- 生成AIが誤情報を生成する「ハルシネーション」は利用時の最大のボトルネック
- 生成AIの動作原理上、ハルシネーションの完全防止は困難
- ハルシネーションが訴訟問題に発展した事例もあり、検証体制とAIリテラシー強化が重要
生成AIに潜む「ハルシネーション」というリスクをご存じでしょうか?
ハルシネーションとは、生成AIがもっともらしく事実とは異なる情報を出力してしまう現象のことで、一般に「AIの嘘」としても知られています。こちらは生成AIの原理上、避けることの難しい最大の弱点です。
そんなハルシネーションですがなんと、訴訟問題にまで発展した事例も。また、訴訟に至らなくても、ハルシネーションが企業や個人の信頼を損ねるおそれがあります。
今回の記事では、便利な生成AIがもつ弱点「ハルシネーション」の概要や実例、対策方法などについて詳しく解説します。ビジネス、特に社外とのやり取りが絡む用途に生成AIを活用予定の方は必読です。
\生成AIを活用して業務プロセスを自動化/
ハルシネーションとは
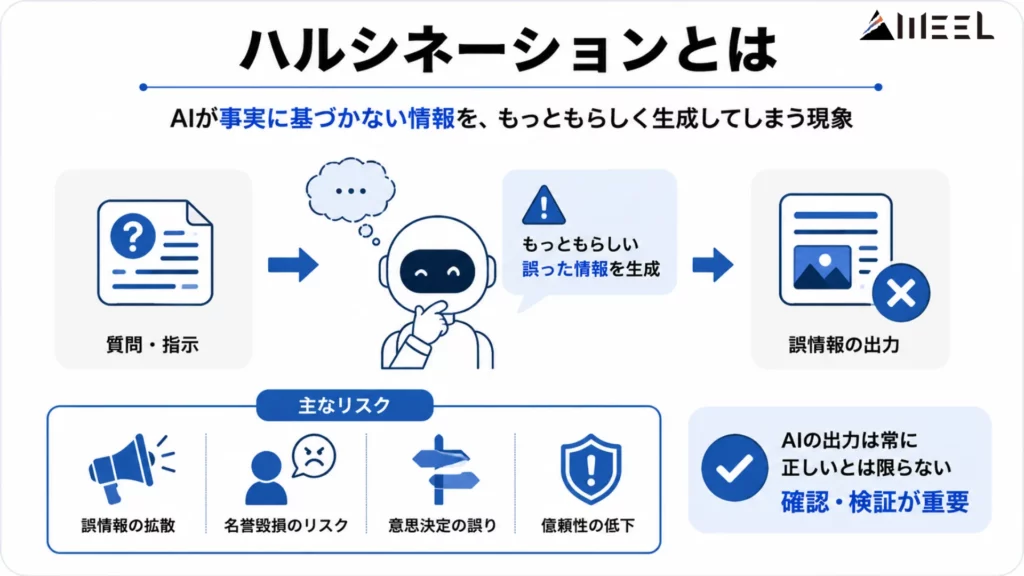
ハルシネーションとは、AIが事実に基づかない情報を、もっともらしく生成してしまう現象を指します。本来は「幻覚」という意味の言葉ですが、生成AIがまるで幻を見ているかのように誤った情報を出力するため、この名称が使われています。
この現象は特に大規模言語モデル(LLM)によるテキスト生成や、画像生成AIにおいて顕著です。例えば、存在しない論文を引用したり、歴史上存在しない出来事を語ったり、画像に実在しない人物やオブジェクトを描き出すことがあります。
ハルシネーションは単なる誤答にとどまらず、ビジネスや教育、医療などでの利用は深刻なリスクに直結しかねません。実際に、誤情報の拡散や名誉毀損、意思決定の誤りに発展した事例も報告されています。
さらに、2025年9月にOpenAIが発表した論文では、GPT-5においてもハルシネーションを完全に防ぐことは困難であると明らかにされました。※5
原因としては、学習データの曖昧さ、「次の単語を予測する」という仕組み、現行の評価方法が誤出力を助長している点が挙げられます。解決策としては、評価指標を見直し、不正解にはペナルティを課す一方で「わかりません」といった不確実性を表明する回答に部分点を与えるなど、モデルが誠実に振る舞える仕組みが提案されています。
その他の生成AIのリスクと対策方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

ハルシネーションの種類
AIのハルシネーションには、異なるタイプがあり、それぞれが異なる形で誤った情報を生成する仕組みを持っています。主なハルシネーションの種類には、以下のようなものがあります。
事実ハルシネーション
AIが実際には存在しない情報を事実として提示する現象です。例えば、歴史的な人物やイベントについての質問に対して、実在しない出来事や架空の人物を作り出すことがあります。
