

- ローカルLLMは機密データを外部に送信せず自社環境で処理できるため、医療・金融・製造業など規制の厳しい業界で注目
- 月間100万トークン以上なら3年間で30〜50%のコスト削減が可能だが、初期投資とTCO分析が不可欠モデル選定はGPU環境・日本語性能・用途・ライセンスの4軸で判断し、用途別に最適なツールを使い分ける
最近注目を浴びている生成AIで自社業務を効率化したいと考えるも、情報漏洩などのリスクがあることにより、導入を見送っている企業も多いのではないでしょうか。
そんなときは、ローカルLLM(ローカル生成AI)の出番です。ローカルLLMの導入には以下のようなメリットがあります。
- データのセキュリティとプライバシーが担保できる
- レスポンスタイムの短縮
- コストの削減
- コンプライアンス要件への対応
- インターネットに接続できない環境でも利用可能
最後までお読みいただくと、ローカルLLMの基本やメリット、使い方を把握できます。自社に適したローカルLLMを導入でき、業務効率化につなげられるでしょう。
\生成AIを活用して業務プロセスを自動化/
LLMの基本
生成AIが注目されて以来、LLMというワードもよく耳にするようになりました。チャットボットなど、私たちの身近なところでLLMを活用したサービスが急速に普及しています。
最初に、生成AIの主要な要素の一つであるLLMの基本をまずは押さえておきましょう。
LLMとは
ChatGPTなどの生成AIで使われているのは、LLM(Large Language Model:大規模言語モデル)と呼ばれるAIモデルです。LLMは一般的に膨大な数のパラメータを持ち、大量のデータで学習することで、文脈を高い精度で理解し、高度な文章を生成する能力を備えています。
この特性を活かし、文章の生成、要約、言語翻訳、質問への回答など、多様な領域での活用が進んでいます。
LLMの利用方法には大規模なクラウド環境で運用するクラウド型と、個人のPCや企業のサーバーで運用するローカル型があります。用途やセキュリティ要件に応じて、適切な方法を選択できます。
クラウド型LLMとローカル型LLMの違い
LLMの利用法には、クラウド型とローカル型の2つの種類があります。それぞれ特徴が異なり、用途に応じて最適な方法を選択します。
クラウド型LLMは、インターネットに接続したPCからクラウドにアクセスしてLLMを利用するタイプです。代表的なものに、Open AIのChatGPTやAnthropicのClaudeなどがあります。
クラウド上で強力な計算資源を利用できるため、インターネットに接続したデバイスさえあれば高性能モデルも利用可能です。しかし、外部とのデータ送受信が必要であり、セキュリティ面での心配があります。
ローカルLLMとは、自社サーバーや個人のPC上で動作するLLMです。自社の管理する環境で処理が完結するため、情報漏洩の心配がほとんどありません。
社外秘の情報を生成AIに入力して処理させたいときは、ローカルLLMを使用すると漏洩リスクを低減できます。しかし、高速なGPUなどのハイスペックな環境が必要になるなど運用のハードルがクラウドに比べて高い傾向にあります。
なお、生成AIの法人利用方法を知りたい方は、以下の記事をご確認ください。

クローズドソースLLMとオープンソースLLM
LLMにはもう一つ別の観点での分類があり、クローズドソースLLM(Closed Source LLM)とオープンソースLLM(Open Source LLM)です。
クローズドソースLLMとは、個人や企業が単独で所有する独占的なAIモデルのことです。ChatGPTやClaude、Geminiなどが代表例であり、ソースコードが公開されていないため、開発したLLMが模倣されにくいメリットがあります。
一方、オープンソースLLMはソースコードが無償で一般公開されているLLMで、誰でも利用できることから機能開発が進みやすいのがメリットです。
利用する環境や企業の状況によって最適なLLMは異なります。適切なモデルの選定や導入後の最適化をサポートしてくれる専門家の助言を受けることで、スムーズに運用を開始できます。


