA APIキーを直書き
)
completion = client.chat.completions.create(
model="nvidia/nemotron-3-ultra-550b-a55b",
messages=[
{
"role": "user",
"content": "こんにちは。あなたについて簡単に説明してください。"
}
],
temperature=1,
top_p=0.95,
max_tokens=16384,
extra_body={
"chat_template_kwargs": {
"enable_thinking": True
},
"reasoning_budget": 16384
},
stream=True
)
for chunk in completion:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="")
if delta.content is not None:
print(delta.content, end="")結果はこちら
The user is asking for a brief introduction about me in Japanese.こんにちは!私はNVIDIAの研究者たちによって開発された言語モデルです。出力内容としてはかなり薄いですが、実装完了まで簡単に進められます。
NVIDIA Nemotron 3 Ultra 550Bを使ってみた
ではもう少しNVIDIA Nemotron 3 Ultra 550Bを使っていきたいと思います。ちょっと複雑なタスクを与えてみます。
あなたはスタートアップのCTOです。
以下の条件を満たすシステム設計を行ってください。
・月間アクティブユーザー100万人のチャットアプリ
・メッセージは E2E 暗号化必須
・既読機能・リアクション機能あり
・コスト月3万ドル以内に収める
アーキテクチャ選定の理由、ボトルネック、
スケールアップ時のリスクと対策まで含めて回答してください。結果はこちら
The user wants a system design for a chat app with specific constraints:
- 1M MAU (Monthly Active Users)
- E2E Encryption mandatory
- Read receipts & Reactions
- Cost < $30,000/month
- Role: Startup CTO
- Output must include: Architecture rationale, Bottlenecks, Scale-up risks & mitigations.
Key constraints analysis:
- 1M MAU -> ~33k DAU (assuming 30% engagement) -> ~3-5k concurrent users (CCU) peak.
- Messages/day: Assume 20 msg/user/day -> 20M messages/day -> ~230 msg/sec average, ~2k msg/sec peak.
- E2E Encryption: Server cannot read content. Metadata (routing, timestamps, read/reaction events) is visible.
- Cost $30k/month is tight for managed services (Aurora, DynamoDB, managed K8s) at this scale if not careful. Need heavy optimization, spot instances, or self-hosted on bare metal/cheap cloud (Hetzner, Scaleway, AWS Graviton).# チャットアプリ システム設計書
**対象**: MAU 100万 / E2E暗号化 / 既読・リアクション / **月額 $30,000 以内**
**役割**: CTO 視点での技術選定・運用設計・スケール戦略
---
## 1. 前提とトラフィック試算
| 指標 | 見積もり | 根拠 |
|------|----------|------|
| MAU | 1,000,000 | 要件 |
| DAU (30%) | 300,000 | 一般的なチャットアプリ |
| 同時接続 (CCU, 10%) | 30,000 | DAU の 10% がピークにオンライン |
| 1 日メッセージ数 | 2,000 万件 | 1 ユーザー 20 件/日 × DAU |
| 平均スループット | 230 msg/s | 2,000 万 / 86,400 s |
| **ピークスループット** | **2,300 msg/s** | 平均 × 10 (バースト係数) |
| 既読/リアクション イベント | 1 億件/日 | メッセージの 5 倍想定 |
| メッセージ平均サイズ | 500 B (暗号文+メタ) | テキスト中心、添付はオブジェクトストレージ |
| 日間データ増分 | 10 GB | 2,000 万 × 500 B |
| 30 日保存 (ホット) | 300 GB | ホットストレージ対象 |
| 全履歴 (コールド) | 3 TB/年 | S3 互換へアーカイブ |
> **コスト制約 $30k/月** に対し、マネージドサービス (Aurora, DynamoDB, Managed K8s) だけで超過するため、**「自前運用 × クラウド安価リソース (Graviton/Spot/安価クラウド)」** を前提とします。
