

- テキスト・音声・画像・動画に対応し、リアルタイムで自然音声を出力可能
- 119言語のテキスト、19言語の音声入力、10言語の音声出力をサポート
- 教育・翻訳・動画解析など幅広いユースケースで活用できる次世代モデル
2025年9月、アリババから新たなオムニモーダルLLMがリリース!
今回リリースされた「Qwen3-Omni」は音声・画像・動画に対応しており、入力だけでなく自然な音声をリアルタイムに出力できます!
— Qwen (@Alibaba_Qwen) September 22, 2025
Introducing Qwen3-Omni — the first natively end-to-end omni-modal AI unifying text, image, audio & video in one model — no modality trade-offs!
SOTA on 22/36 audio & AV benchmarks
119L text / 19L speech in / 10L speech out
211ms latency |
30-min audio… pic.twitter.com/qGn34N7Xvd
本記事では、Qwen3-Omniの概要から性能、使い方を解説していきます。最後までお読みいただければ、Qwen3-Omniの理解が深まります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Qwen3-Omniの概要
Qwen3-OmniはAlibaba Cloudが開発したエンドツーエンド型のオムニモーダルモデル。
テキスト・音声・画像・動画を入力として処理できるだけでなく、レスポンスをテキストと自然音声の両方で即時に返すことが可能となっています。
| 特徴 | 詳細 |
|---|---|
| マルチモーダル性能 | 22の音声・映像ベンチマークでSOTAを達成。ASR・音声理解・ボイスチャット性能でGemini 2.5 Proに匹敵。 |
| 多言語対応 | テキスト119言語、音声入力19言語、音声出力10言語。日本語・韓国語・英語・中国語・スペイン語・アラビア語など幅広く対応。 |
| アーキテクチャ | Mixture-of-Experts採用の「Thinker–Talker」設計。推論と音声生成を分離し、低レイテンシかつ高精度な応答を実現。 |
| リアルタイム性 | 低遅延ストリーミングと自然なターンテイキングに対応。対話やマルチメディア解析をスムーズに実行。 |
上記はQwen3-Omniの特徴一覧表です。対応言語は幅広くなっています。
Qwen3-Omni-Flashとは?
Qwen3-Omni-Flashは、Qwen3-Omniファミリーにおける商用版のオムニモーダルLLM。
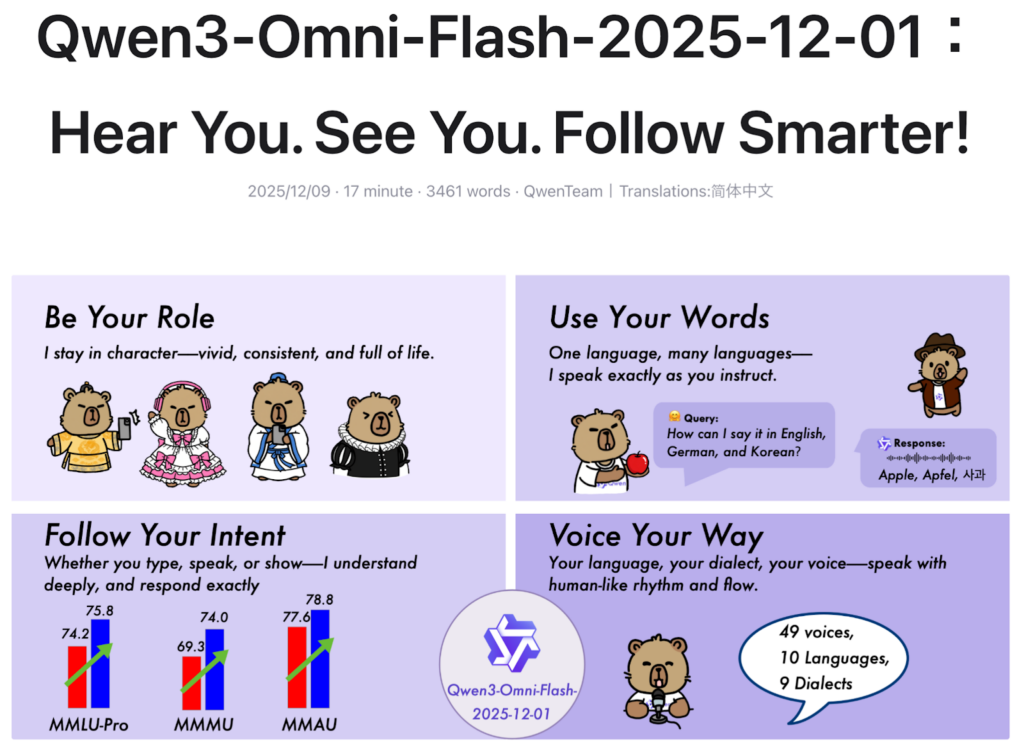
リアルタイム音声・映像対話に最適化されており、テキスト・画像・音声・動画の入力を処理し、テキストと自然音声の両方をストリーミング形式でリアルタイムに出力可能です。
現在は複数のバージョンが展開されており、主なものは以下の通り。
| モデル名 | 説明 |
|---|---|
| qwen3-omni-flash | 安定版として提供される最新モデル(現在はqwen3-omni-flash-2025-09-15と同等) |
| qwen3-omni-flash-2025-09-15 | 2025年9月15日リリースのスナップショット版。思考モードと非思考モードの両方をサポート。 |
| qwen3-omni-flash-2025-12-01 | 2025年12月の大幅アップデート版。音声・映像対話の体験が劇的に向上し、システムプロンプトによる細かな挙動制御が可能。 |
各バージョンは、思考モードと非思考モードを切り替えられ、用途に応じた最適なパフォーマンスを引き出せる設計です。Alibaba Cloudでは無料クォータ(100万トークン×モダリティ数、90日間有効)も提供されており、開発者が気軽に試せる環境が整っています。
Qwen3-Omniの性能
Qwen3-Omniは単なるマルチモーダル対応にとどまらず、複数のベンチマークで既存モデルを凌駕する性能を示しています。
特に音声・映像領域では従来モデルに比べて高い精度と低いレイテンシを実現し、テキストや画像においても最新の大規模LLMと肩を並べる水準に到達しています。
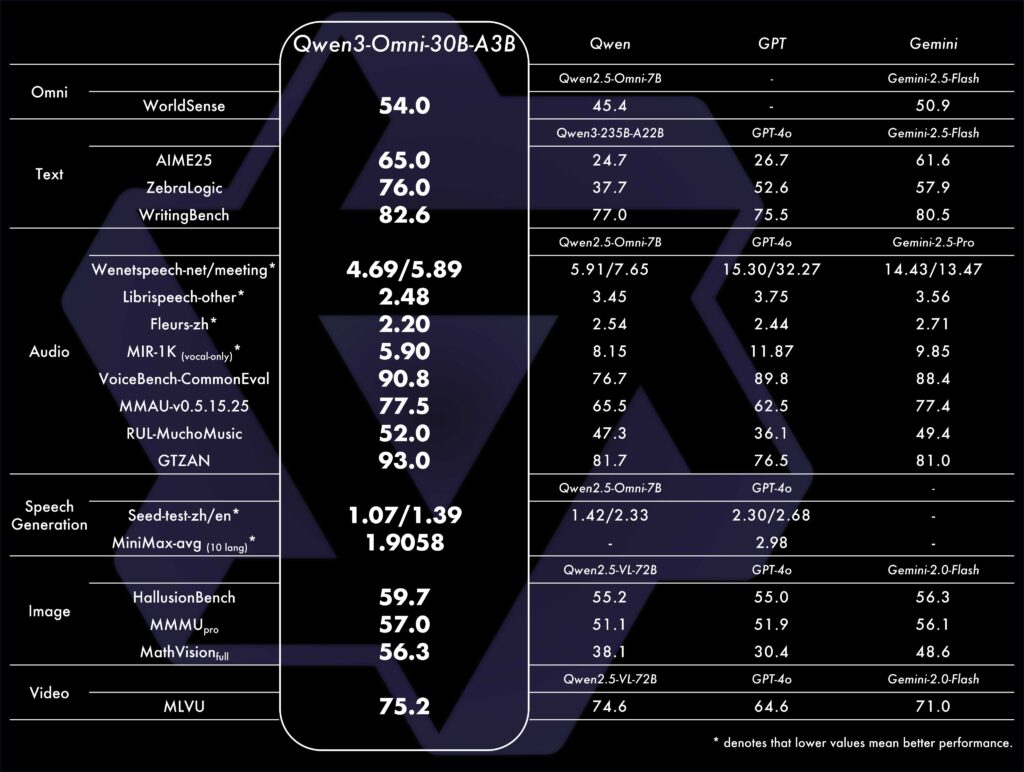
| ベンチマーク | 詳細 |
|---|---|
| テキスト性能 | AIME25、ZebraLogic、WritingBenchなどでGPT-4oやGeminiを上回るスコアを記録。 |
| 音声認識 | LibriSpeech、Fleurs-zhなど複数のベンチマークで低WERを達成。Gemini 2.5 ProやGPT-4oに匹敵、もしくは上回る精度。 |
| 音声生成 | Seed-test、MiniMaxベンチで低いエラー値を示し、自然で正確な音声出力が可能。 |
| 画像理解 | HallusionBench、MMMUで高いスコアを達成。画像推論や数理タスクにおいても安定した性能を発揮。 |
| 動画理解 | MLVUベンチで75.2を記録し、Gemini 2.0 FlashやGPT-4oを超える結果。 |
上記はQwen3-Omniのベンチマークについての一覧表です。