これは、モデルが学習データから誤った関連付けを行い、信憑性のない情報を生成することが原因です。
文脈ハルシネーション
質問の意図や前後の流れを誤って解釈し、文脈にそぐわない回答を返す現象です。例えば「AIの医療利用」に関する質問に対して、「画像生成AIの活用事例」など別の分野の回答をしてしまう場合があります。これは、ユーザーの意図を正しく把握できず、関連性の低い知識を結びつけてしまうことが原因です。
構造ハルシネーション
正しい質問に対しても、AIが誤った構造やフォーマットで回答を生成する現象です。例えば、リスト形式で答えるべき質問に対して、AIが段落形式で応答したり、期待される数値やデータをテキストの形で提供してしまう場合です。
これは、AIが適切な回答形式を誤認した場合に発生します。
創造的ハルシネーション
完全に架空の情報や新しい概念をAIが生成する現象です。例えば、科学的な質問に対して、現実に存在しない理論や用語を作り出すことがあります。
これは、AIが「創造的」な思考を行う際に事実を無視して、独自の回答を生成することにより生じます。


ハルシネーションの事例
ここでは、生成AIのハルシネーションにより実害が生じた事例を5つご紹介します。
マーク・ウォルターズ氏の例
訴訟を起こしたのは、「アームド・アメリカ・ラジオ」というラジオ番組の司会者を行なっているマーク・ウォルターズ氏。こちらの男性が係争中の実際の訴訟について説明を求めたところ、「ウォルターズがセカンド・アメンドメント財団から資金をだまし取り、不法に自分のものにした」とありもしない事実を、なんと虚偽の告訴状まで作って回答されたとのことです。
マーク・ウォルターズ氏は詐欺や横領を働いていないので、名誉を毀損されたとして訴訟を起こしています。※1
スティーブン・シュワルツ氏の例
アメリカの弁護士スティーブン・シュワルツ氏は、クライアントの訴訟のためにChatGPTを使用して法的調査を行いました。シュワルツ弁護士は、ChatGPTが提供した6件の裁判例をもとに法廷での主張を展開しましたが、後にその裁判例が実在しないものであることが判明しました。
ChatGPTは実際には存在しない判決を捏造し、それらを本物の裁判例として引用したのです。このことで、シュワルツ弁護士と彼の法律事務所は裁判所から5,000ドルの罰金を科されることになりました。※2
エアカナダの例
エアカナダでは、公式サイト上の生成AIチャットボットが実在しない割引を紹介し、利用者とのトラブルが生じた事例があります。こちらでは最終的に、エアカナダ側が責任を問われることになりました。※6
このケースは、生成AIを顧客対応に使う際のリスクを示す代表例といえます。ユーザー視点で生成AIの回答は企業からの公式案内の一部であるため、回答内容の責任はしばしば企業側が負うこととなります。
生成AIを顧客対応に活用する際、特に料金・契約・補償などに関わる案内に適用する場合は、人間によるダブルチェックの体制が欠かせません。