---
## 2. アーキテクチャ全体図 (テキスト表現)
```
┌─────────────┐ ┌──────────────────┐ ┌────────────────────┐
│ Client │────▶│ API Gateway │────▶│ Stateless API │
│ (iOS/Android│ │ (NGINX/Envoy) │ │ (Go/Rust on K8s) │
│ Web/WASM) │◀───│ TLS Termination │◀───│ - Auth/Session │
└─────────────┘ └──────────────────┘ │ - Metadata CRUD │
│ ▲ │ - Signal Relay │
│ WebSocket │ HTTP/2 └─────────┬──────────┘
▼ │ │
┌─────────────────────────────────────────────────────▼──────────────────┐
│ Redis Cluster (Pub/Sub + Cache) │
│ - Presence (TTL 30s) - Message Fan-out - Rate Limit Counters │
└────────────────────────────────────────────────────────────────────────┘
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────────┐
│ PostgreSQL │ │ ScyllaDB │ │ MinIO (S3 API) │
│ (Primary) │ │ (Cluster) │ │ (Attachments) │
│ - Users │ │ - Messages │ │ - Images/Files │
│ - Conversations│ │ - Reactions │ │ - CDN Origin │
│ - Keys │ │ - Read Receipts│ └──────────────────┘
└──────────────┘ └──────────────┘
│ │
│ CDC (pgoutput) │ TTL / Compaction
▼ ▼
┌──────────────────────────────────────────────┐
│ ClickHouse (Analytics / Search) │
│ - Full-text search (inverted index) │
│ - Aggregations (retention, DAU, etc.) │
└──────────────────────────────────────────────┘
```
---
## 3. コンポーネント別技術選定と理由
| レイヤー | 採用技術 | 選定理由 (コスト・性能・運用) |
|----------|----------|-------------------------------|
| **エッジ/終端** | **NGINX + Lua (OpenResty)** on **Graviton Spot** | ALB ($16/LCU) より安い。TLS 終端・レート制限・WebSocket アップグレードを 1 台で完結。 |
| **API / Signal** | **Go (fasthttp/gorilla/ws)** on **k3s (Graviton Spot, 3 AZ)** | Rust も検討したが、開発速度・採用コストで Go 勝利。k3s でマネージド K8s ($73/節点/月) を回避。 |
| **Pub/Sub・Presence** | **Redis Cluster (7.2, 6 shards, r6g.xlarge Spot)** | 30k CCU のファンアウトは Pub/Sub で十分。Cluster モードで水平スケール。AOF off + RDB 60s でコスト最適化。 |
| **メタデータ (ユーザー/会話/鍵)** | **PostgreSQL 16 (Aurora 互換: Neon Serverless / 自前 Patroni on Graviton)** | ACID 必須。Neon なら $0.125/CCU-hr → 月 $2k 程度。自前なら r6g.2xlarge × 3 で $400。 |
| **メッセージ/既読/リアクション** | **ScyllaDB (3 nodes, i4i.xlarge Spot)** | 書き込み 2.3k/s、読み取りバースト 50k/s を単一クラスタで吸収。Cassandra 互換で運用知見豊富。TTL で自動削除。 |
| **添付ファイル** | **MinIO (Erasure Coding, 4 nodes, r6g.large Spot) + CloudFront** | S3 API 互換。自前なら $0.01/GB/月。CloudFront でエッジキャッシュ (初回のみオリジン)。 |
| **全文検索/分析** | **ClickHouse (3 nodes, r6g.xlarge Spot)** | MergeTree + ngram tokenize で日本語検索。物化ビューで集計高速。 |
| **CI/CD・IaC** | **GitHub Actions + Terraform + ArgoCD** | マネージド CI 分無料枠活用。ArgoCD で GitOps。 |