いずれのベンチマークでもQwen3-Omniは優れた性能を発揮しており、テキストや画像理解においてもトップクラスの精度を示しています。
対応モダリティとサポート言語一覧
Qwen3-Omni-Flashは、テキスト・画像・音声・動画を横断的に処理できるマルチモーダルAIモデルです。119言語のテキスト対応に加え、19言語の音声入力と10言語の音声出力をサポートし、グローバルなコミュニケーションニーズに応えます。
| モダリティ | 内容 |
|---|---|
| 入力:テキスト | 119言語対応(英語、中国語、日本語、韓国語、スペイン語、アラビア語など) |
| 入力:画像+テキスト | 画像URL形式またはBase64形式で入力可能 |
| 入力:音声+テキスト | 19言語対応(英語、中国語、韓国語、日本語、ドイツ語、ロシア語、イタリア語、フランス語、スペイン語、ポルトガル語、マレー語、オランダ語、インドネシア語、トルコ語、ベトナム語、広東語、アラビア語、ウルドゥー語など) |
| 入力:動画+テキスト | 動画URL形式またはBase64形式で入力可能(映像と音声を同時に処理) |
| 出力:テキスト | 119言語対応 |
| 出力:音声 | 10言語対応(英語、中国語、日本語、韓国語など主要言語) |
上記表は、各モダリティの対応状況とサポート言語の一覧表です。


Qwen3-OmniとQwen3-Omni-Flashの違い
Qwen3-Omniには、オープンウェイト版とクラウド提供版という2つの異なる提供形態があり、それぞれ異なるユースケースとメリットを持っています。ここでは、両者の構造と違いを整理します。
| 項目 | Qwen3-Omni-30B-A3B系(オープンウェイト版) | Qwen3-Omni-Flash系(クラウド提供版) |
|---|---|---|
| 提供形態 | オープンソース(Apache 2.0ライセンス)Hugging Face / ModelScopeでウェイトを公開 | Alibaba Cloud Model Studio経由のAPI提供クローズドソース |
| 実行環境 | ローカル実行可能(GPU必須)Transformers / vLLM / Dockerで動作 | クラウドAPIのみインフラ不要で即座に利用可能 |
| 主なモデル | Qwen3-Omni-30B-A3B-Instruct Qwen3-Omni-30B-A3B-Thinking Qwen3-Omni-30B-A3B-Captioner | qwen3-omni-flash(安定版) qwen3-omni-flash-2025-09-15 qwen3-omni-flash-2025-12-01 |
| パラメータ構成 | 総パラメータ数30.5Bアクティブパラメータ3.3B(MoE) | 詳細非公開 |
| 更新頻度 | リリース時点で固定 | 継続的なアップデート最新機能が随時反映される |
| コスト | 初期投資が必要実行コストは自己負担 | 従量課金制無料クォータあり(100万トークン×90日間) |
| カスタマイズ性 | 完全にカスタマイズ可能モデルの改変・ファインチューニングが自由 | システムプロンプトによる挙動制御のみモデル本体の改変は不可 |
| 最適な用途 | • 研究開発・実験• プライバシー重視の用途• 大量推論でコスト最適化したい場合 | • 迅速なプロトタイピング •インフラ構築が不要な本番運用 •最新機能を常に利用したい場合 |
上記はオープンウェイト版とクラウド提供版の一覧表ですが、自身の利用用途や実行環境に応じて柔軟に利用形態を変更することができます。
Qwen3-Omni-30B-A3B系モデルの種類
オープンウェイト版には、用途に応じた3つのバリエーションが公開されています。
| モデル名 | 構成 | 機能 | 用途 |
|---|---|---|---|
| Qwen3-Omni-30B-A3B-Instruct | ThinkerとTalkerの両方を含む完全版 | テキスト・音声・画像・動画の入力を処理し、テキストと音声の両方を出力 | 汎用的なマルチモーダル対話タスク全般 |
| Qwen3-Omni-30B-A3B-Thinking | Thinker部分のみ(Talkerを含まない) | Chain-of-Thought推論を備え、複雑な推論タスクに特化。テキスト出力のみ | 数学・STEM・論理的推論が必要な高度なタスク |
| Qwen3-Omni-30B-A3B-Captioner | Instructモデルから音声キャプション用にファインチューニング | 任意の音声入力に対して詳細かつ低ハルシネーションのキャプションを生成 | 音声データのアノテーション、音声理解研究 |
上記は本記事執筆(2026年1月)時点でのフリーウェイト版のモデル一覧表です。用途に応じてモデルの変更が可能です。
Qwen3-Omni-Flash系モデルの特徴
クラウド提供版のFlashモデルは、計算効率と性能の両立を目指したバージョン。
広東語を含む多様な方言サポートが強化されており、より幅広い言語環境での利用が可能になっています。
また、torch.compileやCUDA Graphによる最適化により推論の高速化がされており、VoiceBenchで89.5という高スコアを達成するなど、継続的な性能改善が図られています。
Qwen3-Omni-Flashのアップデート
