

- MAI-Thinking-1はMicrosoftがゼロから開発した35B active / 1T totalのMoE推論モデルで、第三者モデルからの蒸留を一切使わずに学習
- AIME 2025で97.0%、SWE-Bench Proで52.8%を達成し、Claude Sonnet 4.6に匹敵する汎用性を持つ
- STEM・エージェント・安全性の3つのRLクライムを経て単一モデルに統合するユニークな学習プロセスが特徴
2026年、Microsoft AIチームから新しい大規模推論モデルが発表されました。
今回登場した「MAI-Thinking-1」は、単なる性能向上にとどまらず、「ヒルクライミングマシン」と呼ぶ独自の開発フレームワークから生まれた最初のモデルです。第三者モデルからの蒸留を一切行わず、ゼロからトレーニングされています。
Seven new models launching at Build: let’s go!
— Microsoft AI (@MicrosoftAI) June 2, 2026
Reasoning. Code. Image. Transcribe. Voice.
Built from scratch on a clean data lineage, designed for efficiency, working seamlessly as a family of models
Thread#MSBuild pic.twitter.com/g3WQIcIQ24
これまでの大規模言語モデル開発では、「他社モデルからの蒸留に依存した能力継承」「ベンチマーク汚染によるリスク」「推論とエージェント性能の両立の難しさ」といった課題がありました。
一方でMAI-Thinking-1は、STEM推論・エージェントコーディング・安全性の3分野でそれぞれ専門モデルを訓練し、それらを1つのモデルに統合するアプローチを採用しています。256Kトークンのコンテキスト長を持ちながら、数学・科学・コーディングの幅広い領域で高いスコアを達成。
しかし、新しい推論モデルが発表されるたびに、「既存の推論モデルと何が違うのか」「実際にどんな業務で使えるのか」「安全性はどのくらい信頼できるのか」といった疑問を抱く方も多いのではないでしょうか。
そこで本記事では、MAI-Thinking-1の概要や仕組み、特徴を整理しながら、具体的なベンチマーク結果や活用シーンについて詳しく解説します。
最後までお読みいただくことで、MAI-Thinking-1がどのような思想で設計され、どのような場面で力を発揮するのかが理解できるはずです。
\生成AIを活用して業務プロセスを自動化/
MAI-Thinking-1とは
MAI-Thinking-1は、Microsoft AI(MAI)チームが2026年6月に発表した大規模推論モデルです。

35B(350億)のアクティブパラメーターと合計1T(1兆)のパラメーターを持つMixture-of-Experts(MoE)アーキテクチャを採用。推論時には512のエキスパートのうち上位8つのみが活性化されるため、巨大なモデル規模でありながら効率的な計算が可能です。
最大の特徴は、第三者モデルからの蒸留を一切行わずにゼロから学習している点。Microsoftが「ヒルクライミングマシン」と呼ぶ独自の開発フレームワークのもと、データパイプライン・学習インフラ・強化学習環境・評価を一体化し、継続的に性能を改善できる仕組みを構築しています。