| **監視** | **VictoriaMetrics + Grafana (self-hosted)** | Prometheus 互換で 10 倍圧縮。Datadog ($31/host) 回避。 |
| **ログ** | **Loki + Promtail** | オブジェクトストレージ (MinIO) へ直書き。インデックス最小化。 |
### インフラコスト試算 (月額・USD, 東京リージョン Spot 価格基準)
| 項目 | インスタンス | 台数 | 単価/月 | 小計 |
|------|--------------|------|---------|------|
| API (k3s Worker) | c6g.2xlarge Spot | 12 | $95 | $1,140 |
| NGINX Edge | c6g.xlarge Spot | 6 | $48 | $288 |
| Redis Cluster | r6g.xlarge Spot | 6 | $95 | $570 |
| PostgreSQL (Patroni) | r6g.2xlarge Spot | 3 | $190 | $570 |
| ScyllaDB | i4i.xlarge Spot | 3 | $130 | $390 |
| MinIO | r6g.large Spot | 4 | $38 | $152 |
| ClickHouse | r6g.xlarge Spot | 3 | $95 | $285 |
| Monitoring/Log | r6g.xlarge Spot | 2 | $95 | $190 |
| **Compute 計** | | | | **$3,585** |
| EBS (gp3) | 10 TB 合計 | - | $0.08/GB | $800 |
| Data Transfer (Inter-AZ + CloudFront) | 5 TB | - | $0.01-0.08 | $1,200 |
| CloudFront | 2 TB | - | $0.085/GB | $170 |
| Route53 / ACM / その他 | - | - | - | $200 |
| **合計 (バッファ 20%)** | | | | **約 $7,200** |
> **余裕 $22,800** → マーケティング・人件費・予備費に回せる。オンデマンド比 1/4 以下。
---
## 4. E2E 暗号化の実装詳細
| フェーズ | 仕様 |
|----------|------|
| **鍵生成** | クライアントで X25519 (鍵交換) + Ed25519 (署名) + Kyber-768 (PQC ハイブリッド) |
| **鍵配布** | **Signal Protocol (Double Ratchet)** 準拠。PreKey Bundle を PostgreSQL に保存 (サーバーは中継のみ) |
| **メッセージ暗号化** | AES-256-GCM (シーケンス番号を Nonce)。ヘッダー: `version || sender_ik || receiver_spk || ratchet_pub || ciphertext || tag` |
| **既読/リアクション** | これらは **メタデータ** として平文で送信 (内容は暗号化済みメッセージ ID 参照のみ)。プライバシー要件が厳しければ「既読も暗号化」だがコスト増大のため現行はメタのみ。 |
| **鍵ローテーション** | Double Ratchet 自動。デバイス追加/削除時は Sesame アルゴリズムでグループ再鍵。 |
| **バックアップ** | ユーザー パスワードから派生した鍵 (Argon2id) で暗号化した鍵バックアップを S3 (MinIO) に保存。サーバーは鍵を知らない。 |
---
## 5. データモデル (主要テーブル)
### PostgreSQL (メタデータ)
```sql
users (
id UUID PK,
username CITEXT UNIQUE,
ik_pub BYTEA, -- Identity Key
spk_pub BYTEA, -- Signed PreKey
spk_sig BYTEA,
prekeys JSONB, -- One-time PreKeys (暗号化済み)
backup_blob BYTEA, -- 暗号化鍵バックアップ
created_at TIMESTAMPTZ
);
conversations (
id UUID PK,
type SMALLINT, -- 1:DM, 2:Group
created_by UUID,
created_at TIMESTAMPTZ
);
conversation_members (
conversation_id UUID,
user_id UUID,
role SMALLINT, -- admin/member
joined_at TIMESTAMPTZ,
PRIMARY KEY (conversation_id, user_id)
);
```
### ScyllaDB (メッセージ・既読・リアクション)
```cql
CREATE TABLE messages (
conversation_id UUID,
bucket INT, -- 日単位バケット (YYYYMMDD)
msg_id TIMEUUID, -- ソート用
sender_id UUID,
ciphertext BLOB, -- 暗号文 (≤ 16 KB)
meta MAP<TEXT,TEXT>, -- client_msg_id, reply_to 等