2025年12月、Alibaba CloudはQwen3-Omni-Flashの大幅なアップグレード版であるQwen3-Omni-Flash-2025-12-01をリリース。
このバージョンでは、オーディオビジュアル対話が劇的に向上し、より自然で人間らしいAIとの会話が実現されています。
オーディオビジュアル会話の安定性向上
音声および視覚的指示の理解と実行能力が劇的に向上し、日常会話で頻発していた「知能低下」問題が解決されました。
複数ターンにわたる音声・映像による会話の安定性と一貫性が大幅に向上し、文脈を正確に把握しながらシームレスな対話を継続可能。
システムプロンプト制御の強化
システムプロンプトのカスタマイズが可能になり、モデルの挙動を制御できるようになりました。
ユーザーはAIモデルの人格スタイル、話し方の特徴、出力の長さまで細かく調整できます。これにより、用途に応じた最適なAIアシスタントを作り出すことが可能です。
多言語の追従性改善
テキストベースのやり取りでは119言語、音声認識では19言語、音声合成では10言語に対応。
言語追従の不安定性が完全に解消され、多様な言語的文脈においても正確で一貫したパフォーマンスを発揮するようになっています。
より人間らしい音声合成
従来のぎこちなさやロボット感が強かった話し方がアップデートに伴い解消されています。
文脈に基づいて話す速度や言葉の間、抑揚を知的に調整することで、表現力豊かで自然な音声出力を実現。
ベンチマークスコアの大幅改善
ベンチマークでは、Qwen3-Omni-Flash-2025-12-01は以前のQwen3-Omni-Flashと比較して全モダリティで大幅な性能向上を達成しています。
| モダリティ | 改善内容 | ベンチマークスコア |
|---|---|---|
| テキスト理解・生成 | 論理的推論、コード生成、文章品質で大幅な向上 | •ZebraLogic +5.6 •LiveCodeBench-v6 +9.3 •MultiPL-E +2.7 •WritingBench +2.2 |
| 音声理解 | 単語誤り率の大幅な低減、実際の会話シナリオでの理解能力向上 | •Fleurs-zh 大幅改善 •VoiceBench +3.2 |
| 音声合成 | 複数言語(特に中国語と多言語環境)で、より高品質で人間らしい音声生成を実現 | 韻律制御の大幅強化により、自然な音声出力を達成 |
| 画像理解 | 視覚的推論タスクで飛躍的な性能向上 | •MMMU +4.7 •MMMU-Pro +4.8 •MathVision_full +2.2 |
| 動画理解 | 動画の意味理解が着実に改善、音声と映像の同期がより緊密に | • MLVU +1.6 |
Qwen3-Omni-Flashの料金・無料クォータ
Qwen3-Omni-FlashはAPIで提供されており、リージョンによって無料クォータの有無が異なります。
また、思考モード(Thinking Mode)と非思考モード(Non-Thinking Mode)でコンテキスト長やトークン制限が異なるため、用途に応じて選択しましょう。
| リージョン | 無料クォータ | 有効期間 | 備考 |
|---|---|---|---|
| 海外(シンガポール) | 各モデル100万トークン(モダリティに依存しない) | Model Studio有効化から90日間 | qwen3-omni-flash、qwen3-omni-flash-2025-09-15、qwen3-omni-flash-2025-12-01など主要モデルで利用可能 |
| 中国本土(北京) | なし | – | 初回から従量課金 |
Qwen3-Omni-Flashは、思考モードと非思考モードで異なるトークン制限を持っています。
| モデル | モード | コンテキストウィンドウ | 最大入力 | 最大思考連鎖 | 最大出力 |
|---|---|---|---|---|---|
| qwen3-omni-flash | 思考モード | 65,536トークン | 16,384トークン | 32,768トークン | 16,384トークン |
| 非思考モード | 65,536トークン | 49,152トークン | – | 16,384トークン | |
| qwen3-omni-flash-2025-09-15 | 思考モード | 65,536トークン | 16,384トークン | 32,768トークン | 16,384トークン |
| 非思考モード | 65,536トークン | 49,152トークン | – | 16,384トークン | |
| qwen3-omni-flash-2025-12-01 | 思考モード | 65,536トークン | 16,384トークン | 32,768トークン | 16,384トークン |
| 非思考モード | 65,536トークン | 49,152トークン | – | 16,384トーク |
思考モードでは、複雑な推論タスク、数学・STEM問題、多段階の論理的思考が必要な場合に使うのが良いでしょう。
Chain-of-Thought(思考連鎖)を最大32,768トークンまで生成可能な一方で、非思考モードは迅速な応答が必要な対話タスク、一般的な質問応答時に利用できます。
Qwen3-Omniのライセンス
Qwen3-OmniのライセンスはApache 2.0ライセンスです。そのため、商用利用は可能、再配布や改変なども可能ですが、著作権表示とライセンス表記の保持義務はあります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 | |