Meta「Galactica」の例
Metaが公開した「Galactica」は、科学知識を専門に扱うLLMです。こちらは論文の要約や科学的な文章の生成などを支援するモデルとして注目されました。
ですが、非科学的な内容や誤った情報に対しても、もっともらしい回答を返してしまう問題が浮上。その結果、Galacticaのデモは公開からわずか2日ほどで停止されています。※7
内容の正確性が求められる科学分野、特に研究・医療・教育などの領域で生成AIを使う場合は、専門家によるチェックが特に重要でしょう。
Google「Bard」の例
Googleの生成AIチャット「Bard」でも、発表時のデモ動画でハルシネーションが起きました。
こちらでは、「ジェームズ・ウェッブ宇宙望遠鏡の新発見について、9歳の子どもに教えてあげられることは?」という質問に対して、Bardが「太陽系の外の惑星の写真を初めて撮影した」と誤って回答しています。※8
この誤回答は大きく報じられ、生成AIの信頼性に対する議論を呼びました。


ハルシネーションが起こる原因
ハルシネーションが起こるのは、主に以下の4点が原因として考えられています。
- 学習データの誤り
- 文脈を重視した回答
- 情報が古い
- 情報の推測
それぞれの原因を詳しく見ていきましょう。
学習データの誤り
AIは、インターネット上に存在する大量のデータを学習源としています。インターネット上には、不正確な情報も多く存在するので、これらを学習してしまった結果、ハルシネーションを起こしてしまうという仕組みです。
特に問題視されるのが、偏った見解やフィクションも学習の対象になるということです。誤った学習データを基に生成された情報は、もちろん誤った情報になるので注意しなければなりません。
文脈を重視した回答
AIは、情報の正確性よりも文脈を重視して回答を生成することがあります。これは、入力されたプロンプト(指示文)に対し、自然な形で回答しようとしているからです。
しかし、文章を最適化する過程で情報の内容が変化してしまうことがあるため、正確ではない情報が出力されます。
情報が古い
時代が変化することによって、昔の常識が現代では通用しないということがよくあります。最新の情報に関しては、AIの学習データに含まれていない可能性があるので、ハルシネーションが発生します。
GPTやGeminiなどのモデルには、それぞれ学習データを取得した最終日付、いわゆる「知識のカットオフ」が存在。カットオフ以降の出来事や最新研究については、プロンプトやWeb検索由来で最新情報を参照するか憶測で回答するしかないため、正しい情報提供が困難となります。
情報の推測
AIは、学習データを基に、推測した情報を出力することがあります。これは、ユーザーが求める情報を提供しようと、無理やり回答を生成してしまうためです。
推測で出力された情報は、あくまで予想に過ぎないので、正確な情報とはいえません。出力された文脈だけでは、推測で出力されていることを見極めにくい場合もあるので注意しましょう。