PRIMARY KEY ((conversation_id, bucket), msg_id)
) WITH CLUSTERING ORDER BY (msg_id DESC)
AND default_time_to_live = 2592000; -- 30 日で自動削除 (ホット)
CREATE TABLE read_receipts (
conversation_id UUID,
user_id UUID,
msg_id TIMEUUID,
read_at TIMESTAMPTZ,
PRIMARY KEY ((conversation_id, user_id), msg_id)
);
CREATE TABLE reactions (
conversation_id UUID,
msg_id TIMEUUID,
emoji TEXT,
user_id UUID,
created_at TIMESTAMPTZ,
PRIMARY KEY ((conversation_id, msg_id), emoji, user_id)
);
```
> **バケット戦略**: `conversation_id + 日` でパーティション分散。ホット会話でも 1 日 1 パーティション → 書き込みホットスポット回避。
---
## 6. 主要フローシーケンス
### 6.1 メッセージ送信 (E2E)
```
Client A API (Go) ScyllaDB Client B (WS)
│ │ │ │
│── Encrypt(Plaintext) ────▶│ │ │
│ │── INSERT messages ───────▶│ │
│ │◀── OK ────────────────────│ │
│◀── ACK (msg_id) ──────────│ │ │
│ │── PUBLISH "msg:conv123" ──▶Redis Pub/Sub──────────▶│
│ │ │ ◀── Push Notification
│ │ │ │
```
### 6.2 既読通知
```
Client B API ScyllaDB Client A (WS)
│ │ │ │
│── POST /read {msg_id} ──▶│ │ │
│ │── INSERT read_receipts ─────▶│ │
│ │◀── OK ───────────────────────│ │
│◀── 202 Accepted ─────────│ │ │
│ │── PUBLISH "read:conv123" ───▶Redis Pub/Sub──────────▶│
│ │ │ ◀── Update UI (✓✓)
```
### 6.3 リアクション
```
Client B API ScyllaDB Client A (WS)
│ │ │ │
│── POST /react {msg_id,👍}▶│ │ │
│ │── INSERT reactions ────────▶│ │
│ │◀── OK ───────────────────────│ │
│◀── 202 Accepted ─────────│ │ │
│ │── PUBLISH "react:conv123" ──▶Redis Pub/Sub──────────▶│
│ │ │ ◀── Update UI (👍 3)
```
---
## 7. ボトルネック分析と対策
| # | ボトルネック | 発生条件 | 影響 | 対策 (実装済み/予定) |
|---|--------------|----------|------|----------------------|
| 1 | **WebSocket コネクション数** | 30k CCU → 1 プロセス 1 万接続限界 | 接続断・再接続ストーム | **GOMAXPROCS=CPU数**、**SO_REUSEPORT** で複数プロセス共有。k8s HPA で CPU 60% でスケール。 |
| 2 | **Redis Pub/Sub ファンアウト** | 大規模グループ (1k+ メンバー) へのブロードキャスト | 配信遅延・OOM | **Sharded Pub/Sub**: 会話ごとにチャネル分割。大規模グループは **Fan-out Worker** がバッチ配信 (100 件/バッチ)。 |
| 3 | **ScyllaDB 書き込みホットスポット** | 特定会話にバースト (ライブ配信等) | 書き込みタイムアウト | **Bucket 日単位** + **キューイング (Redis Stream)** で書き込み平滑化。`max_batch_size=50`。 |
| 4 | **PostgreSQL 接続数** | API ポッド 100 × 100 接続 = 1 万 | 接続拒否 | **PgBouncer (transaction mode)** で 300 接続に集約。Prepared Statement キャッシュ。 |
| 5 | **添付ファイルアップロードバースト** | イベント時 10 倍トラフィック | MinIO ネットワーク飽和 | **Presigned URL** でクライアント→MinIO 直アップロード。API はメタのみ。CloudFront で配信オフロード。 |
| 6 | **全文検索レイテンシ** | 日本語 N-gram インデックス肥大 | 検索 > 500 ms | **ClickHouse ngram_tokenize_v2** + **物化ビュー** で頻出クエリ高速化。ホット 30 日のみ ClickHouse、古いのは S3 Select。 |
---