STEM推論・競技プログラミング・ソフトウェアエンジニアリング・一般的な知識・安全性まで、幅広いドメインをカバー。


MAI-Thinking-1の仕組み
MAI-Thinking-1の開発プロセスは大きく「事前学習(Pre-training)」「中間学習(Mid-training)」「強化学習クライム(RL Climb)」の3フェーズで構成されています。
事前学習フェーズ:MAI-Base-1の構築
ベースモデルとなるMAI-Base-1は、約8000基のNVIDIA GB200 GPUを搭載したAzureクラスター上で学習されました。学習トークン数は30兆(30T)トークンに及び、Webデータ・公開GitHubコード・書籍・学術論文・ニュース・多言語テキストなど多岐にわたるソースを使用。
注目すべきは、AIが生成した合成データを意図的に排除している点です。人間が生成したデータのみを使用することで、モデルの操縦性と頑健性を確保しています。
学習後、コンテキスト長を64Kから最終的に256Kトークンまで段階的に拡張する中間学習フェーズを経て、RLクライムの起点となる基盤モデルが完成します。
強化学習クライム:3つの専門モデルを並行訓練
RLフェーズでは、3つのドメイン特化型の専門モデルを並行して訓練。それぞれ異なる問題セットと報酬設計のもとで実施されます。
| 項目 | 内容 |
|---|---|
| STEMクライム | 数学・物理・化学・競技プログラミングなど、単一ターンの問題解決能力を強化。500万件以上のSTEM問題からなるSTEM Mixデータセットを活用 |
| エージェントクライム | 実際のコードリポジトリ上での多ステップ作業・ツール呼び出し・ソフトウェアエンジニアリングタスクに特化。実際のGitHub PRを起点に構築した26万超のSWE環境を使用 |
| ヘルプフルネス&セーフティクライム | 人間の好みに沿った回答スタイル・安全性・指示遵守・誠実性を最適化。報酬モデル・AIジャッジ・検証可能な報酬を組み合わせた複合評価 |
各専門モデルはGRPOと自己蒸留を組み合わせた手法で数千ステップにわたって継続的に訓練されます。ゼロから推論能力を獲得するため、学習安定性の確保がとりわけ重要な課題です。
統合フェーズ:3つの専門モデルを1つに収束
3つの専門モデルをSFT(教師あり微調整)で1つの「統合モデル」に蒸留し、最後に軽量なRLクライムを実施してMAI-Thinking-1が完成します。
統合時のデータ比率はSTEMとコーディングがサンプル重みで56%と大半を占めます。単なるモデルマージではなく、各専門モデルのトレースを厳選してSFTすることで知識転移の精度を高め、推論能力を損なわずに安全性・スタイルを後付けで組み込む設計です。
3つの技術でローカルAIをアプリに統合するMicrosoft Foundry on Windowsについて、詳しくは知りたい方は以下の記事をご覧ください。

MAI-Thinking-1の特徴
MAI-Thinking-1には、他のモデルとは異なるいくつかの特徴があります。ここではMAI-Thinking-1の特徴について解説していきます。
STEM・コーディングベンチマーク性能
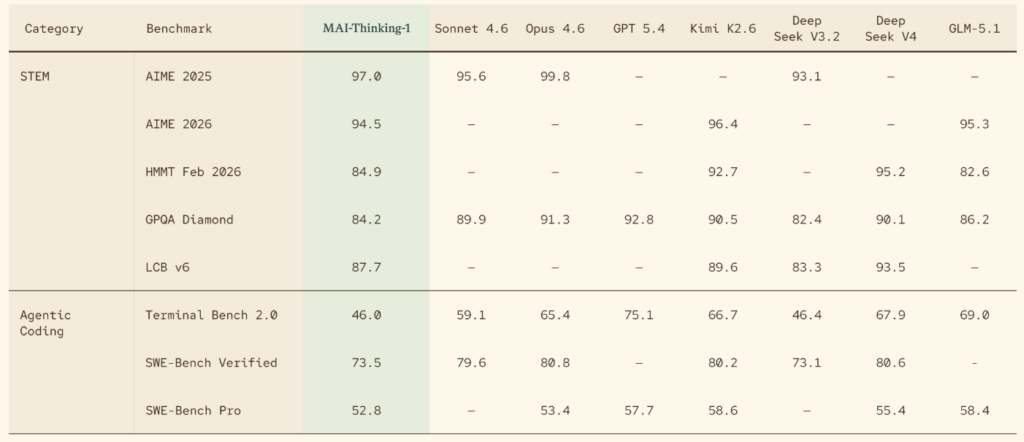
MAI-Thinking-1は数学・科学・競技コーディングを中心に、高い性能を発揮しています。