アルゴリズムの限界
大規模言語モデル(LLM)は、与えられた文脈に基づいて次に来る単語を予測するように設計されていますが、この予測が必ずしも事実に基づいていないことがあります。
特に外部のデータベースにアクセスせず、訓練データだけをもとに判断を行うため、誤った情報を生成することがあるのです。
また、LLMは大量のデータからパターンを学習するものの、データの偏りや不十分さによって間違った関連付けを行い、架空の事実や文脈を作り出すことが多いです。この設計上の限界が、AIが現実には存在しない情報を生成する要因となっています。
研究による指摘
OpenAIが2025年9月に公開した論文では、ハルシネーションが残る原因として「学習データの曖昧さ」に加え、「評価方法の問題」が挙げられました。現在の評価基準では「わからない」と答えると不利になるため、AIは不確実でも推測して答える傾向があります。※5
生成AIのしくみについて詳しく知りたい方は、下記の記事も併せてご確認ください。

ハルシネーションによるビジネスリスク
ここでは生成AIのハルシネーションがもたらすビジネス上でのリスクについて3つご紹介します。
誤情報の発信による企業の信用低下
生成AIの出力はハルシネーションが含まれた状態のまま使うと、誤った情報を企業名義で発信してしまう可能性があります。例えば、以下の情報を誤って記載した場合、顧客や取引先からの信頼を損なうリスク要因となるでしょう。
- 製品仕様
- 料金
- キャンペーン内容
- 実績 など
特に、Webサイトやプレスリリース、SNS投稿などは外部から見られる情報です。一度誤情報が広がると、訂正しても「確認体制が甘い企業」という印象が残ることもあります。生成AIを広報・マーケティングに使う場合は、公開前のファクトチェックを必ず挟むことが大切でしょう。
AIを用いたファクトチェック方法は下記で解説

法務・医療・金融など専門領域での判断ミス
法務・医療・金融などの専門領域では、生成AIのハルシネーションが重大な判断ミスにつながる可能性があります。例えば、存在しない法律や判例をもとに契約判断をしたり、誤った医療情報を参考にしたり、金融商品のリスクを過小評価したりするケースが考えられます。
これらの領域では、少しの誤りが損害や法的責任を生じかねません。生成AIは調べ物や文書作成の補助には便利ですが、専門家の判断を置き換えるものではありません。重要な意思決定に使う場合は、弁護士・医師・会計士などの専門家による確認を前提にする必要があります。
法務・医療・金融における生成AI活用については下記で解説



顧客対応ミスによるクレーム・損害賠償リスク
チャットボットやメール返信の自動化に生成AIを使う場合、誤った回答がそのまま顧客対応ミスにつながるリスクも。例えば、実際には対象外の返金・割引・保証内容を案内してしまうと、クレームや損害賠償に発展する可能性が考えられます。