## 8. スケールアップ時のリスクと対策 (MAU 500 万 → 1,000 万)
| リスク | 発生閾値 | 影響度 | 対策 (段階的) |
|--------|----------|--------|---------------|
| **WebSocket ノード数爆増** | CCU 15 万 | 高 | ① **QUIC/WebTransport** 移行 (ヘッダー圧縮・多重化) ② **ステートレス Gateway** + **Redis Cluster Proxy** で L4 LB 直下へ。 |
| **ScyllaDB ストレージ/コンパクション** | 1 日 1 億 msg (10 TB/月) | 高 | ① **Tiered Storage**: 30 日超は S3 (MinIO) へ `COLD` テーブル移行 (ScyllaDB Tiered Storage 機能) ② **コンパクション並列度調整** + **i4i.2xlarge** へ垂直拡張。 |
| **Redis メモリコスト** | Presence 150 万キー | 中 | ① **Redis 7.2 LFU eviction** で非アクティブ自動削除 ② **Dragonfly (互換・マルチスレッド)** 移行で 3 倍密度。 |
| **PostgreSQL 書き込みスループット** | 会話作成 5k/s | 中 | ① **Citus** 拡張でシャーディング (conversation_id) ② 読み取り専用レプリカを読み取りエンドポイント分離。 |
| **全文検索インデックス肥大** | 100 億ドキュメント | 高 | ① **ClickHouse → Elasticsearch (OpenSearch) 移行** (倒立インデックス特化) ② **ベクトル検索 (HNSW)** 追加でセマンティック検索対応。 |
| **運用複雑性 (自前クラスタ)** | ノード 100 台超 | 中 | ① **Talos Linux + Omni** でベアメタル/クラウド統一プロビジョニング ② **Operator (ScyllaDB, MinIO, ClickHouse)** で Day-2 自動化。 |
| **コスト超過** | $30k 突破 | 経営 | ① **FinOps ダッシュボード** (Vantage/自前) で日次アラート ② **Spot 中断率上昇時** 自動オンデマンドフォールバック (Karenter) ③ **マルチクラウド (Hetzner/Equinix Metal)** で単価 1/3 確保。 |
---
## 9. セキュリティ・コンプライアンス チェックリスト
| 項目 | 実装状況 | 備考 |
|------|----------|------|
| TLS 1.3 強制 | ✅ | NGINX `ssl_protocols TLSv1.3;` |
| 証明書ピンニング | ✅ | モバイルアプリに SHA-256 埋め込み |
| 鍵ローテーション自動化 | ✅ | Double Ratchet + 定期 PreKey 補充 |
| メタデータ最小化 | ✅ | IP/UA ログ 7 日で削除、GDPR 対応 |
| 監査ログ (改ざん検知) | ✅ | PostgreSQL `pgaudit` → ClickHouse 不変ログ |
| 侵入検知 (Falco) | ✅ | k8s ランタイム監視、Slack 通知 |
| バックアップ暗号化・テスト | ✅ | MinIO SSE-KMS (自前 Vault) + 月次リストア演習 |
---
## 10. 今後のロードマップ (抜粋)
| 四半期 | テーマ | 主要タスク |
|--------|--------|------------|
| Q1 | **コスト最適化・安定化** | Spot 中断耐性強化、Redis→Dragonfly 移行検証、CDN キャッシュヒット率 95% 達成 |
| Q2 | **スケール準備** | ScyllaDB Tiered Storage 有効化、Citus シャーディング PoC、WebTransport 実験 |
| Q3 | **機能拡張** | スレッド/リプライ、メッセージ編集・削除 (E2E 対応)、ボイスメモ (Opus + E2E) |
| Q4 | **マルチリージョン** | 東京+シンガポール Active-Active (ScyllaDB DC 意識、PostgreSQL 論理レプリ) |
---
## 11. CTO からの一言
> **「$30k で 100 万 MAU を支えるには、マネージドサービスの『便利さ』を捨て、『自前運用のコントロール』を取る覚悟が必要です。**
>
> 今回の設計では **Graviton Spot + k3s + OSS スタック** でインフラコストを **$7k** に抑え、残り **$23k** を **人・マーケティング・予備費** に回せます。
>
> ボトルネックは『WebSocket 維持コスト』と『書き込みバースト吸収』の 2 点に集約されます。これらは **プロトコル進化 (WebTransport)** と **キューイング+バッチ書き込み** で解決可能です。
>
> **E2E 暗号化は『サーバーが見られない』ことを前提にメタデータ設計まで見直しました。** 既読/リアクションを平文メタとして許容するか、将来的に「既読も暗号化」へ移行するかは、プライバシーポリシーとコストのトレードオフで決めてください。
>
> まずは **『最小構成で本番投入 → 実測値でボトルネック特定 → 点対点でスケール』** のサイクルを 2 週間単位で回しましょう。設計図は生き物です。"