業界別のローカルLLM活用イメージ
ローカルLLMは、機密性の高いデータをクラウドに送信できない業界で特に注目されています。ここでは、代表的な業界における具体的な活用シーンを紹介します。
医療業界
電子カルテや患者の診療情報は、個人情報保護法やHIPAAなどの厳格な規制対象。
ローカルLLMを活用すれば、カルテ情報をクラウドに送信せずに院内で診断支援や文書要約を実行でき、患者プライバシーを守りながら医師の業務効率を向上させられます。診療記録の自動要約や、過去症例の検索支援などが代表的なユースケースです。
製造業界
設計図面や製造プロセスのノウハウ、品質管理データなど、企業の競争力の源泉となる技術情報を外部に出すことはできません。
ローカルLLMを導入することで、これらの機密データを社内に留めたまま、技術文書の自動生成、設計レビューの支援、不良品分析のレポート作成などを安全に実行できます。特に自動車・半導体・精密機器メーカーでの導入が進んでいます。
金融業界
金融機関は、顧客の取引履歴や与信情報、投資戦略など、FISC安全対策基準で厳重な管理が求められるデータを大量に扱います。
ローカルLLMを活用すれば、これらの機密情報をオンプレミス環境に留めたまま、融資審査の補助資料作成、リスク分析レポートの生成、顧客問い合わせ対応の効率化などが可能になります。※1
ローカルLLMのメリット
ローカルLLMの導入には、企業の特定のニーズに応じた多くのメリットがあります。データの安全性を確保しながら業務効率を向上させるだけでなく、コスト管理や柔軟なカスタマイズも可能です。
以下はローカルLLMの主要なメリットの5つです。
データのセキュリティとプライバシー
ローカル環境でLLMを運用することで、データが外部に流出するリスクを最小限に抑えられます。機密性の高い情報を扱う場合や、データの外部送信が制限されている場合に有効です。
レスポンスタイムの短縮
ローカル環境での実行は、クラウド上のサービスと比べて通信の遅延がないため、リアルタイム性が求められるアプリケーションではレスポンスが速くなります。
コスト管理
クラウドベースのLLMサービスは従量課金制が一般的で、頻繁に使用する場合や大量のデータを処理する場合、コストが高額になることがあります。ローカル環境では初期コストはかかるものの、長期的にはコストを抑えられることがあります。
コンプライアンス要件への対応
業界によっては、データの扱いに関して厳格な規制が存在し、データを外部に送信することが禁じられている場合があります。ローカルでの運用はこれに対応する手段となります。
インターネットに接続できない環境でも利用可能
ネットワークが不安定な場所(医療現場や製造業など)でも、運用ニーズを満たすことができます。
これらのメリットにより、ローカルLLMは企業にとって信頼性の高い選択肢となります。特に、セキュリティが重要視される環境やコスト管理が求められる場面では、その効果を最大限に発揮するでしょう。
これらのメリットにより、ローカルLLMは企業にとって信頼性の高い選択肢となります。特に、セキュリティが重要視される環境やコスト管理が求められる場面では、その効果を最大限に発揮するでしょう。
ローカルLLMとクラウドLLMはどちらを選ぶべきか
ローカルLLMとクラウドLLMにはそれぞれ異なる強みがあり、企業の状況や利用目的によって最適な選択肢は変わります。ここでは、具体的な条件ごとに「ローカル向き」「クラウド向き」を解説します。
ローカルLLMが向いているケース
セキュリティ・コンプライアンスを重視する企業では、ローカルLLMが最適な選択肢となります。
機密性の高い顧客情報や社外秘データを扱う場合、データを外部クラウドに送信せずに済むため、情報漏洩リスクを大幅に低減できます。
特に、GDPRや業界規制でデータの外部送信が制限されている企業、金融機関・医療機関など高度なセキュリティが求められる組織にとって、ローカルLLMは規制対応の有効な手段です。
大量トークンを継続的に利用する場合も、ローカルLLMのコストメリットが顕著。
月間数百万〜数千万トークンを処理する組織では、クラウドLLMの従量課金によるコスト変動リスクを避けられます。
3年以上の長期運用を前提としたTCO分析では、ローカルLLMが30〜50%のコスト削減を実現できるケースもあります。初期投資は必要ですが、高頻度利用であれば比較的短期間で回収可能です。
オフライン環境や低レイテンシが求められる現場でも、ローカルLLMは強みを発揮します。
ネットワークが不安定な製造現場や医療現場、インターネット接続が制限された環境では、クラウドLLMの利用が困難。また、リアルタイム処理が求められる用途では、通信遅延を排除できるローカルLLMが有利です。
クラウドLLMが向いているケース
PoCや小規模利用、初期検証フェーズでは、クラウドLLMが最適です。
AI導入の効果検証を素早く行いたい場合や、初期投資を最小限に抑えたい場合に向いています。特に、利用規模が月間数十万トークン以下の小規模運用では、クラウドLLMのコストパフォーマンスが高くなります。
最新モデルや柔軟性を重視する企業にも、クラウドLLMがおすすめです。
常に最新のLLMを使いたい場合や、複数のモデルを用途に応じて使い分けたい場合、クラウドサービスなら即座に切り替えが可能。
また、メンテナンスやアップデートを自社で管理したくない組織にとって、ベンダー側が自動的に対応してくれるクラウドLLMは運用負荷を大幅に軽減します。
ハイブリッド戦略のススメ
実際には、ローカルとクラウドを併用するハイブリッド戦略が最も効果的なケースも多くあります。用途に応じて使い分けることで、両者のメリットを最大限に活かせます。
例えば、機密データ処理にはローカルLLMを使用し、情報漏洩リスクを排除。一方で、一般的な問い合わせ対応にはクラウドLLMを活用することで、コストを抑えながら最新モデルの恩恵を受けられます。
また、開発・検証環境ではクラウドLLMを利用して迅速なプロトタイピングを行い、本番環境ではローカルLLMに切り替えることで、セキュリティと安定性を確保するアプローチも効果的です。
このように、データの機密度や業務フェーズに応じて柔軟に使い分けることで、コスト・セキュリティ・運用効率のバランスを最適化できます。
トークン課金の変動リスクとボリューム判断
一方で、クラウドLLMの従量課金制には、コスト予測が難しいというリスクがあります。
トークン単価は、1Mトークンあたり$0.15〜$15と、モデルによって大きく異なります。利用量が増えると月額コストが予想外に膨らむケースも少なくありません。また、API価格改定により突然コストが変動する可能性もあり、予算管理の観点から注意が必要です。
ボリューム別の判断基準として、以下の目安を参考にしてください。
月間10万トークン以下の場合は、初期投資が不要なクラウドLLMが有利と考えられます。
ローカルLLMの注意点