| 配布 | |
| 特許使用 | |
| 私的使用 | |
なお、高性能と低コストを両立するオープンソースモデルであるGLM‑4.5/GLM‑4.5 Airについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

音声・映像利用時の注意点
Qwen3-Omniは音声・画像・動画を含むマルチモーダルデータを処理する強力なAIモデルですが、こうしたデータには個人を特定可能な情報が含まれるため、利用時には適切なプライバシー保護とセキュリティ対策が不可欠です。
録音・録画データの個人情報保護
音声データや動画データには、話者の声紋、顔の特徴、話した内容など、個人を特定できる情報が含まれています。
日本の個人情報保護法では、特定の個人を識別できる音声や映像は個人情報に該当し、GDPRでは生体データとして保護対象となります。
AIモデルで音声・動画を処理する際は、データ収集前に利用目的を明確に通知し、本人または関係者から適切な同意を取得する必要があります。
クラウド送信前のマスキング・加工
Qwen3-Omni-FlashのようなクラウドAPIサービスを利用する場合、音声・動画データはインターネット経由で外部サーバーに送信されます。
機密性の高いデータを扱う際は、送信前に個人名や電話番号などの固有名詞を「○○さん」「番号A」などに置き換えたり、動画内の顔やナンバープレートにぼかし処理を施すなど、事前のマスキングが必要になるでしょう。
APIキー・アクセス制御の徹底
APIキーは、クラウドリソースへのアクセス権限を持つ重要な認証情報です。漏洩すると第三者による不正利用やコストの発生、データへの不正アクセスのリスクがあります。
ソースコードに直接記述せず、環境変数やシークレット管理ツールを使用して安全に保管しましょう。
Qwen3-Omniの使い方
では実際にQwen3-Omniを使っていきましょう。
Chatも用意されているので、こちらを使えば手軽にQwen3-Omniを使えます。

Qwen3-Omniについては教えてくれませんでした。
また、Qwen3-Omniのデモサイトも用意されており、おそらくこのページで音声出力ができると思いますが、中国語記載です。
他にもAPI経由でも利用ができます。
API経由でQwen3-Omniを使ってみる
本記事執筆時点(2025年9月24日)で無料クォータがあるので、無料でAPIを使えそうです。
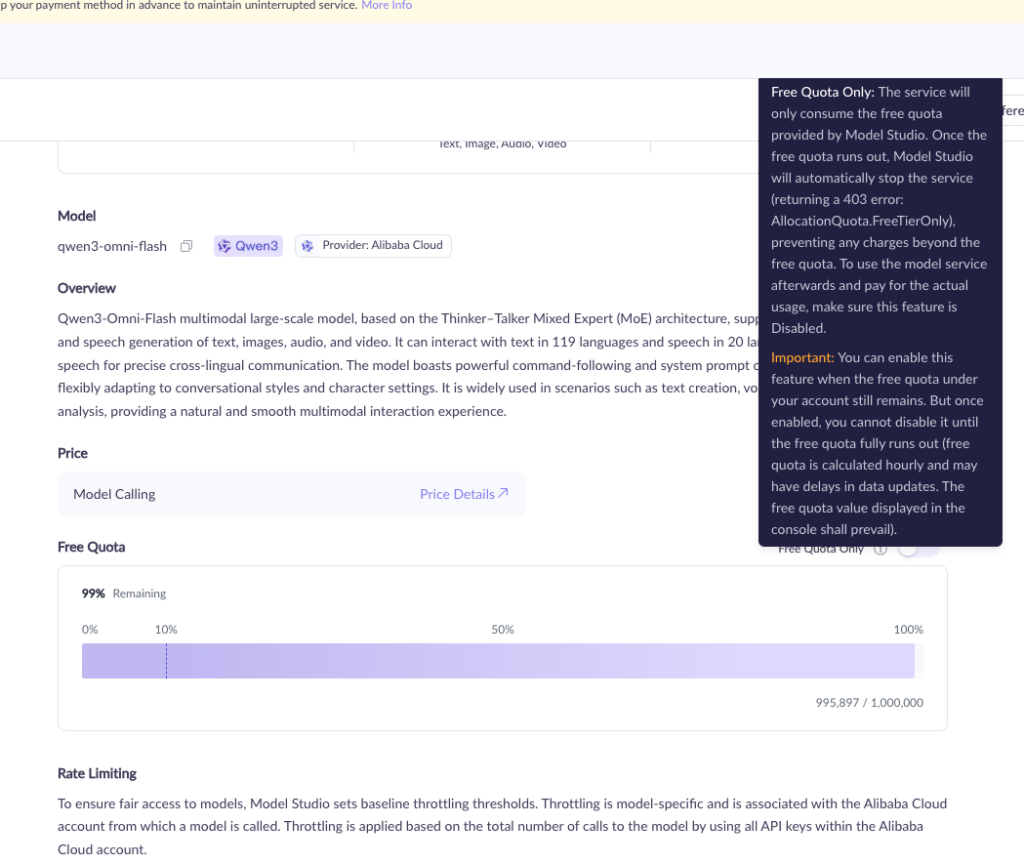
ではGoogle Colaboratoryで実装していきます。APIキーの取得がまだの場合にはアリババクラウドで取得しておきましょう。
ライブラリをインストールします。
!pip install openaiあとはサンプルコードの実行です。
サンプルコードはこちら
import os
import base64
from openai import OpenAI
client = OpenAI(
api_key="",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)
question = "生成AIが教育分野で活用される方法を教えてください。"
completion = client.chat.completions.create(
model="qwen3-omni-flash",
messages=[{"role": "user", "content": question}],
modalities=["text"],
)
answer = completion.choices[0].message.content
print("Q:", question)
print("A:", answer)結果はこちら
Q: 生成AIが教育分野で活用される方法を教えてください。
A: もちろんです。生成AI(人工知能)は教育分野において多様な方法で活用できます。以下に主な活用方法を分類してご紹介します。
---
### 1. **個別学習支援**
生成AIは生徒一人ひとりの学習ペースや理解度に合わせたサポートが可能です。
- **個別学習プランの作成**
学習者の理解度や進捗を分析し、適切な学習内容や難易度の問題を自動生成。
- **リアルタイムフィードバック**
解答を入力すると、解説や補足説明を即座に提供。誤りを指摘しながら学習を促進。
- **学習進捗の可視化**
AIが学習履歴を分析し、弱点や得意分野を可視化し、教師や生徒にフィードバック。
---
### 2. **教材・問題の自動作成**
教師の負担を軽減し、多様な教材を迅速に提供。
- **問題作成**
生成AIは教科書レベルの問題、テスト問題、練習問題を自動生成。難易度や形式も調整可能。
- **教材の多言語化・適応**
教材を英語、中国語などに翻訳し、文化に合わせた内容に調整。
- **視覚的教材の生成**
テキストから図表、イラスト、動画の概要を生成し、理解を助ける。
---
### 3. **インタラクティブな学習体験**
AIによる対話型学習が可能に。
- **AIチャットボットによる学習支援**
学生が質問すると、リアルタイムで説明や例題を提供。例:「数学の微分について教えて」。
- **仮想教師・学習アシスタント**
仮想キャラクターとして、生徒と対話しながら学習を促進。特に言語学習やプレゼン練習に有効。
- **シミュレーション学習**