顧客から見ると、生成AIの回答も企業からの正式な案内の一部です。そのため、「生成AIが間違えた」と説明しても、企業側の責任を免れるのは難しいでしょう。特に契約・料金・補償・個人情報に関わる問い合わせでは、回答範囲を限定し、人間が確認するフローを用意しておくことが重要です。
生成AI全般のリスクは下記で解説


ハルシネーションの具体例
ここでは、実際にChatGPTを使用して、どのようにハルシネーションが起きるのかを紹介します。ハルシネーションは、事実ではないことを本当のことのかのように出力するため注意が必要です。以下を参考に、ハルシネーションがどのように起きるかを参考にしてください。
架空のアニメに関する質問
架空のアニメ「綺麗なクレヨンしんちゃん」について聞いてみました。
ChatGPTの回答はこちらです。
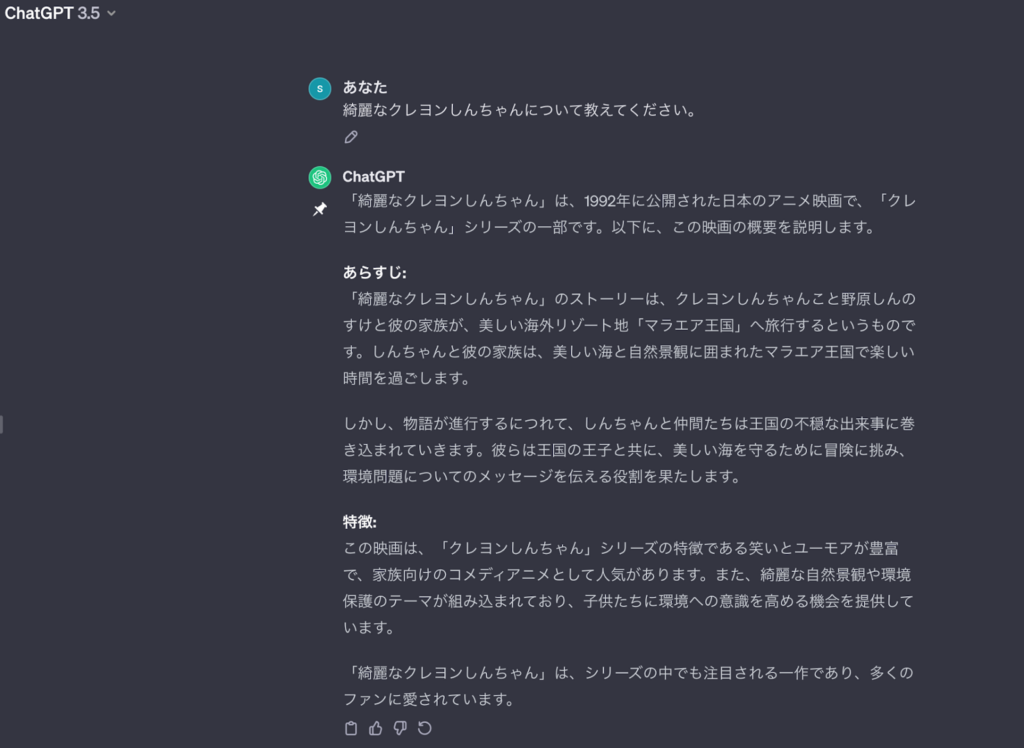
本当にこの映画が公開されているのか調べると、1992年にクレヨンしんちゃんはテレビアニメの放送が開始されていました!そして、1993年に最初の映画が公開されました。そのため、1992年に公開された「綺麗なクレヨンしんちゃん」という映画はありません。
しかし、ChatGPTは「綺麗なクレヨンしんちゃん」についてあらすじから特徴まで詳しく説明しています。ここまで具体的に出力されていると、騙されてしまいそうですね。
湖に関する質問
「日本で2番目に大きい湖」について聞きました。
回答はこちらです。

まさかの「琵琶湖」が2番目に大きい湖として出力されました。日本で1番目に大きい湖は「琵琶湖」です。そのため、ChatGPTは間違った情報を出力しています。
2番目に大きい湖で「琵琶湖」が出たので、1番目に大きい湖も聞いたところ「琵琶湖」が出力されました。これでは、ChatGPTが出力する情報を信用することは危険ですね。
地理に関する質問
「日本で2番目に広い都道府県」について聞きました。

ChatGPTは、2番目に広い都道府県は「青森県」と出力しました。実際に調べたところ、2番目に広い都道府県は「岩手県」でした!ChatGPTが回答した「青森県」は、8番目に広い都道府県です。
ついでに、1番広い都道府県を聞いたところ「北海道」と回答し正しい情報でした。ChatGPTは、間違った情報を出力したり、正しい情報を出力したりするため全ての情報を信じることはできませんね。
歴史上の人物についての質問
歴史上の人物「加藤清正」について聞きました。
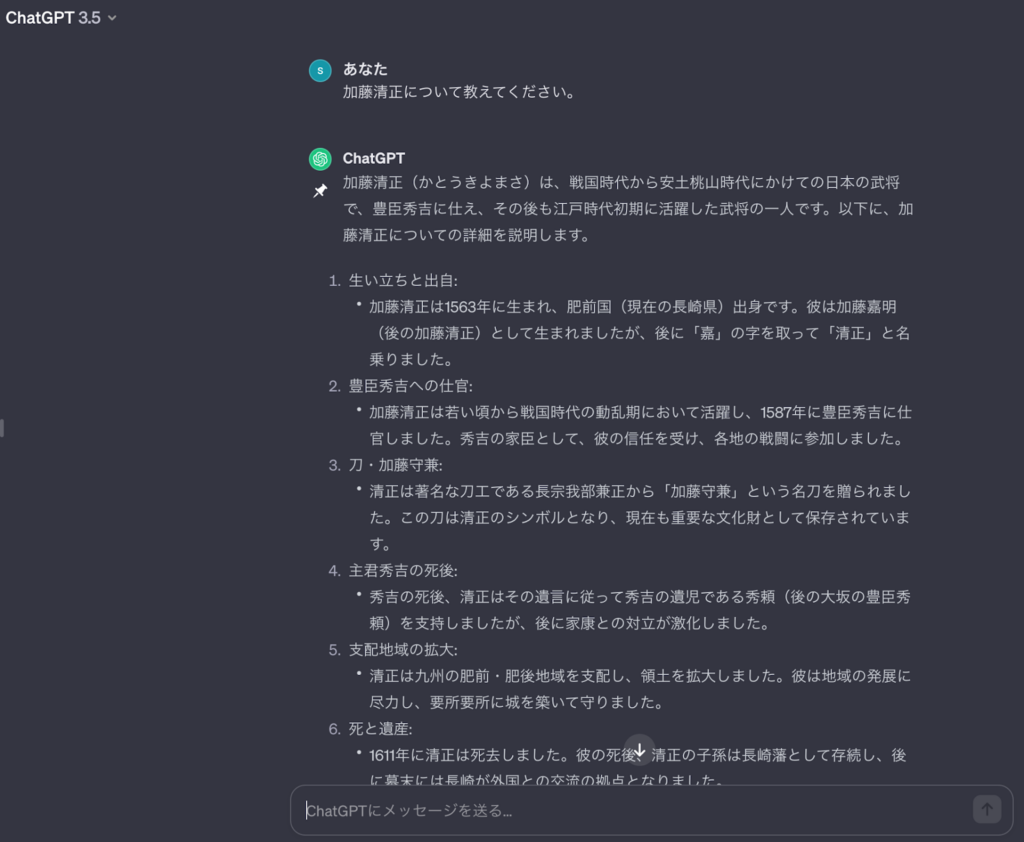
加藤清正の生涯について詳しく出力されていますが、間違った情報が出力されています。加藤清正は1563年生まれではなく、1562年生まれです。また、肥前国(現在の長崎県)出身ではなく、尾張中村(現在の愛知県名古屋市)出身です。
しかし、全て間違っている情報ではなく、1611年に加藤清正は亡くなっています。
架空の戦いについての質問
実際に存在しない「御所浦の戦い」について聞きました。