ローカルLLMを導入する際には、注意すべきポイントがあります。LLMによる業務効率化を狙っても、以下の要素を考慮しなければ、企業の信頼を落とすなど事業に致命的な悪影響をもたらす可能性もあります。
注意点を点を事前に理解し、対策を講じることで、より効果的にローカルLLMを運用できるでしょう。
ハードウェアの要件
ローカルLLMを実行するためには、相応のハードウェア性能が必要です。特に大規模なモデルの場合、GPUの性能が重要です。
十分な計算リソースがないと、モデルの動作が遅くなったり、正確な結果が得られなかったりする可能性があります。
導入前に必要なハードウェア要件を確認し、必要であればアップグレードを検討することが重要です。
メンテナンスとアップデート
クラウドベースのLLMと異なり、ローカルLLMのメンテナンスやアップデートは自社で行うか、外部の専門家に依頼する必要があります。
最新の機能を使いたい場合や、セキュリティパッチが必要な場合に、適切に対応できないとリスクが高まります。
定期的なメンテナンススケジュールを設定し、モデルや関連ツールのアップデートを確認・適用するプロセスを整備しておくことが重要です。
データの管理とセキュリティ
ローカル環境でLLMを運用することで、データのセキュリティは高まりますが、内部でのデータ管理においては依然として注意が必要です。
特に、モデルに供給するトレーニングデータや運用データの管理が不適切だと、セキュリティ上のリスクが発生する可能性があります。
トレーニングデータや運用データのアクセス制限を厳格にし、暗号化やバックアップなどのセキュリティ対策を講じることが求められます。
カスタマイズの複雑さ
ローカルLLMはカスタマイズ性が高い反面、適切な調整が行われないと、期待したパフォーマンスが得られないことがあります。特に、業務固有のニーズに合わせてモデルを微調整するには、技術的な知識と経験が必要です。
モデルのカスタマイズには、社内に専門知識を持った担当者を配置するか、外部の専門家に依頼することを検討するべきです。また、事前にテスト環境を用意し、カスタマイズの影響を確認することも重要です。
サポートの限界
クラウドベースのLLMでは通常、サービス提供者からのサポートが受けられますが、ローカルLLMではそのようなサポートが限定的であるか、自社で全てを管理する必要があります。これにより、トラブル発生時に迅速な対応が難しくなる可能性があります。
自社内での技術サポート体制を強化するか、信頼できる外部パートナーを確保しておくことが望ましいです。
モデル更新ポリシーの策定
ローカルLLMを安定的に運用するためには、モデルのバージョン管理と更新手順を明確に定めておくことが必要です。
まず、モデルバージョン管理の方法を確立しましょう。
どのバージョンをいつまで使用するか、旧バージョンの保持期間はどの程度かを明文化します。これにより、複数のモデルが混在する環境でも、どのバージョンが本番稼働中なのかを常に把握できます。
次に、新モデル導入時の検証プロセスを整備します。
新しいモデルを本番環境に投入する前に、性能・品質・安全性を確認する手順を定めておきましょう。
具体的には、テスト環境での動作確認、出力品質の評価、既存システムとの互換性チェックなどが含まれます。これにより、予期せぬ品質低下や不具合を事前に防げます。
更新頻度とタイミングも大切な検討事項です。
例えば、定期的なモデル更新は四半期ごとに実施し、セキュリティパッチや重大な不具合修正は即時適用するといったルールを設けます。業務への影響を最小限に抑えるため、更新作業は深夜や休日に実施するなど、タイミングの配慮も必要。
万が一、更新後に問題が発生した場合に備えて、ロールバック手順を確立しておきましょう。
旧バージョンへ迅速に戻せる仕組みを用意しておくことで、業務への影響を最小限に抑えられます。ロールバックの判断基準や実行手順を事前に文書化しておくことも重要です。