医療、法律、ビジネスなどの実践的なシミュレーションをAIが提供。
---
### 4. **言語学習の強化**
生成AIは言語学習に特に効果的です。
- **会話練習**
英語などの会話練習で、AIが相手役になり、リアルタイムの会話体験を提供。
- **作文・翻訳のフィードバック**
学生の作文を分析し、文法、語彙、構成の改善点を提案。
- **多言語学習支援**
1つの言語を学ぶ際に、他の言語の説明や例文を自動生成。
---
### 5. **教師支援ツール**
教師の授業準備や評価作業を効率化。
- **授業計画の提案**
教師がテーマや学年を入力すると、適切な授業構成や活動案を提案。
- **評価・フィードバックの自動化**
学生の課題をAIが評価し、具体的なフィードバックを提供。教師の負担軽減。
- **教育コンテンツの検索・整理**
教師が適切な教材を迅速に見つけるためのAI検索ツール。
---
### 6. **特別支援教育**
個別ニーズに応じた支援が可能。
- **学習障害や発達障害の支援**
読み書きの支援、視覚的・聴覚的補助教材の生成、簡潔な説明の提供。
- **言語障害者の支援**
音声やテキストをリアルタイムで翻訳・補足。
---
### 7. **教育の公平性向上**
生成AIは教育アクセスの格差を縮小。
- **低所得地域への教材提供**
AIが無料で教材や学習支援を提供し、教育格差の解消に貢献。
- **多様な学習スタイルへの対応**
視覚的、聴覚的、運動的など、学習スタイルに合わせた教材を生成。
---
### 8. **職業教育・生涯学習**
生成AIは大人の学習にも活用。
- **スキルアップ学習**
プログラミング、ビジネススキル、デザインなど、実践的な学習支援。
- **職業訓練の支援**
AIが職業訓練の教材やシミュレーションを提供。
---
### 注意点と課題
- **情報の正確性**:生成AIの出力は誤りを含む可能性があるため、教師の確認が必要。
- **プライバシー保護**:生徒のデータを安全に扱う仕組みが必要。
- **教育倫理**:AIに頼りすぎず、人間の教師の役割を尊重。
---
### まとめ
生成AIは教育の**効率化**、**個別化**、**多様性**を実現し、教師と生徒の両方に大きな価値をもたらします。ただし、技術の導入には教育現場のニーズや倫理的配慮を十分に考慮する必要があります。
ご希望があれば、具体的な教育現場での活用事例やツールの紹介も可能です。APIが使えるとモデルを使うのが非常に手軽ですね。Qwen3-Omniは無料クォータがあるので、ぜひAPIを使ってみてください。
オープンソース版Qwen3-Omniの利用方法
クラウドAPIではなく、自社環境でのカスタマイズやプライバシーを重視する場合、Qwen3-Omni-30B-A3B系のオープンウェイト版をローカル実行することも可能です。
ただし、30Bパラメータ規模のMoEモデルをフル精度(BF16)で動作させるには、約79GBのVRAMが必要となり、コンシューマー向けGPUでは複数枚の構成が求められます。
より現実的な選択肢としては量子化版の利用。4bit量子化(AWQ)を適用すれば、VRAMの必要量を約17GB程度まで削減でき、RTX 4090(24GB)などの単一GPUでも実行可能です。
しかし、CUDA寄りの構成のため、Macでの実装は難しく筆者の環境(M4 Mac mini、メモリ64GB)では利用できませんでした。
思考モードと非思考モード
Qwen3-Omni-Flashは、思考モードと非思考モードを切り替えられます。
思考モードは、数学的推論・論理的分析・複雑な問題解決など、段階的な思考プロセスを必要とするタスクに適しています。
一方、非思考モード(デフォルト)は、一般的な会話・情報検索・要約など、即座の応答が求められるタスクに最適。思考連鎖を省略することで応答速度を向上させ、トークン消費を抑えてコスト削減にも貢献します。
デフォルトは非思考モードなので、思考モードを使う場合には以下のようにコーディングする必要があります。
from openai import OpenAI
client = OpenAI(
api_key="",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-omni-flash",
messages=[
{"role": "user", "content": "複雑な数学問題を段階的に解いてください"}
],
enable_thinking=True, # 思考モードON(デフォルトはFalse)
stream=True,
)
for chunk in completion:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")Qwen3-Omni-Flash利用時の仕様と制約
Qwen3-Omni-FlashをAPI経由で利用する際には、いくつか押さえておくべきポイントがあります。実装時に見落としがちなポイントを事前に把握しておくことで、スムーズな開発が可能になるでしょう。
ストリーミング出力が必須
Qwen3-Omni-Flashのすべての呼び出しでストリーミング出力が必須です。streamパラメータをTrueに設定しないとエラーが発生します。
非ストリーミング(一括応答)には対応していないため、必ずストリーミングレスポンスの処理実装が必要です。
音声出力はBase64エンコード形式