| ベンチマーク | MAI-Thinking-1 | Sonnet 4.6 | Opus 4.6 | DeepSeek V3.2 |
|---|---|---|---|---|
| AIME 2025(数学) | 97.0% | 95.6% | 99.8% | 93.1% |
| AIME 2026(数学) | 94.5% | — | — | — |
| HMMT Feb 2026(数学) | 84.9% | — | — | — |
| LCB v6(競技コーディング) | 87.7% | — | — | 83.3% |
| SWE-Bench Verified | 73.5% | 79.6% | 80.8% | 73.1% |
| SWE-Bench Pro | 52.8% | — | 53.4% | — |
| Terminal-Bench 2.0 | 46.0 | 59.1 | 65.4 | 46.4 |
| GPQA Diamond(科学) | 84.2% | 89.9% | 91.3% | 82.4% |
AIME 2025では97.0%を達成し、Claude Sonnet 4.6(95.6%)を上回るスコア。SWE-Bench Proでは、Opus 4.6(53.4%)とほぼ同等の52.8%を記録しています。
蒸留なし・ゼロから学習する設計思想
MAI-Thinking-1の開発で最も重視されたのが「能力は継承ではなく学習されるべき」という点です。
蒸留によって他社モデルの能力を模倣することは学習コストを下げる手段として広まっています。
しかし蒸留モデルは長期的な操縦性と頑健性に欠けるとMicrosoftは指摘。継続的な性能改善(ヒルクライミング)を安定して進めるためには、ゼロから能力を獲得することが不可欠だと判断しています。
スパースMoEアーキテクチャによる効率的な推論
MAI-Thinking-1の基盤モデルMAI-Base-1は、512のエキスパートのうち8つのみを各トークンで活性化する高スパースMoEを採用しています。全パラメーターは1兆に達しますが、推論時に動くのは35Bのみ。
アテンション層には5:1のLocal/Globalアテンション比を採用し、計算コストを抑えながら長文脈の理解力を維持します。FP8量化やAttention層のゼロ初期化による学習安定化など、細部の工夫も随所に見られます。
人間評価でSonnet 4.6を上回る簡潔さとスタイル
ベンチマーク以外に、Surge AIの評価者1,276タスクによる人間評価でも実力が確認されています。
Sonnet 4.6との比較では、「簡潔さ・関連性」「スタイルと文調」で優位にあることが判明。「指示遵守」「事実正確性」「完全性」については概ね同等です。MAI-Thinking-1がSonnet 4.6に勝ったのは49%、引き分けが6%、負けが45%という結果。
今回同時リリースされた他のMAIモデル
Microsoftは今回のリリースでMAI-Thinking-1を含む合計7つのMAIモデルを発表しました。テクニカルレポートで公開されている主要モデルを以下に整理します。
| モデル名 | 役割・特徴 |
|---|---|
| MAI-Code-1-Flash | 軽量なエージェント型コーディングモデル。GitHub CopilotやVS Code向け |
| MAI-Image-2.5 | テキストから画像生成・画像編集に対応する画像モデル |
| MAI-Image-2.5 Flash | MAI-Image-2.5の高速・低コスト版 |
