- DeepSeekは中国発のオープンソースLLMのシリーズ
- ChatGPT並みの高性能を低コストで提供するLLM
- 汎用モデル / コーディング特化モデル / 推論モデル / 蒸留モデル等、多彩なモデルで構成
みなさん!ChatGPT超えの生成AIが無料で使える、で話題のLLM「DeepSeek」を覚えていますか?
当時注目を集めた「DeepSeek-V3 / DeepSeek-R1」は比較的有名ですが、その基礎となった先代モデルやさらなる進化を遂げた最新モデルはご存知でない方も多いはず。実は、まだまだDeepSeekは注目株です。
当記事では、そんなDeepSeekの歴代モデルを一挙紹介!大まかなスペックや世代間での進化を中心に、生成AI初心者の方にもわかりやすくお伝えしていきます。
完読いただけると、無料で使える超高性能LLMの最前線にキャッチアップできます。
ぜひぜひ、最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
DeepSeekとは
「DeepSeek」は、中国・杭州のDeepSeek社が開発するオープンソースLLM(大規模言語モデル)のシリーズです。こちらは同名のWebアプリ / モバイルアプリ / APIからAIチャットが提供されているほか、GitHub / Hugging Faceからモデル本体も公開されています。

このDeepSeekは、モデルの訓練を効率化する技術を多数採用している点が特徴で、低コストながらハイエンドモデル(GPT-4oやOpenAI o1等)並みの文章生成・推論を可能としています。


DeepSeekモデル一覧
| モデル名 | 主な特徴 | 登場時期 |
|---|---|---|
| DeepSeek LLM | 67Bパラメータの初代大規模言語モデル(チャット対応) | 2023年11月 |
| DeepSeek Coder | 初代コーディング特化モデル(236Bパラメータ) | 2023年11月 |
| DeepSeek-V2 | V1改良版。高コスパな汎用LLM | 2024年5月 |
| DeepSeek Coder V2 | コーディング特化の進化版。長コンテキスト対応 | 2024年6月 |
| DeepSeek R1-Lite-Preview | R1の蒸留軽量版。計算速度・リアルタイム応答重視(商用利用制限あり) | 2024年11月 |
| DeepSeek-V3 | 671BパラメータのフラッグシップLLM(MoE構造)。汎用・多タスク対応 | 2024年12月 |
| DeepSeek R1 | 論理・数学・コードなど推論特化モデル。高精度ロジック処理 | 2025年1月 |
| DeepSeek-R1-Distill | 合成データ等でファインチューニングしたR1派生モデル | 2025年1月 |
| DeepSeek-V3-0324 | V3の改良版。推論・Web連携強化、MITライセンス | 2025年3月 |
| DeepSeek-R1-0528 | R1のアップデート版(推論系の更新) | 2025年5月 |
| DeepSeek-V3.1 | V3/R1統合モデル。最大128K長文対応。思考モード/即答モード切替 | 2025年8月 |
| DeepSeek-V3.1-Terminus | V3.1系の更新(のちのV3.2-Expのベースとされる) | 2025年9月 |
| DeepSeek-V3.2-Exp | 実験版。次世代機能の試験実装 | 2025年9月 |
| DeepSeek-V3.2 | V3.2-Expの後継(App/Web/APIで提供) | 2025年12月 |
| DeepSeek-V3.2-Speciale | 推論重視の高計算版(API限定) | 2025年12月 |
| DeepSeek-OCR 2 | ドキュメント理解/OCR向けVLM(3B)。DeepEncoder V2で人間に近い読み順を学習し、複雑レイアウト(列・表・ラベル/値対応など)のOCRを改善 | 2026年1月 |
ここでは、DeepSeekの歴代モデルについて、その特徴・性能をご紹介していきます。
DeepSeek LLM
「DeepSeek LLM」は2024年1月に登場した、DeepSeekシリーズの初代モデル。こちらは英語・中国語を含む2兆トークンのデータセットでゼロから構築された完全オリジナルのモデル(≠Llama等の既製LLMベース)になります。その性能は下記のとおりです。
- パラメータ数は7Bと67Bの2種類(1B=10億)
- 数学とコーディングが得意分野
- 中国語での性能も高く、自社テストではGPT-3.5を凌駕
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
DeepSeek Coder
「DeepSeek Coder」は2024年1月に、DeepSeek LLMに続いて登場した、コーディング特化のモデルです。こちらは英語・中国語に加え、80以上のプログラミング言語を含む2兆トークンのデータセットで訓練されており、下記の性能を有します。
- パラメータ数は1.3B / 5.7B / 6.7B / 33Bの4種類
- 複数のコーディングタスクでGPT-3.5 Turboと同等以上のスコアを記録
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
このDeepSeek Coderは、コーディングでの問題解決能力を測るテスト「HumanEval」にてGPT-3.5 Turboを超えるスコアを記録しており、すでに一線級のスペックを誇っていました。
DeepSeek-V2
2024年5月に登場した「DeepSeek-V2」は、8.1兆トークンのデータセットで訓練された、DeepSeek LLMの後継モデルです。こちらは回答生成に必要なパラメータだけを部分的に稼働させる技術「Mixture-of-Experts(MoE)アーキテクチャ」を採用。下記のとおり、低コストかつ高性能な汎用モデルとなっています。
- パラメータ数は16B / 236Bの2種類
- MoE採用により、2.4B / 21Bモデル相当の低計算コストを実現
- 訓練コストは先代(DeepSeek LLM)から42.5%減
- KVキャッシュ(≒メモリ消費)は先代の93.3%減
- 最大生成スループット(≒処理速度)は先代の5.76倍UP
- 質問全般、特に中国語でGPT-4やGPT-4 Turboに匹敵する性能を発揮
- 日本語にも対応
- コンテキストウインドウ(入力の上限)は16Bモデルが32K、236Bモデルが128K
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
DeepSeekはこのV2の代より、「低コストで使えるChatGPT」のポジションを築き始めました。
なお、DeepSeek-V2について詳しく知りたい方は下記の記事も併せてご確認ください。