最後に、変更管理記録の保持を徹底。
誰が・いつ・何を変更したかの履歴を詳細に記録することで、問題発生時の原因究明や監査対応がスムーズになります。変更履歴には、変更理由、承認者、影響範囲なども含めて記録しましょう。
アクセス権限管理(RBAC)
ローカルLLMへのアクセスを適切に管理することは、セキュリティとガバナンスの両面で不可欠です。役割ベースアクセス制御を導入し、必要最低限の権限のみを付与することを徹底しましょう。
まず、ユーザー役割の定義を明確にします。管理者・開発者・一般利用者など、業務上の役割に応じて権限グループを設定します。
次に、モデルへのアクセス権限を階層化。読み取り・実行・編集・削除といった操作ごとに権限を分け、各ユーザーに必要な権限のみを付与します。これにより、誤操作や意図しないモデル改変を防止できます。
API利用時の認証・認可の仕組みも整備しましょう。
APIキーの発行と管理、トークンの有効期限設定、リクエスト元IPアドレスの制限などを実施します。APIキーは定期的にローテーションし、漏洩リスクを低減するようにしましょう。
特権アカウントの最小化も重要です。システム全体を操作できる管理者権限は、必要最低限の人数にのみ付与し、日常的な作業には使用しないようにします。
ログ管理とモニタリング
ローカルLLMの運用状況を可視化し、問題の早期発見とセキュリティインシデント対応を可能にするため、包括的なログ管理とモニタリングの仕組みの構築も必要です。
まず、アクセスログの取得・保管を徹底します。
誰が・いつ・どのモデルにアクセスしたかを詳細に記録します。ログには、ユーザーID、アクセス日時、使用したモデル名、リクエスト内容、レスポンスステータスなどを含めます。これにより、不正アクセスや異常な利用パターンを後から追跡が可能。
入力プロンプトと出力結果のロギングポリシーについては、プライバシーとセキュリティのバランスを考慮して慎重に設計します。
機密情報が含まれる可能性がある場合は、プロンプトの一部をマスキングしたり、メタデータのみを記録したりする方法も検討しましょう。記録範囲と保管期間は、業務要件とコンプライアンス規制に応じて定めます。
異常検知の仕組みを導入することで、セキュリティインシデントを早期に発見できます。
例えば、短時間での大量リクエスト、通常と異なる時間帯のアクセス、不正アクセスの試行といったパターンを自動検知し、管理者にアラートを送信する仕組みを構築します。これにより、攻撃や不正利用を迅速に察知できます。
ログの保管期間と廃棄ルールも明確に定めましょう。
コンプライアンス要件や内部監査の必要性を考慮し、適切な保管期間を設定します。保管期間が過ぎたログは、安全な方法で廃棄し、ストレージ容量の圧迫を防ぎます。
ローカルLLMを導入する方法
ローカルLLMの導入は、以下の3ステップで簡単に完了します。
- ローカルLLMを実行するためのプログラムをインストールする
- LLMを自身のPCもしくは自社サーバーにインストールする
- 1でインストールしたプログラムで2のLLMを指定してプロンプトを入力する
ローカルLLMを自身のPCで動作させるためには、特定のツールが必要です。具体例として、Ollama・Open-webui・LM Studioなどがあります。
次に、タスクを処理するLLMを自身のPCにインストールしてください。ローカル環境で動作するLLMの代表例としては、Llama-3-ELYZA-JP-8B-AWQやStableLMなどが有名です。
画像生成やコード生成など、インストールするモデルによって得意なタスクが異なるので、LLMの利用目的を明確にしたうえで選びましょう。
LLMを自身のPCにインストールしたあとは、1の手順で入手した専用プログラム上でLLMを指定して、プロンプトを入力するだけで、LLMがローカル上で簡単に動作します。