音声データはBase64エンコードされた文字列として返されます。実際の音声ファイルとして利用するにはデコード処理が必要。音声形式はWAV(サンプルレート24kHz、16bit)です。
画像・音声・動画の入力形式
非テキストモダリティ(画像・音声・動画)は、公開URLまたはBase64 Data URL形式で渡す必要があります。
ローカルファイルを直接パスで指定することはできません。
1つのメッセージで複数の非テキストモダリティは送信不可
1つのuserメッセージ内で複数の非テキストモダリティ(画像+音声、音声+動画など)を同時に送ることはできません。
複数のモダリティを扱いたい場合は、複数ターンに分けて送信するか、動画形式(映像と音声を含む)を利用する必要があります。
日本語で使う場合のポイント
Qwen3-Omni-Flashは日本語に対応していますが、いくつかの特性を把握しておきましょう。
音声認識については、標準的な発音であれば高精度で認識されますが、専門用語・固有名詞・方言は誤認識されることがあります。
また背景ノイズに弱いため、静かな環境での利用が推奨されます。重要な固有名詞はテキストで補足すると精度が向上します。
音声合成については、短文は比較的自然ですが、長文になるとイントネーションが平板化する傾向があります。
文体の制御については、システムプロンプトで敬語・常体を指定できます。
例えば「常に敬語(ですます調)で回答してください」と指定すると「Qwen3-Omniは、マルチモーダルAIモデルです」のような丁寧な応答になり、「常体(だである調)で回答せよ」と指定すると「Qwen3-Omniは、マルチモーダルAIモデルである」のような簡潔な応答になります。


Qwen3-omniで音声出力ができるかを検証
Qwen3-omniは多言語対応で、Speech Outputも可能の記載がGitHub上にあります。

下記のコードで生成されたテキストを音声に変換することが可能です。
「Who are you?」という問いに対して返答のテキストを生成し、それを音声に変換しています。
サンプルコードはこちら
import os
import base64
import io
import wave
import soundfile as sf
import numpy as np
from openai import OpenAI
client = OpenAI(
api_key="",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)
try:
completion = client.chat.completions.create(
model="qwen3-omni-flash",
messages=[{"role": "user", "content": "Who are you"}],
modalities=["text", "audio"], # Specify text and audio output
audio={"voice": "Cherry", "format": "wav"},
stream=True, # Must be set to True
stream_options={"include_usage": True},
)
print("Model response:")
audio_base64_string = ""
for chunk in completion:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
if chunk.choices and hasattr(chunk.choices[0].delta, "audio") and chunk.choices[0].delta.audio:
audio_base64_string += chunk.choices[0].delta.audio.get("data", "")
if audio_base64_string:
wav_bytes = base64.b64decode(audio_base64_string)
audio_np = np.frombuffer(wav_bytes, dtype=np.int16)
sf.write("audio_assistant.wav", audio_np, samplerate=24000)
print("\nAudio file saved to: audio_assistant.wav")
except Exception as e:
print(f"Request failed: {e}")かなり流暢に喋っていて、AIが喋っているとは思えない完成度です。
多言語対応とのことなので、日本語でも喋ってもらおうと思います。
イントネーションに多少の違和感はあるものの、電話やチャットの音声対応には十分耐えられる完成度だと感じます。
音声出力のカスタマイズ
Qwen3-Omni-Flash-2025-12-01では韻律制御が大幅に強化され、より人間らしい音声生成が可能です。
文脈に応じて話速・間・抑揚を適応的に調整し、ぎこちなさやロボット的な印象を排除できます。
Qwen3-Omni-Flash-2025-12-01は49種類の音声に対応しており、用途に応じて選択できます。
代表的な音声として、Cherry(女性・明るく親しみやすい)、Ethan(男性・落ち着いた印象、デフォルト)、Aiden(男性・若々しい)などがあります。音声はaudioパラメータのvoiceで指定。