| MAI-Voice-2 | 自然な音声生成モデル。15言語に対応 |
今回の7モデルリリースには、これらの研究・開発段階のモデルに加え、Microsoft CopilotやAzureサービスと統合されるバリアントも含まれると考えられます。


MAI-Thinking-1の安全性・制約
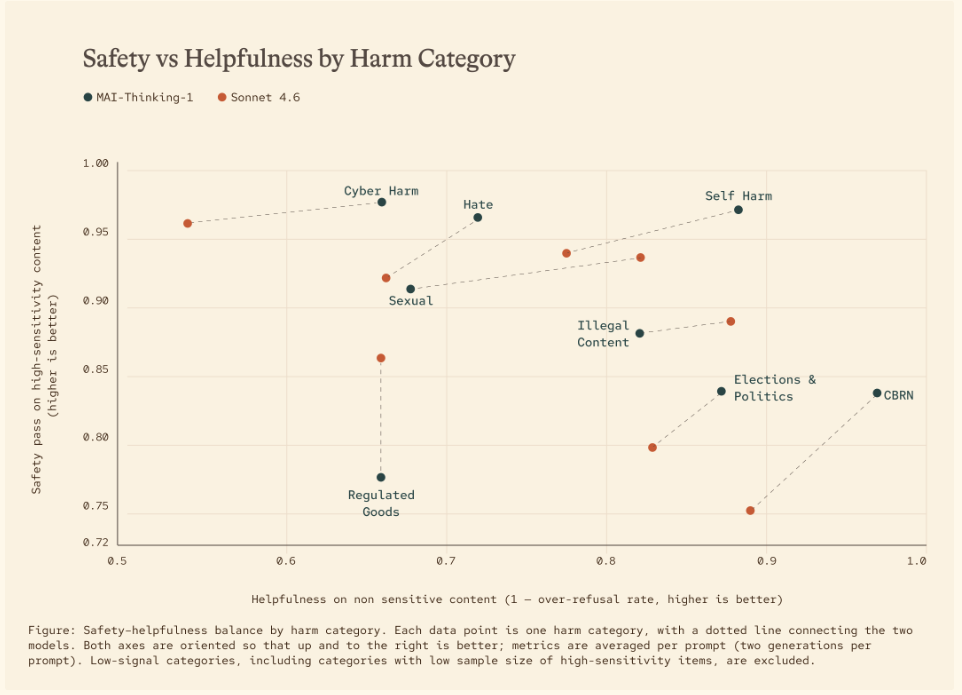
MAI-Thinking-1では、安全性を「有害なリクエストを拒否する能力」と「正当なリクエストに応答する能力」のバランスとして定義しています。この2軸を同時に最適化することを目指した点が、安全性設計の中心です。
内部レッドチーミング
MAI-Thinking-1の開発期間中、安全性研究者と外部アノテーターによる25のポリシーカテゴリーをカバーする2,170以上のゴールベースシナリオでレッドチーミングを実施。
主要なジェイルブレイク攻撃への耐性を3カテゴリーで評価した結果は以下のとおりです。攻撃成功率(ASR)が低いほど安全性が高いことを示します。
| 攻撃カテゴリー | MAI-Thinking-1(ASR) | GPT-5.4 | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|---|---|
| Foundational(単純変換) | 4.4% | 7.0% | 3.0% | 5.7% |
| Compositional(複合変換) | 17.6% | 13.9% | 17.4% | 15.0% |
| Adaptive(適応型・マルチターン) | 26.8% | 32.3% | 25.1% | 26.4% |
MAI-Thinking-1の攻撃成功率はSonnet 4.6やOpus 4.6と同等水準にあり、Foundational攻撃への耐性では4.4%という低い攻撃成功率を達成しています。
独立レッドチーミング
社内評価に加え、Microsoft AI Red Team(AIRT)と第三者ベンダーによる独立したレッドチーミングも実施されました。
TAP攻撃への脆弱性が特定されたケースでは、ジェイルブレイク成功率が22%低下するまで対策データを追加。ヘイト・フェアネスで約43%、子どもの安全問題で約30%の攻撃成功率削減が確認されています。
現時点での制約と注意点
安全性評価はほぼ英語環境で実施されており、低リソース言語(ヨルバ語・テルグ語・アムハラ語・ビルマ語・クメール語・マレー語など)での多言語耐性は継続的な投資課題として明記されています。
また、マルチモーダル入力やアウトオブスコープなエージェントシナリオについては、今回の評価範囲に含まれていません。
1時間の音声を一括文字起こしできるVibeVoice-ASRについて、詳しくは知りたい方は以下の記事をご覧ください。
MAI-Thinking-1の料金
MAI-Thinking-1の料金体系に関する詳細は公開されていません。
Microsoft CopilotやAzure AI Foundryなどのサービスを通じた提供が検討されており、エンタープライズ向けの料金体系や従量課金モデルについては今後の公式発表を待つ形となります。
MAI-Thinking-1のライセンス
MAI-Thinking-1のライセンス情報は確認できませんでした。商用利用・配布・改変などを検討する場合は、事前にMicrosoftへの確認が必要です。