実行プログラムのインストール
ローカルLLMを自身のPCで動作させるためには、専用の実行ツールが必要です。代表的なツールとして以下があります。
| ツール名 | 特徴 | 適した利用者 |
|---|---|---|
| Ollama | コマンドライン操作に適した軽量ツール | 開発者向け。API連携が容易 |
| LM Studio | GUI搭載で直感的に操作可能 | 非エンジニアでも使いやすい |
| Open WebUI | ブラウザベースのインターフェースを提供 | チーム利用に最適 |
これらのツールは、それぞれ特性が異なるため、利用者のスキルレベルや用途に応じて選択しましょう。
モデルのインストール
次に、実際にタスクを処理するAIモデルを自身のPCにインストールします。ローカル環境で動作するモデルには、以下のような種類があります。
| 種類 | モデル名 | 特徴 |
|---|---|---|
| テキスト生成特化のLLM | Llama-3-ELYZA-JP-8B-AWQ | 日本語に強い軽量モデル |
| StableLM | 日本語対応の多様なサイズ展開 | |
| Qwen2-72B-Instruct | 多言語対応の高性能モデル | |
| 画像生成モデル | Stable Diffusion | テキストから画像を生成する画像生成AI |
| その他の拡散モデル | DALL-E、Midjourney系など |
テキスト処理にはLLM、画像生成には画像生成モデルというように、インストールするモデルによって得意なタスクが異なります。そのため、LLMの利用目的を明確にしたうえで適切なモデルを選びましょう。
プロンプト入力と実行
モデルのインストールが完了したら、導入した専用プログラム上でモデルを指定し、プロンプトを入力するだけです。これだけで、LLMがローカル環境上で動作を開始します。
ローカルLLMの実行環境・ツール比較
ローカルLLMを動かすためのツールは複数存在し、それぞれ特徴や得意分野が異なります。以下では、主要な実行環境を比較し、用途に応じた選び方を解説します。
| ツール名 | UIの有無 | 得意な用途 | 特徴・強み |
|---|---|---|---|
| Ollama | CLI中心 (GUI非標準) | PoC・API開発・本番運用 | ・コマンド1つでモデル実行可能 ・API連携が容易 ・軽量で高速動作 ・開発者向け |
| LM Studio | GUI完備 | 検証・初心者向け | ・直感的なGUI操作 ・モデル検索から実行まで一貫 ・非エンジニアでも扱いやすい ・チャット形式で対話可能 |
| Open WebUI | Web UI | チーム利用・本番運用 | ・ブラウザからアクセス ・複数ユーザーでの共有が容易 ・Ollama等と組み合わせて利用 ・ChatGPT風のインターフェース |
| llama.cpp | CLIのみ(基本) | カスタマイズ・組み込み | ・最も軽量(90MB未満) ・CPU実行に最適化 ・量子化モデル(GGUF)対応 ・他ツールの基盤技術 |
| text-generation-webui(oobabooga) | Web UI | 高度なカスタマイズ・実験 | ・多機能な設定オプション ・多様なモデル形式対応 ・拡張機能が豊富 ・上級者向け |
初心者にはLM Studio、開発者にはOllama、チーム利用にはOpen WebUI、軽量実行にはllama.cpp、高度なカスタマイズにはtext-generation-webuiがそれぞれ推奨されます。
日本語対応のおすすめローカルLLM
ここからはローカル環境で使えるおすすめのLLM12モデルの特徴や強みを解説していきます。ローカルLLMのモデル選択で悩んでいる方は参考にしてみてください。
Qwen2-72B-Instruct
Qwen2-72B-Instructは、アリババ社のQwenグループが開発している大規模言語モデルです。大規模な言語およびマルチモーダルデータが事前にトレーニングされており、アリババ社のモデルには視覚や音声理解等も可能なモデルもあります。
また、英語や中国語を含む27の言語でトレーニングされているのも特徴。複数言語が出現してしまうコード・スイッチングの現象も対策されています。
Qwenファミリーには、用途に応じて選べる多様なモデルがあります。
画像理解が必要な場合はQwen2-VL、音声処理が必要な場合はQwen2-Audioを選択できます。さらに、テキスト・画像・音声をすべて統合的に扱えるQwen2.5-Omniも提供されています。
なお、Qwen2-72B-InstructをローカルLLMとして使う際は、インストールに料金が発生しません。ローカルLLMを無料で使いたい方は、ぜひチェックしてみてください。
Qwen2-72B-Instructについては、以下の記事で詳しく解説しています。