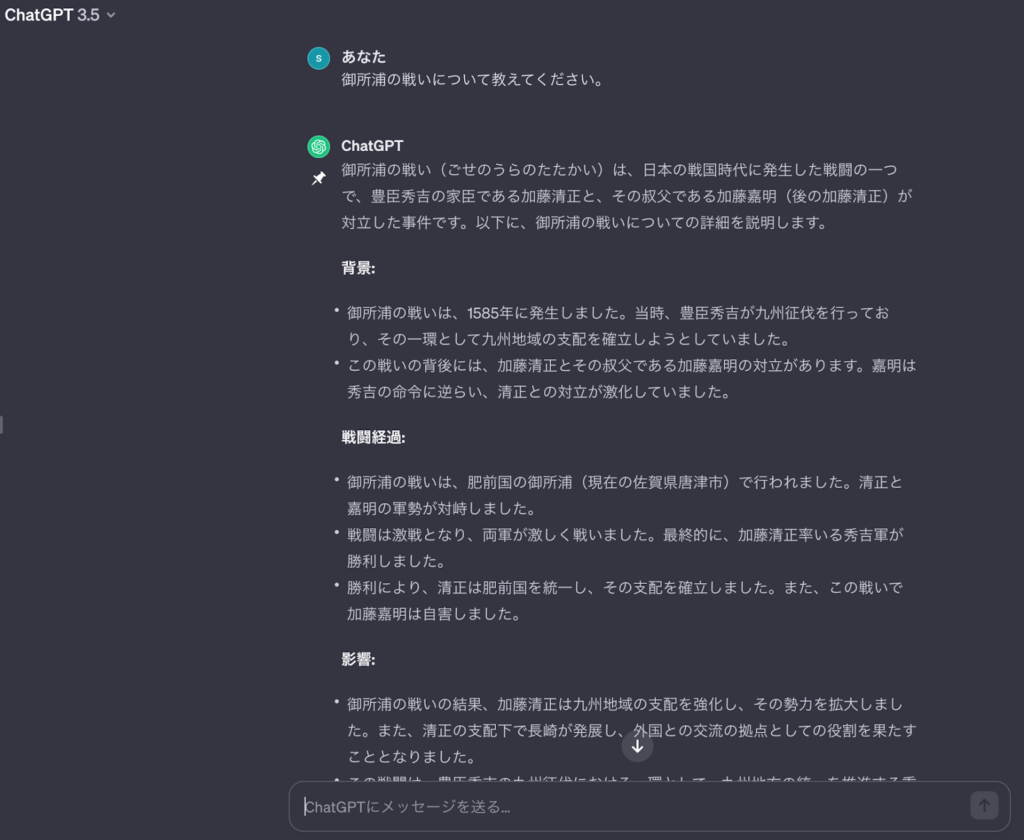
存在しない戦いなのに、詳しく説明されています。加藤清正について聞いた時に出力されていた「肥前国」がまた出力されています。しかも、今回は佐賀県の唐津市と回答しています。
先ほどの回答では、長崎県と出力していたのに嘘の情報です。ハルシネーションは、このような形で出力されるので必ず正しい情報か確認することが重要です。答えを作らず、不確実性を表明するよう誘導できます。
AIリスクを避けるために身に付けるべきAIリテラシーについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

生成AIを社内で利用する際のハルシネーション対策
生成AIを社内で利用する際は、ハルシネーション対策を事前に講じておくことが大切です。具体的には、以下の対策を行いましょう。
- アルゴリズムの改善
- データ品質の向上
- 偽情報や不正確な情報を回答することを念頭におく
- ガイドラインを作成する
- 回答結果の確認プロセスを構築する
それぞれ具体的な対策を以下で解説していくので、ぜひ参考にしてみてください。
アルゴリズムの改善
生成AIの出力精度を高めるには、モデルそのものの設計改善が不可欠です。
- 強化学習(RLHF)による人間からのフィードバック
- より高度なアテンションメカニズムの導入
- 外部知識を取り込む「RAG(検索拡張生成)」
これらにより、文脈理解の精度を高め、誤推論を減らすことが可能になります。
データ品質の向上
AIの精度は学習データの質に直結します。
- 信頼できる一次情報に基づくデータセットを利用
- 誤情報やノイズを除外
- 偏りを防ぐために多様なソースをバランスよく収集
こうした工夫により、生成結果の信頼性が大きく向上します。
偽情報や不正確な情報を回答することを念頭におく
まずは、AIが偽情報や不正確な情報を回答する可能性があることを念頭におきましょう。あらかじめ予測ができていれば、ハルシネーションによる被害を防ぐことができます。
特に危険なのが、「AIが出力する情報は全て正しい」という思い込みです。文脈が整理されており、どこか説得力のある文章に見えてしまいますが、まずは疑うところから始めてみてください。
ガイドラインを作成する
社内で生成AIを利用する際のルールや注意点をまとめたガイドラインを作成し、従業員に周知しましょう。
- メールや社内ポータルで配布
- ポスターや研修での啓蒙
- 行政機関(文部科学省・総務省)が公表しているAI利用ガイドラインの参照
組織全体で共通認識を持つことが、リスク低減の第一歩です。
また、文部科学省や総務省など行政機関からも生成AIの取り扱いに関するガイドラインが発表されています。そちらを活用するのも有効な対策となります。※3
回答結果の確認プロセスを構築する
生成AIで情報を出力した後は、必ず回答された情報の整合性をチェックすることが大切です。毎回確認するようにプロセスを構築しておけば、自然とハルシネーションによる被害が減っていきます。