---
**添付資料 (別途用意推奨)**
1. `terraform/` - 全リソース IaC
2. `helm/` - k3s マニフェスト (ArgoCD ApplicationSet)
3. `docs/api-spec.yaml` - OpenAPI 3.1 (WebSocket 拡張含む)
4. `docs/threat-model.md` - STRIDE 分析
5. `runbooks/` - インシデント対応手順 (Redis フェイルオーバー、ScyllaDB ノード交換等)
以上で設計書を完了とします。ご質問・フィードバックお待ちしています。かなりしっかり出力してくれたのかなと思います。実際の処理は下記です。
同じ内容をClaude Opus 4.8にもしてみました。
Claude Opus 4.8の結果はこちら
# 結論から:この規模で本当に難しいのは「スケール」ではなく「E2Eの正しさ」と「コスト規律」
最初に規模感を握っておきます。MAU 100万は、チャットアプリとしては**中規模**です。ここを誤認して最初から Kafka + Scylla + マルチリージョンを組むと、$30k は監視費と転送費だけで溶けます。実際の難所は、生の同時接続数ではなく、(1) マルチデバイス・グループ込みの E2E を破綻なく回すこと、(2) マネージドサービスへの課金死を避けることの2点です。設計全体をこの認識で組みます。
## 1. 容量見積もり(設計の土台)
- MAU 100万 → DAU 約20万(チャットは粘着率高め、10〜20%想定)
- ピーク同時接続:DAU の 10〜15% ≒ **3万コネクション**
- メッセージ量:1日約1000万通 ≒ 平均 115 msg/s、ピーク **約1000 msg/s**
この数字が効きます。3万同時接続は Go なら1ノードで余裕、1000 msg/s は PostgreSQL でも捌けるレンジです。つまり「分散DBが必須」な水準にはまだ届いていない。ここを冷静に見るのが最大のコスト最適化になります。
## 2. アーキテクチャ全体像と選定理由
採用スタックを単一案で示します(各所で代替を1行だけ添えます)。
**リアルタイム層:Go の WebSocket ゲートウェイ(ステートフル)**
3万接続なら Go で十分すぎます。Elixir/Phoenix は魅力的ですが、その真価は同時接続が50万を超えてから。今それを選ぶのは過剰設計で、採用難易度だけ上がります。ユーザーは consistent hashing でゲートウェイに固定配置し、ノードをまたぐ配送はバックボーン経由にします。
→ *同時接続が50万超えたら Elixir 移行を検討。*
**ノード間ルーティング:NATS(自前運用)**
送信者と受信者が別ゲートウェイにいる時の配送が肝です。Redis Pub/Sub は手軽ですが全ノードへブロードキャストする構造のため早期に頭打ちになります。最初から NATS(subject ベースのルーティング)にしておくと、ここがボトルネックになりません。
**E2Eプロトコル:1:1 は Signal(X3DH + Double Ratchet)、グループは MLS(RFC 9420)**
サーバはあくまで暗号文の中継役で、平文を一切持ちません。グループに Signal の sender-key 方式ではなく MLS を選ぶのは、大人数グループの再鍵配布(メンバー増減のたびの rekey)が対数オーダーで効くためです。ここがグループスケールの分かれ目になります。サーバの役割は prekey bundle の保管・補充と、暗号文の順序保証付き配送のみ。
**メッセージストア:PostgreSQL(conversation_id でパーティション)+ Redis(オフラインキュー/presence)**
1000 msg/s なら PostgreSQL で問題ありません。暗号文は「全デバイス配送完了で削除 or 短期保持」にして肥大化を防ぎます。
→ *書き込みが10倍を超えたら Citus シャーディング、さらに先で ScyllaDB。最初から Scylla を入れない。*
**メディア:クライアント側で暗号化 → Cloudflare R2**
これがコスト設計の要です。S3 のegress($0.09/GB)はメディア配信で効いてきます。**R2 は egress 無料**なので、転送費というスケール時の地雷を最初から無効化できます。配信は Cloudflare CDN を前段に。
**Push:APNs / FCM(中身は載せない)**
サーバは平文を持てないので、通知は「新着あり」の汎用ペイロードのみ。クライアントが起きて取得・復号します。E2Eアプリの標準形で、課金もほぼゼロ。
**監視:自前 LGTM(Grafana/Loki/Tempo/Mimir)または Grafana Cloud**
Datadog はこの規模で平気で月数千ドル飛びます。予算を守る上で監視SaaSの選定は技術選定と同格に重要です。
## 3. E2E設計の肝(既読・リアクション含む)
ご指定の機能をE2E前提でどう成立させるか、ここが実装の本丸です。