Command R
カナダのAIスタートアップ企業であるCohereは、Command RというLLMを開発しています。パラメータ数が35億のCommand Rに加えて、1,040億のCommand R+も利用可能です。法人向けを想定したLLMであり、日本語にも対応しています。
2024年7月には、富士通株式会社と戦略的パートナーシップを締結し、プライベート環境で利用できる日本語LLMを共同開発しています。
gemma-2-baku
gemma–2-bakuは、rinna株式会社が開発する高性能な日本語LLMです。Googleが公開しているLLM「Gemma 2 2B」に、日本語と英語の学習データ800億トークンを用いて継続事前学習を行っています。
gemm 2 baku の日本語性能は、各分野において高いスコアを示しています。
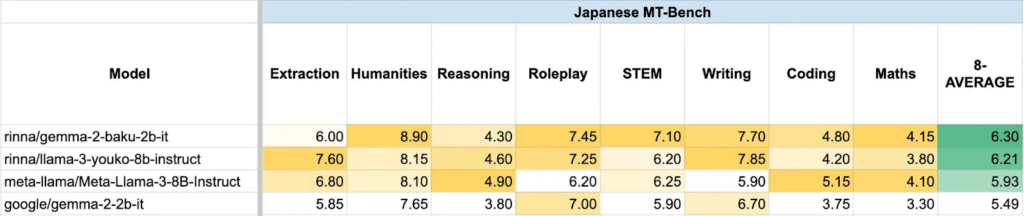
Gemma 2 2Bはパラメータ数が26億と比較的軽量ですが、高度なテキスト生成能力を持ちます。軽量なモデルはハイパフォーマンスな環境を必要とせず、導入が用意である点もメリットです。
また、追加学習も比較的容易なため、自社の目的に合わせてカスタマイズすることも可能です。
Llama-3-ELYZA-JP-8B-AWQ
Llama-3-ELYZA-JP-8B-AWQは、株式会社ELYZAがリリースした日本語特化型のLLMです。Meta社の「Llama 3」をベースとしながら、日本語とその周辺知識について多くのデータを学習させています。
モデルの量子化によりPCにかかる計算負荷が小さく、メモリ使用量も比較的少ないため、ハイスペックな環境でなくても動作可能です。
なお、日本語の処理能力においては、GPT-3.5 TurboやClaude 3 Haikuを超えているとのこと。そのほか、各種ベンチマークテストにおいて、名だたるLLMよりも高性能であることを証明しています。
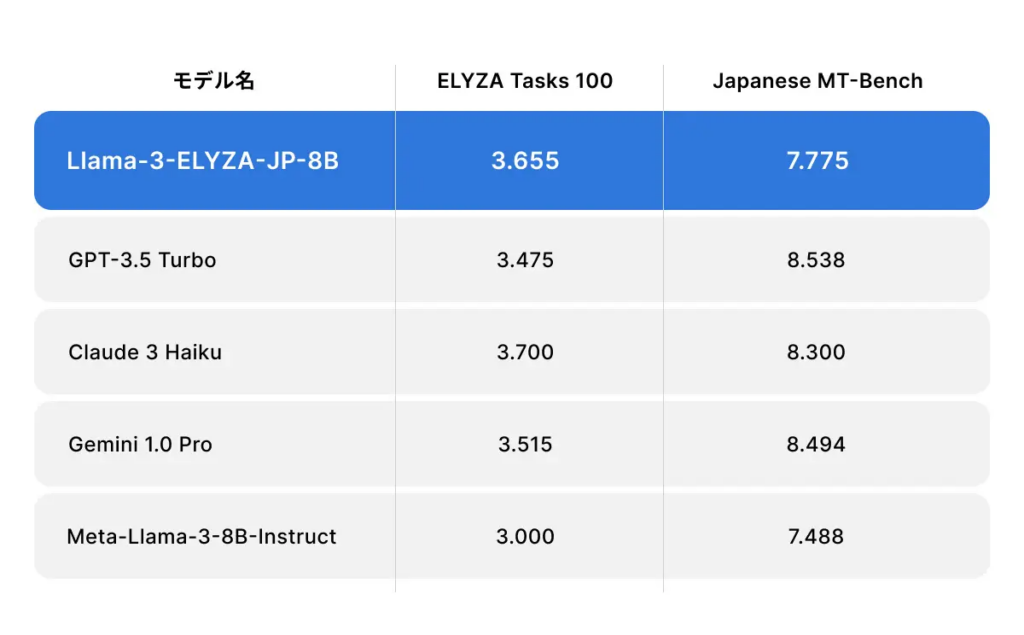
日本語の出力や読み込み精度にこだわりたい方は、ぜひローカルLLMとして活用してみてください。また、モデルは一般公開されており、商業目的での利用が可能です。
CyberAgentLM
CyberAgentLMは、サイバーエージェント社が開発した日本語特化型のLLMです。膨大な日本語データでトレーニングされており、225億ものパラメータを備えています。
とくに、高い日本語処理能力を備えているのが特徴。微妙なニュアンスも理解して文章を生成できるので、丁寧な言葉遣いが求められるビジネスメールの作成などにも向いています。
ローカルLLMとしての利用が可能なほか、配布や商用利用等の目的で使用することも許可されているので、さまざまなニーズに対応できるのが強みです。
CyberAgentLMについて詳しく知りたい方は、以下の記事もチェックしてみてください。