情報の正誤を判断する際は、以下を参照するのがおすすめです。
- 公的機関や行政のサイト
- 専門家が運営しているサイト
- 企業のサイト
- 新聞記事
- 論文や学術記事
基本的には、信頼できる1次情報から内容を確認し、AIが出力された情報が事実に基づいていることを確かめましょう。
ハルシネーションの完全な対策は困難
ハルシネーションは、企業や個人の信頼を一瞬で損なう可能性がある深刻な課題です。しかし、生成AIの仕組みそのものに起因するため、完全に防止することは現状の技術では不可能といわれています。
OpenAIが2025年9月に発表した研究でも、GPT-5を含む大規模言語モデルでは、学習データの曖昧さや自己予測に依存する仕組みから、ハルシネーションをゼロにするのは難しいです。評価基準そのものが「不確実でも回答することを促す設計」になっている点も、根本的な要因とされています。※5
そのため、企業や個人が生成AIを利用する際は「ハルシネーションは一定確率で必ず起きる」という前提を持ち、リスクを低減する仕組みを導入することが重要です。
- 出力内容のファクトチェックを徹底する
- AIリテラシーを社内外で浸透させる
- ガイドラインやレビュー体制を整備する
ハルシネーションの問題を調査するために行われた研究結果について詳しく知りたい方は、下記の記事を合わせてご確認ください。

AIを使ったハルシネーション対策AIの開発
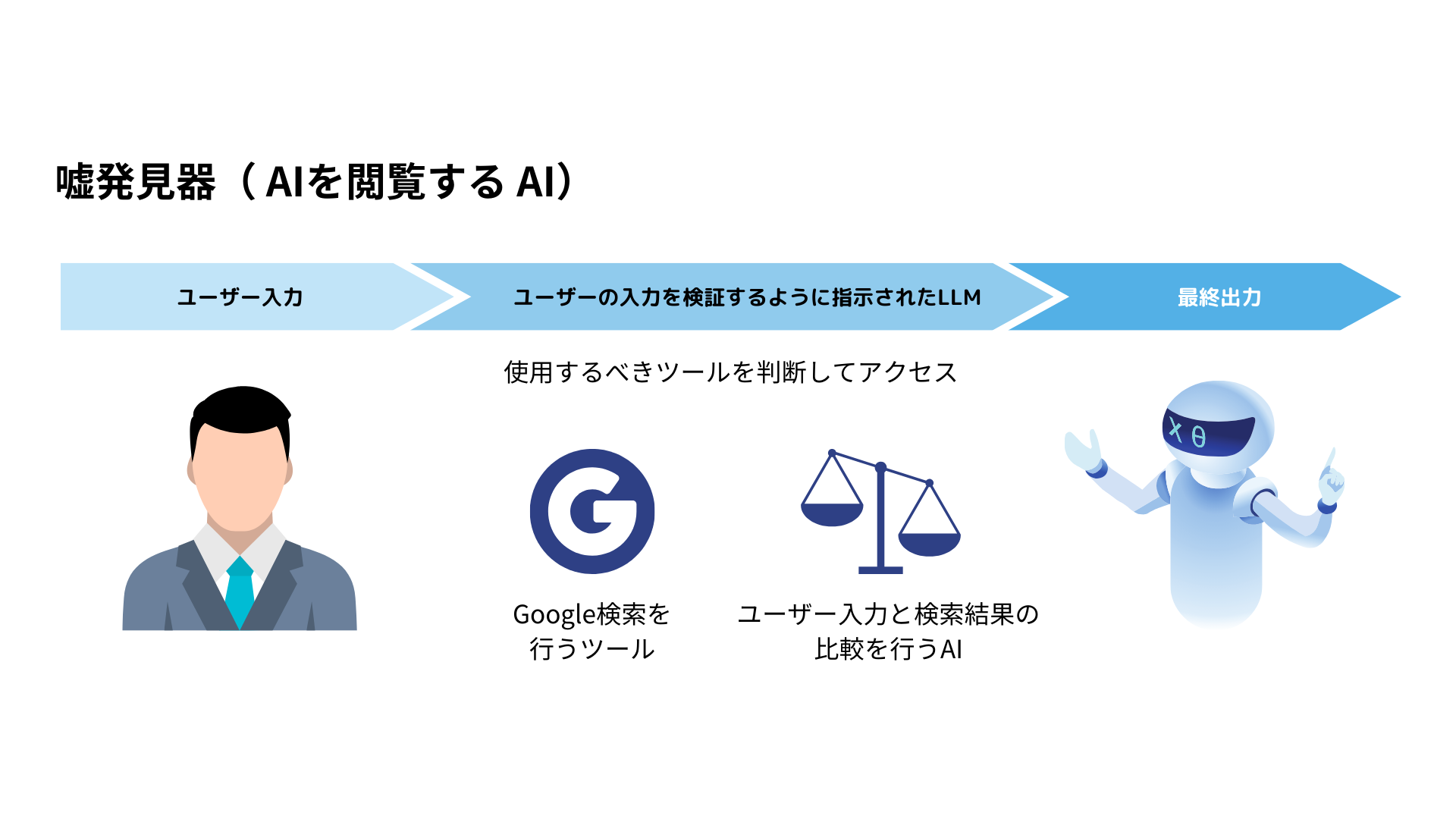
弊社では、ハルシネーション対策ができるAIの開発実績があります。
生成AIには、”ハルシネーション“という「嘘の情報を本当のことのように話す」振る舞いが問題視されています。
弊社では、様々な手法でこの問題の対処に取り組んでいますが、1つの手法として「AIを検閲するAI」の開発を行っています。
この例では、AIが生成した回答が正しいのかどうか、Google検索などので取得したデータソースにアクセスし、本当の情報であるかどうか検証しています。
他にも、論文データベースや自社の正しい情報のみが載っているデータにアクセスすることで、より高度な検閲機能の実装が可能です。
AIを使ったハルシネーション対策AIの開発に興味がある方には、まずは1時間の無料相談をご用意しております。
こちらからご連絡ください。
ハルシネーションを抑えるグラウンディング機能を持つAI検索エンジンを知りたい方は、以下の記事もご覧ください。

ハルシネーションについてのよくある質問
ここでは、生成AIのハルシネーションに関するよくある質問・FAQに答えていきます。
ハルシネーションを前提に生成AIを賢く活用しよう
生成AIでは誤った情報をもっともらしく回答する「ハルシネーション」という現象がみられます。こちらは生成AIの動作原理上、完全防止が難しい最大の弱点で、過去にはハルシネーションが原因で訴訟に発展した事例もあります。