学習データについて、テクニカルレポートには「企業秘密・プライバシー上の理由でデータプロバイダーの全リストは開示しない」と明記されており、オープンソース公開のスケジュールについても現時点で公式な情報はありません。
GPT-5.5超えのオープンウェイトモデルであるMiniMax M3について、詳しくは知りたい方は以下の記事をご覧ください。

MAI-Thinking-1の使い方
MAI-Thinking-1は、Microsoft FoundryもしくはMAI Playgroundを通じた提供が見込まれています。ここでは考えられるMAI-Thinking-1の使い方について簡単に触れます。
なお、MAI Playgroundでの提供はまだ始まっていません。
Microsoft Foundryでの利用
Microsoft Azureにアクセスし、Microsoftアカウントでサインインします。
利用可能なモデルのリストからMAI-Thinking-1を選択しますが、本記事執筆時点ではまだ利用可能にはなっていませんでした。
利用可能になったら、数学の問題・コーディング課題・科学的分析など、推論能力を要するタスクを入力して結果を確認します。256Kトークンのコンテキスト長を活かした長文分析も可能でしょう。
価格据え置きで正直さと判断力が大幅強化されたClaude Opus 4.8について、詳しく知りたい方は下記の記事も併せてご覧ください。

【業界別】MAI-Thinking-1の活用シーン
MAI-Thinking-1の高度な推論能力とエージェント機能は、さまざまな業界における複雑な課題解決への活用が期待されます。
研究・学術機関
数学オリンピックレベルの問題や大学院レベルのSTEM問題への対応が可能です。研究者が手動で解くには時間のかかる計算・証明のドラフト作成を大幅に効率化できると考えられます。
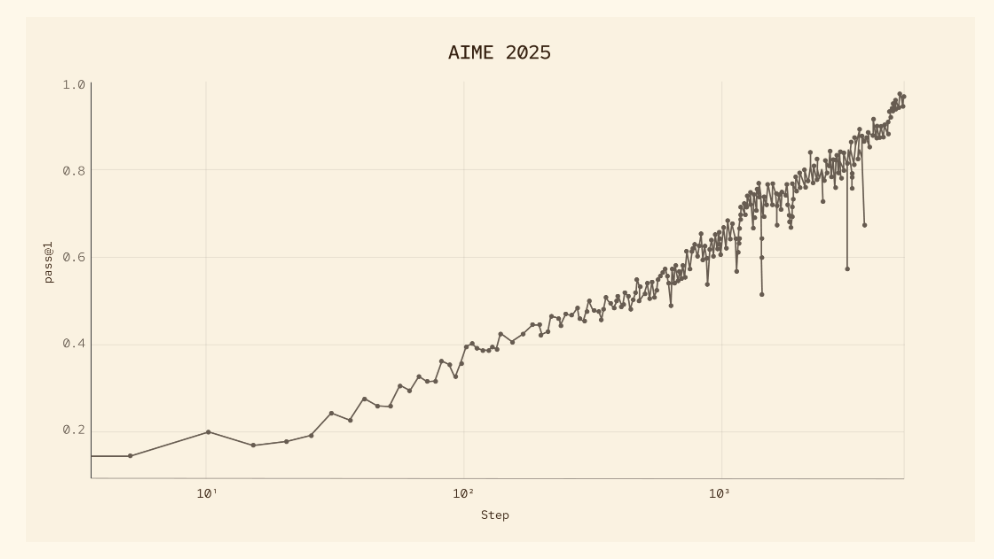
競技プログラミングでの高スコアも示すとおり、アルゴリズム設計や計算量分析においても高い精度が期待できるでしょう。
ソフトウェア開発
SWE-bench Verified(73.5%)やSWE-Bench Pro(52.8%)のスコアが示すとおり、実際のGitHubリポジトリのIssueを読み取り、コードを修正するエージェント型コーディングに強みを持ちます。
サンドボックス実行環境と組み合わせることで、コードのデバッグ・リファクタリング・テストケース生成などの自動化が現実的な選択肢になりつつあります。
金融・コンサルティング
256Kトークンという大規模なコンテキスト長により、財務報告書・法律文書・調達仕様書など、長大なドキュメントを一括でインプットした分析が可能。
長文脈理解ベンチマーク(GraphWalks ≦128k: 90点)での高スコアが、複雑な文書処理タスクへの適性を裏付けています。
生成AIで銀行・金融業界のDX化について詳しく知りたい方は下記の記事をご覧ください。

エンタープライズ向けツール呼び出し
ツール呼び出しベンチマークが示すとおり、在庫管理・スケジューリングプラットフォーム・レポート作成・カスタマーサポートなどのエンタープライズ向けシナリオでのAPIやMCP(Model Context Protocol)連携においても活用が期待できます。
50種類以上のツールを含む複雑な環境でのタスク実行も対象として学習されており、実際の業務システムとの連携において幅広い用途に対応できると考えられます。