**既読機能**:「メッセージXまでTの時刻に既読」という暗号化された制御メッセージを送るだけ。サーバは last-read ポインタ(メッセージID)を中継・保持できますが、これはメタデータであって内容ではない。安価です。
**リアクション**:対象メッセージIDを参照する暗号化イベントとして送信し、メッセージ単位の順序付きイベント列として保存。ここで一つ重要な設計判断があります — **真のE2Eだとサーバは絵文字の中身を読めないため「❤が5人」の集計をサーバ側でできません**。集計はクライアント側で行い、サーバは参照(どのメッセージか)だけ見える状態に留めます。サーバ集計したいなら絵文字をサーバに漏らす=E2Eを部分的に緩めることになる。私の判断は**集計はクライアント側、E2E維持**です。
**マルチデバイス**:各デバイスが固有の鍵を持つため、送信者は受信者の全デバイス宛に暗号化する(デバイス・ファンアウト)。MLS がこれをグループの一形態として扱うので統一的に処理できます。
**鍵バックアップ**:デバイス紛失=履歴復号不能、は仕様通りですがサポート負荷とUXの地雷。WhatsApp 方式の「ユーザーパスフレーズで暗号化したバックアップ」を最初から設計に入れておきます。
## 4. コスト試算(制約 $30k に対して)
| 項目 | 構成 | 月額(概算) |
|---|---|---|
| WSゲートウェイ | EC2 Go ×8(c6i.2xlarge, ASG) | $2,500 |
| API/ロジック層 | ECS Go | $2,000 |
| メッセージDB | Aurora PostgreSQL | $3,000 |
| Redis(presence/queue) | ElastiCache | $1,500 |
| ルーティング | NATS(自前 EC2) | $800 |
| メディア | Cloudflare R2 | $800 |
| CDN/エッジ | Cloudflare | $500 |
| Push | APNs/FCM | ~$0 |
| 監視 | Grafana Cloud / 自前LGTM | $1,000 |
| ネットワーク | NAT/LB/転送 | $2,000 |
| バッファ(障害・スパイク) | — | $2,000 |
| **合計** | | **約 $16,100** |
**$30k に対して約14kの余裕を意図的に残しています。** これは過剰見積もりではなく、インシデント対応・急成長・トラフィックスパイクの吸収代です。逆に言えば、規律を欠くと予算超過する典型ルートは決まっています — Datadog、AWS の data transfer、NAT Gateway の隠れ課金、過剰プロビジョニングされた Aurora、Confluent Cloud。これらを避けることが「$30k 内」の本質です。
## 5. ボトルネック
1. **ノード間ファンアウト** — 送受信者が別ゲートウェイにいる配送。NATS で先回り対策済み。
2. **グループ配送のN倍問題** — 1000人グループへの1通=1000配送。暗号化は1回でも配送はN回。大規模グループが真の痛点。
3. **presence / 既読のファンアウト** — コンタクトの多いユーザーで N² 化する。
4. **再接続のサンダリングハード** — デプロイや回線断で3万クライアントが一斉再接続。
5. **Signal の prekey 枯渇** — 一時prekeyの補充をサーバが管理する必要。
6. **ホットパーティション** — バズった会話/グループが特定シャードを焼く。
## 6. スケール時のリスクと対策
**10倍成長(MAU 1000万)**
- 接続層:ゲートウェイ水平増設は容易だが、NATS のルーティングが先に詰まる → subject のシャーディング、必要なら Elixir 移行。
- DB:PostgreSQL → Citus シャーディング → ScyllaDB の順で段階移行。conversation_id でのパーティション設計を**今のうちに**入れておくことが移行コストを決める。
**メディア転送費の爆発**
R2 + CDN を初日から採用していることが対策そのもの。S3 だったらここで予算が破綻する。
**大規模グループ**
MLS による対数オーダーの再鍵配布、グループ人数の上限設定、バックプレッシャー付きのファンアウトワーカー。
**ステートフルゲートウェイのデプロイ地雷**
接続を持ったままのデプロイは接続断を生む → graceful drain と、再接続時の **jittered backoff**(サンダリングハード回避)。完全な接続マイグレーションは複雑なので、まずは「短時間の再接続を許容しつつ一斉再接続を散らす」で十分。
**メタデータ漏洩(E2Eの盲点)**
内容は守れても「誰がいつ誰と」はサーバに見える。Signal の sealed sender で送信者メタデータを隠す。コンプライアンス上、E2Eでは**サーバ側コンテンツモデレーションが不可能**な点も経営判断として明示が必要(通報・レート制限・メタデータ分析に頼る)。
**単一リージョンのレイテンシ**
グローバル展開時、E2Eと順序保証を保ったままのマルチリージョンは難易度が高い。**接続終端だけエッジに出し、コアは単一リージョン**から始めるのが現実解。フルマルチリージョンは課題が顕在化してから。
---
総括すると、この要件で技術的に賭けるべき投資は「raw scale 対応」ではなく、**MLS によるグループ暗号設計**と**R2/自前監視によるコスト規律**の2点です。3万同時接続を Go で淡々と捌きつつ、難所をE2Eの正しさに集中投下する。これが $30k を守りながら破綻しない構成だと判断します。
実装に入るなら、最初に固めるべきは「マルチデバイスの鍵配布とデバイスファンアウト」です。ここの設計ミスは後から直すのが最も高くつくので、PoC の一発目をここに当てることを勧めます。構成もしっかり考えてくれていますが、NVIDIA Nemotron 3 Ultra 550Bが出してくれたコストの方が安かったですね。