システムプロンプトで挙動をコントロールする
Qwen3-Omni-Flash-2025-12-01では、システムプロンプトのカスタマイズが可能になり、モデルの振る舞いを細かく制御できるようになりました。
キャラクター設定、口調、応答の長さなど、用途に応じた調整が可能です。
なおシステムプロンプトで口調を調整したコードは下記です。
import os
import base64
import soundfile as sf
import numpy as np
from openai import OpenAI
from IPython.display import Audio, display
# 実際のAPI キーに置き換えてください
API_KEY = ""
client = OpenAI(
api_key=API_KEY,
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1", # Singapore region
)
try:
completion = client.chat.completions.create(
model="qwen3-omni-flash-2025-12-01",
messages=[
{"role": "system", "content": "あなたはフレンドリーで親しみやすいアシスタントです。ゆっくり、明瞭に話してください。"},
{"role": "user", "content": "日本の文化について簡単に教えてください"}
],
modalities=["text", "audio"], audio={
"voice": "Cherry", # 音色: Cherry(明るい女性), Ethan(落ち着いた男性), Aidenなど
"format": "wav"
},
stream=True,
stream_options={"include_usage": True},
)
print("テキスト応答:")
audio_base64_string = ""
for chunk in completion:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices and hasattr(chunk.choices[0].delta, "audio") and chunk.choices[0].delta.audio:
audio_base64_string += chunk.choices[0].delta.audio.get("data", "")
print("\n" + "-" * 50)
if audio_base64_string:
print("音声を生成中...")
wav_bytes = base64.b64decode(audio_base64_string)
audio_np = np.frombuffer(wav_bytes, dtype=np.int16)
output_file = "qwen_response.wav"
sf.write(output_file, audio_np, samplerate=24000)
print(f"音声ファイルを保存: {output_file}")
# Colab上で音声を再生
print("音声を再生:")
display(Audio(audio_np, rate=24000, autoplay=True))
else:
print("音声データが取得できませんでした")
except Exception as e:
print(f"エラーが発生しました: {e}")こちらがシステムプロンプトなしの音声です。
【システムプロンプトなし音声】
そしてこちらがシステムプロンプトで調整した音声。
【システムプロンプトあり音声】
システムプロンプトありの音声のほうが気持ち、明瞭でゆっくりに感じますが、ブラインドで聞いたら違いがわからないかもしれません。
なお、Alibaba発キャラクター動画生成AIであるWan2.2-Animateについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Qwen3-Omni-Flashの活用シーン
Qwen3-Omni-Flashのリアルタイムマルチモーダル処理能力は、様々なビジネスシーンで実用的な価値を発揮します。ここでは考えられる活用シーンを紹介します。
多言語コールセンターのリアルタイム通訳ボット
顧客が話す言語を自動認識し、オペレーターの言語にリアルタイム翻訳することで、言語の壁を越えたサポートができるでしょう。
システムプロンプトで「丁寧で簡潔な応答」を指定することで、コールセンター特有の対応品質を維持できます。
ちなみに下記の音声は「あなたはフレンドリーで親しみやすく丁寧で簡潔な応答をするコールセンタースタッフです。」「購入した商品が壊れていたので、返品返金をお願いします。」と指示を与えた時のものです。
なんかちょっと惜しいですね。部分的に中国語になってしまっています。
【コールセンター音声】
オンライン講義の自動要約+音声応答
長時間の講義動画を自動要約し、学生からの質問に対して音声で補足説明を行います。
最大40分の音声理解に対応しており、1時間の講義全体を処理可能。教育機関での復習支援や、社内研修の効率化に活用できるでしょう。
ビデオ会議の同時通訳・議事録生成