StableLM
StableLMは画像生成AIのStable Diffusionでおなじみ、Stability AIが開発したローカルでも使えるLLMのシリーズです。歴代モデルは以下のとおりになります。(※2)
- StableLM-Alpha models(3B / 7B):日本語対応
- StableLM-Alpha v2(3B / 7B)
- StableLM-3B-4E1T(3B)
- Stable LM 2 1.6B
- Stable LM 2 12B
- Stable LM Zephyr 3B
- Japanese Stable LM 1.6B:日本語特化
どのモデルも、近年の高性能LLMと同様のTransformerアーキテクチャを採用し、推論速度やメモリ効率が最適化されているのが特徴です。特にStable LM 2シリーズでは、位置埋め込みの効率化や不要なバイアス項の削除など、細部にわたる最適化が施されており、限られたハードウェアリソースでも高性能を発揮できるよう設計されています。
なお、StableLMについて詳しく知りたい方は、以下の記事をご確認ください。

Llama 3.3 Swallow
Llama 3.3 Swallowは、Meta社のLlama 3.3を基盤に、日本語能力を強化した70BのローカルLLMです。こちらは日本語理解・生成において優れたスコアを記録していて、GPT-4oに次ぐ性能を示しています。
なお、ベースのLlama 3.3について詳しく知りたい方は、以下の記事をご確認ください。

Gemma 3
Gemma 3は、Gemini と同じ研究と技術を用いて作られた軽量オープンモデルです。こちらは高い計算効率がアピールポイントで、GPU1個またはTPU1個で稼働させられます。以下のような用途で活躍してくれるでしょう。
- テキスト生成
- 推論
- コード解析
- 対話型タスク
クラウド環境でもスムーズに活用できるのも特徴です。GPU1個またはTPU1個で稼働可能な設計により、ラップトップやワークステーション、さらにはスマートフォンでも動作します。
また、クラウド環境でもスムーズに活用できるのも特徴。
1B、4B、12B、27Bの4つのサイズ展開により、ハードウェア環境や性能要件に応じて最適なモデルを選択できます。さらに、140以上の言語をサポートし、128Kトークンの大規模なコンテキストウィンドウを備えているため、グローバルな用途にも対応可能です。
なお、Gemma 3について詳しく知りたい方は、以下の記事をご確認ください。

DeepSeek-V3
DeepSeekチームが開発したDeepSeek-V3は、ローカルでも動せるオープンソースLLMの最強格。以下の工夫がなされていて、なんとGPT-4oやClaude 3.5 Sonnetに匹敵する性能を誇ります。
- 14.8兆トークンのデータで事前学習済み
- Mixture-of-Experts(MoE)で処理を効率化
- ファインチューニング(SFT)と強化学習(RLHF)で最適化
- 独自の負荷分散戦略とマルチトークン予測目標も採用
中国発のLLMでありながら、日本語に対応しているのも特徴です。
なお、DeepSeek-V3について詳しく知りたい方は、以下の記事をご確認ください。

DeepSeek-R1
同じくDeepSeekチームのDeepSeek-R1は、ローカル&日本語対応の推論モデル(Chain-of-Thoughtを駆使するLLM)です。こちらは教師なし学習をフル活用して開発されていて、コストパフォーマンスが抜群。それでいて、数学・コード生成・推論…etc.のタスクでOpenAI o1に匹敵する性能を示しています。
なお、DeepSeek-R1について詳しく知りたい方は、以下の記事をご確認ください。

Mistral NeMo
Mistral NeMoは、MistralとNVIDIAが共同開発した12BパラメータのローカルLLMです。その特徴は以下のとおりで、日本語を含む多言語で高性能を発揮します。
- コンテキストウィンドウは128Kトークン
- 効率的なトークナイザー「Tekken」を採用
- 推論・知識・コーディングが得意
- 多言語対応で、韓国語やアラビア語などでも高性能
その性能は、Gemma 2 9BやLlama 3 8Bなどのライバルをも上回ります。
なお、Mistral NeMoについて詳しく知りたい方は、以下の記事をご確認ください。

Phi-3.5-mini-instruct
Phi-3.5-mini-instructは、Microsoft製LLMのPhi-3ファミリーの1モデルです。こちらはローカルで稼働する軽量モデルで、以下のスペックを持ち合わせています。
- コンテキストウィンドウは128kトークン
- 数学・コード・論理問題…etc.複雑な推論に特化
- ファインチューニング(SFT)と強化学習(RLHF)で最適化
- 日本語対応
そのほかPhi-3ファミリーからは、処理をより効率化した「Phi3.5 MoE」やマルチモーダル対応の「Phi 3.5 Vision Instruct」といったLLMも登場しています。
なお、Phi 3.5について詳しく知りたい方は、以下の記事をご確認ください。