そんなハルシネーションですが、ダブルチェックやRAGなどによりある程度までなら対策が可能。うまく付き合っていくことで、生成AIの恩恵を最大限に受けられるでしょう。

最後に
いかがだったでしょうか?
生成AIの導入は、正しいリスク理解と運用設計が鍵です。自社の業務に最適なAI活用戦略を構築し、ハルシネーションを防ぎながら生産性を最大化する方法を紹介します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。
- ※1:Forbes「OpenAI Sued For Defamation After ChatGPT Generates Fake Complaint Accusing Man Of Embezzlement」
- ※2:$2000 Sanction in Another AI Hallucinated Citation Case
- ※3:文部科学省「生成AIの利用について」
- ※4:Aligning language models to follow instructions
- ※5:Why Language Models Hallucinate
- ※6:https://www.bbc.com/travel/article/20240222-air-canada-chatbot-misinformation-what-travellers-should-know
- ※7:New Meta AI demo writes racist and inaccurate scientific literature, gets pulled – Ars Technica
- ※8:Google shares lose $100 billion after company’s AI chatbot makes an error during demo | CNN Business
- ※9:Influence of Topic Familiarity and Prompt Specificity on Citation Fabrication in Mental Health Research Using Large Language Models: Experimental Study

【監修者】田村 洋樹
株式会社WEELの代表取締役として、AI導入支援や生成AIを活用した業務改革を中心に、アドバイザリー・プロジェクトマネジメント・講演活動など多面的な立場で企業を支援している。
これまでに累計25社以上のAIアドバイザリーを担当し、企業向けセミナーや大学講義を通じて、のべ10,000人を超える受講者に対して実践的な知見を提供。上場企業や国立大学などでの登壇実績も多く、日本HP主催「HP Future Ready AI Conference 2024」や、インテル主催「Intel Connection Japan 2024」など、業界を代表するカンファレンスにも登壇している。