またアーキテクチャ全体図やデータモデルも出してくれているので、何かサービスを作りたいと思っている方は壁打ちするのはNVIDIA Nemotron 3 Ultra 550Bの方がいいかもしれません。
【業界別】NVIDIA Nemotron 3 Ultra 550Bの活用シーン
Nemotron 3 Ultraは、フロンティア推論・長文脈処理・ツール連携を必要とする多様な業界で活用が期待できます。
ソフトウェア開発・エンジニアリング
SWE-Bench Verifiedで71.9点を記録しており、実際のGitHubイシュー解決で高い性能を発揮します。巨大なコードベースの一括解析や、マルチステップのデバッグ・テスト生成などのエージェントタスクで強みを発揮。
競技プログラミングを想定したIOI 2025ベンチマークでは570.0点を記録しており、複雑なアルゴリズム問題への対応力も期待できます。
科学研究・データ解析
GPQA(博士レベルの科学的推論)で87.0点という高スコアを出しており、生命科学・化学・物理などの研究に活用ができそうです
100万トークンのコンテキストを活用すれば、膨大な参考文献を一度に処理するハイステークスRAGシステムの構築にも最適。複数文書にわたる情報抽出・要約・比較といった高度な長文脈処理が可能です。
カスタマーサポート・エンタープライズエージェント
TauBench V3のTelecomカテゴリでは92.9点を記録しており、通信・航空・小売などのカスタマーサービス領域での自律エージェント展開に対応できます。
複雑な問い合わせ対応や、複数システムへのツール呼び出しを組み合わせたマルチステップエージェントとして活用することで、オペレーターの業務効率化が期待できます。
多言語コンテンツ・グローバルサービス
SWE-Bench Multilingualで67.7点を記録しており、非英語圏向けの技術支援や多言語ドキュメント生成への応用が広がります。
日本語・中国語・ドイツ語・フランス語など複数言語に対応しているため、グローバル展開するサービスの多言語AIエージェント基盤として活用可能です。
【課題別】NVIDIA Nemotron 3 Ultra 550Bが解決できること
NVIDIA Nemotron 3 Ultra 550Bが解決できる代表的な課題を紹介します。
巨大ドキュメントを一括で解析できる
これまでのLLMでは、数十万〜数百万トークン規模の文書群を一度に処理することが技術的に困難でした。Nemotron 3 Ultraの100万トークンコンテキストにより、法律文書・財務報告書・巨大コードベース全体を1回のリクエストで処理できます。
複雑なマルチステップエージェントを自律実行できる
単純な質問応答ではなく、複数のツールを組み合わせて段階的にタスクを解決するエージェントワークフローを高い精度で自律的に実行できます。PinchBench(ツール使用)での90点というスコアがその能力を裏付けています。
ECサイトの在庫確認・注文処理・返金対応を連続して行うカスタマーサービスエージェントやコードのビルド→テスト→デバッグを繰り返す開発エージェントなど、高ステークスな自律処理に対応可能です。
推論コストを柔軟にコントロールできる
推論モードのON/OFFとreasoning_budgetによる上限設定により、タスクの複雑さに応じて推論コストを動的に調整できます。
高精度が必要な数学・科学推論では推論ONで深く考え、スループットを優先するチャット応答では推論OFFに切り替えるという使い分けが単一モデルで実現できます。複数モデルを用途別に運用するより管理コストが低く、一元管理というメリットも生まれます。
Opus 4.7に匹敵するコーディング性能を10分の1のコストで実現したComposer 2.5について、詳しく知りたい方は以下の記事をご覧ください。

NVIDIA Nemotron 3 Ultra 550Bのよくある質問
ここではNVIDIA Nemotron 3 Ultra 550Bのよくある質問について回答していきます。NVIDIA Nemotron 3 Ultra 550Bの使用を検討している場合には、ぜひ参考にしてみてください。
NVIDIA Nemotron 3 Ultra 550BでオープンAIエージェント開発を加速しよう
NVIDIA Nemotron 3 Ultra 550Bは、オープンウェイトでフロンティアレベルの推論能力を提供するNVIDIAの最上位LLMです。
LatentMoEアーキテクチャとMTPによる効率的な設計、100万トークンのコンテキスト長、推論モードのON/OFF切り替えという三つの特性が組み合わさり、AIエージェント開発の新たな選択肢を切り開いています。
単なる高性能モデルにとどまらず、オープンウェイト・オープン学習・商用ライセンスという特徴も兼ね備えており、クローズドAPIへの依存から脱却したい企業にとって有力な基盤といえるでしょう。
今後はNVIDIAの最新ハードウェアとの最適化がさらに進み、より少ないGPUリソースで同等の性能を引き出せる推論最適化手法も登場してくると考えられます。
ぜひ皆さんも本記事を参考にNVIDIA Nemotron 3 Ultra 550Bを使ってみてください!

最後に
いかがだったでしょうか?
NVIDIA Nemotron 3 Ultra 550Bを活用することで、AIエージェントをオープンウェイトで構築する道が大きく開かれます。一方で、最低4×B200という高いハードウェア要件は設計次第でコストが大きく変わるため、クラウド推論プロバイダーの活用も重要な選択肢として検討することをおすすめします。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