ローカルLLM選定のチェックポイント
ローカルLLMを選ぶ際は、以下の4つの軸で自社のニーズを整理すると、最適なモデルを効率的に絞り込めます。
用途・タスクの明確化
まず、LLMを使って何をしたいのかを明確にしましょう。用途によって最適なモデルは大きく異なります。
テキスト生成・チャットには、Gemma 3、Mistral NeMo、Llama-3-ELYZA-JP-8B-AWQが推奨されます。要約・文書処理では、Qwen2-72B-Instruct、Command R、CyberAgentLMが適しています。
コード生成・プログラミング支援には、Phi-3.5-mini、DeepSeek-V3、Mistral NeMoが有効です。推論・数学・論理問題では、DeepSeek-R1、Qwen2-72B-Instructが強みを発揮します。
マルチモーダルを必要とする場合は、Gemma 3やQwen2-VLを検討しましょう。
日本語性能の重要度
日本語での利用頻度や精度要件によって、選ぶべきモデルが変わります。
日本語特化が必須の場合は、Llama-3-ELYZA-JP-8B-AWQ、CyberAgentLM、Japanese Stable LM、gemma-2-baku。これらは日本語データで追加学習済みで、日本語ベンチマークで高スコアを記録しています。
多言語対応を重視する場合は、Qwen2-72B-Instruct、Mistral NeMo、Gemma 3が適しています。
英語メイン・日本語サブの環境では、DeepSeek-V3、Phi-3.5-mini、Llama 3.3 Swallowが良いでしょう。
判断基準として、日本語のみ・日本語メインなら日本語特化モデルを最優先し、多言語環境・グローバル展開なら多言語対応モデルを選択、英語メインなら汎用モデルでも十分対応可能です。
利用環境・ハードウェアリソース
自社のハードウェア環境に合わせたモデル選定が重要。高性能モデルでも、環境が整っていなければ動作しません。
GPUなしの場合は、gemma-2-baku、Phi-3.5-mini、StableLM 1.6Bなど、軽量モデルのみが実用的です。
ミドルレンジGPUでは、Llama-3-ELYZA-JP-8B-AWQ、Gemma 3 4B、StableLM 7Bなど、7〜8Bの量子化モデルが快適に動作します。
ハイエンドGPUでは、Gemma 3 27B、Mistral NeMo 12B、CyberAgentLM 22Bなど、1GPUで動かしやすい最新モデルが選択肢となり、中小企業に最適です。
複数GPU / エンタープライズ環境では、Qwen2-72B-Instruct、DeepSeek-V3、Llama 3.3 Swallow 70Bなど、最高峰性能のモデルが利用可能です。大規模企業向けの構成となります。
設置場所に応じた推奨も重要です。
個人PC・ワークステーションでは軽量〜中量モデル、オンプレミスサーバーでは中〜大規模モデルで複数ユーザー同時利用が可能、クラウドインスタンスでは任意のモデルサイズでスケーラビリティを重視できます。
ローカルLLMを使用して業務を効率化しよう

ローカルLLMは、自社サーバーやPCなどのローカル環境上でタスクを処理できるため、セキュリティを強化できるメリットがあります。
ローカルLLMとして混同されがちですが、オンプレミスにLLMを入れるのと、個人のコンピュータにローカルLLMを入れるのでは大きく意味が異なります。
- オンプレ環境に生成AIを導入する場合、企業の内部ネットワークに生成AIを設置し、専用のサーバーで運用。
- 個人のコンピュータにローカルLLMを導入する場合、個人のPCに軽量なAIモデルをインストールし、利用。
ローカルLLMの導入は3ステップで完了します。
- ローカルLLMを実行するためのプログラムをインストールする
- LLMを自身のPCもしくは自社サーバーにインストールする
- 1でインストールしたプログラムで2のLLMを指定してプロンプトを入力する
生成AIで業務を効率化しつつ、セキュリティ面も万全にしておきたい方は、ぜひローカルLLMを導入しましょう。

最後に
いかがだったでしょうか?
ローカルLLMを導入することで、自社の機密情報を安全に処理し、コストやコンプライアンスの課題も解決できます。業務に最適なモデル選定や運用方法をサポートし、効果的な活用を実現しましょう。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

【監修者】田村 洋樹
株式会社WEELの代表取締役として、AI導入支援や生成AIを活用した業務改革を中心に、アドバイザリー・プロジェクトマネジメント・講演活動など多面的な立場で企業を支援している。
これまでに累計25社以上のAIアドバイザリーを担当し、企業向けセミナーや大学講義を通じて、のべ10,000人を超える受講者に対して実践的な知見を提供。上場企業や国立大学などでの登壇実績も多く、日本HP主催「HP Future Ready AI Conference 2024」や、インテル主催「Intel Connection Japan 2024」など、業界を代表するカンファレンスにも登壇している。