国際会議やグローバルチームの打ち合わせで、参加者が話す言語をリアルタイムに字幕表示し、会議終了後には要点をまとめた議事録と音声サマリーを自動生成もできそうです。
複数ターンにわたる会話の文脈を理解し、安定した通訳品質を維持します。
リアルタイム映像解析(店舗監視・工場ライン)
店舗での不審行動検知や、工場ラインでの製品欠陥の早期発見に活用可能です。
映像と音声を統合的に分析し、異常を検知した際には音声とテキストでアラートを発信します。
GIGAZINEで紹介された「部屋のどこかでスマートフォンの音が鳴っているが場所が分からない」という状況で、音と映像を頼りに場所を特定するデモは、この用途の実用性を示していると考えられます。
マルチモーダル活用レシピ
Qwen3-Omni-Flashは「テキスト+音声」だけでなく、様々なモダリティの組み合わせで実用的なタスクを実現可能。GitHubの公式Cookbookでいくつもの活用例が掲載されています。
例えば、画像と音声を組み合わせた商品説明では、製品写真と顧客の音声質問を同時に入力し、商品の特徴を音声で説明するECサイトの音声アシスタントを実行するコードが用意されています。
そのほかにも音声と映像を使ったタスクでは、音声指示と映像認識を組み合わせ、複雑な作業手順のガイダンスや、音声ベースの関数呼び出しによるエージェント動作も実現。
Qwen3-Omni-Flashと他モデルの比較
Qwen3-Omni-Flashはリアルタイム音声対話・映像理解・オープンライセンスを強みとします。ここでは最新のクローズドモデルおよび同シリーズの専門モデルとの比較で、どの場面に適するかを解説します。
GPT-4o (Realtime 2025-12-15)
OpenAIの音声対応モデル。テキスト・音声・画像をリアルタイムに処理し、音声エージェント用に最適化されています。クローズドAPIで動作し、商用サポートは厚いですが、ローカル実行やカスタマイズに制約があります。
Gemini 3.0 Pro
最大100万トークンのコンテキストウィンドウを持ち、長文書の理解や複雑な推論に優れます。
テキスト・画像・動画・音声のマルチモーダル入力に対応し、ネイティブTTS機能で音声出力も可能。70言語以上の音声翻訳をサポートし、リアルタイム音声対話にも対応しています。
Gemini 3.0 Flash
高速応答・低コストを重視した最新軽量版。コーディング・数学・推論・マルチモーダルベンチマークで優れた性能を発揮し、音声入出力にも対応しています。
リアルタイム性とコストパフォーマンスはQwen3-Omni-Flashと同等レベルといえます。
無料枠はQwen3-Omni-Flashと同水準で、高頻度タスクに適した「Fast Mode」を備えています。
Claude Opus 4.5
コーディング・複雑な指示追従に強く、長文の論理推論にも優れます。ただし音声入出力には対応せず、テキスト・画像の範囲に留まるため、音声対話が必要な場面ではQwen3-Omni-Flashが有利です。
Qwen3-Next-80B-A3B
テキスト推論に特化したモデルで、コンテキスト100万トークン、コーディング・論理推論で最高性能。ただしマルチモーダル入力は限定的で、音声対話・映像分析はQwen3-Omni-Flashが担当します。
Qwen3-ASR-Flash
Qwen3-ASR-Flashは音声認識専用モデルで、11言語対応・ノイズ耐性に優れ、長時間音声の文字起こしでは誤認識率が競合の半分以下。
ただし出力はテキストのみで、音声合成や映像理解が必要な場合はQwen3-Omni-Flashが必要です。
| モデル | ライセンス | 音声対話 | コンテキスト | 主な強み |
|---|---|---|---|---|
| Qwen3-Omni-Flash | オープン | ○ | 65,536 | リアルタイム・韻律制御・ローカル実行 |
| GPT-4o Realtime | クローズド | ○ | 128,000 | 商用サポート・エコシステム統合 |
| Gemini 3.0 Pro | クローズド | ○ | 1,000,000 | 超長文書・70言語音声翻訳 |
| Gemini 3.0 Flash | クローズド | ○ | 1,000,000 | 高速・低コスト・推論性能 |
| Claude Opus 4.5 | クローズド | × | 200,000 | コーディング・指示追従 |
| Qwen3-Next-80B | オープン | × | 1,000,000 | テキスト推論・コード生成 |
| Qwen3-ASR-Flash | オープン | × | – | 音声認識・ノイズ耐性 |
上記はQwen3-Omni-Flashと代表的な他モデルの比較一覧表です。上記表を参考に、ご自身の用途にあったモデルを選択してください。
Qwen3-Omni-Flashに関するよくある質問
まとめ
本記事ではQwen3-Omniの概要から実際の使い方まで解説をしました。
質問に対する返答を生成し、それを音声ファイルとして出力できるのは、従来のLLMにはなかった機能といえるでしょう。
使い方によっては、カスタマーサポートなどでかなり重宝するモデルだと思います。
ぜひ皆さんも本記事を参考にQwen3-Omniを使ってみてください!

最後に
いかがだったでしょうか?
Qwen3-Omniの実力を体験し、マルチモーダルAIの新しい可能性を試してみましょう。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