【課題別】MAI-Thinking-1が解決できること
ここではMAI-Thinking-1が解決できる代表的な課題を紹介します。これからMAI-Thinking-1を使おうと考えている方はぜひ参考にしてください。
高度な数学・科学的推論をAIに委任できる
これまで専門家のみが扱えたAIME・競技数学レベルの問題を97%の精度で解答。研究者や学生が行き詰まった問題のブレイクスルーに活用できる可能性があります。
500万件以上のSTEM問題からなるトレーニングデータとSymPy等の形式的検証ツールを使った報酬設計により、数学的に正確な回答生成が期待できます。
コードリポジトリのIssueを自律的に解決できる
実際のGitHubのPRやIssueを学習環境として使用した強化学習により、単純なコード補完にとどまらず、「問題の読み取り→調査→修正→テスト」という一連のエンジニアリングサイクルをエージェントとして実行できます。
SWE-bench Verifiedのスコアは、既存リポジトリへの変更が実際に機能するかを検証したものであり、実用水準の自律的なソフトウェア修正が可能といえるでしょう。
安全性を保ちながら高い有用性を両立できる
従来の推論モデルは安全性強化のために応答率が低下するケースが多くありました。
MAI-Thinking-1は安全性ゲーテッドアグリゲーターを採用しており、「安全でないレスポンスは最低報酬、有用性の高いレスポンスほど高報酬」という設計で両立を実現。
35時間の自律タスク実行を実現したAlibabaのQwen3.7-Maxについて、詳しくは知りたい方は以下の記事をご覧ください。

MAI-Thinking-1のよくある質問
ここではMAI-Thinking-1のよくある質問について回答していきます。MAI-Thinking-1の使用を検討している場合には、ぜひ参考にしてみてください。
MAI-Thinking-1が拓く推論AIの新時代
MAI-Thinking-1は、「ヒルクライミングマシン」という独自の開発思想に基づき、蒸留に依存せずゼロから能力を獲得した35B active / 1T total MoEの推論モデルです。
STEM・競技コーディング・エージェントコーディング・安全性という複数の専門領域を独立したRLクライムで個別に強化してから統合するアーキテクチャは、これまでの推論モデル開発の常識を一歩前に進めるものといえるでしょう。
単なる性能向上の手段にとどまらず、「シンプルさは持続可能」「科学的厳密さが近道を避ける」という考えが貫かれている点も注目です。同規模の他モデルと比較してより少ない計算コストで高い結果を出す効率性は、今後のエンタープライズ展開における大きな強みになると考えられます。
今後はマルチモーダル対応・より大規模なスケール・精緻化した能力への拡張が予定されており、Microsoftの「ヒルクライミングマシン」が継続的に性能を積み上げていくことが期待されます。
利用可能になったらぜひ皆さんも使ってみてください!

最後に
いかがだったでしょうか?
MAI-Thinking-1を活用することで、数学・科学的推論・自律的なコーディングといった高度なタスクをAIに委任できる可能性が広がります。一方で、料金・ライセンス・一般公開のタイミングは設計次第で効果が大きく変わるため、最新の公式情報を追い続けることも重要な選択肢です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