DeepSeek-Coder-V2
2024年6月リリースの「DeepSeek-Coder-V2」は、DeepSeek Coderの後継にあたるコーディング特化モデルです。こちらはDeepSeek-V2同様、MoEアーキテクチャを採用しており、低コストでGPT-4 Turbo並みの性能を発揮します。(下記)
- パラメータ数は16B / 236Bの2種類
- MoE採用により、2.4B / 21Bモデル相当の計算コストを実現
- 対応プログラミング言語は86種から338種に大幅増加
- コーディング・数学のタスクでGPT-4 Turboと同等以上の性能を発揮
- 英語・中国語のタスク全般でも、DeepSeek-V2と同等の性能を維持
- 日本語にも対応
- コンテキストウィンドウは全モデルで128K
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
DeepSeek-V2と同様に、ダウンロードして無料で使えるオープンソースモデルでありながら有料モデルに匹敵する性能を誇り、登場当時から注目を集めていました。
DeepSeek-R1-Lite-Preview
「DeepSeek-R1-Lite-Preview」は、2024年11月に登場したDeepSeekシリーズの新路線。こちらはステップバイステップで熟考して回答を生成する「推論モデル」の試作版です。そのスペックは下記のとおりで、大手のハイエンドモデルを押さえて一躍最先端のモデルとなりました。
- 性能は当時登場したばかりの推論モデル「OpenAI o1-preview」に匹敵
- 特に、数学・コーディングの分野でOpenAI o1-previewと同等以上の性能を発揮
- 日本語にも対応
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
このDeepSeek-R1-Lite-Previewは、後述するDeepSeek-R1へと系譜が続きます。
DeepSeek-V3
「DeepSeek-V3」は、2024年12月にリリースされた、DeepSeek-V2の後継モデル。こちらはより最適化された「MoEアーキテクチャ」や通信を効率化する「DeepEPフレームワーク」等、新技術を採用しており、さらなるコストカット・性能向上を実現しています。その性能は下記のとおりで、ChatGPTのハイエンド汎用モデル「GPT-4o」に匹敵するレベルです。
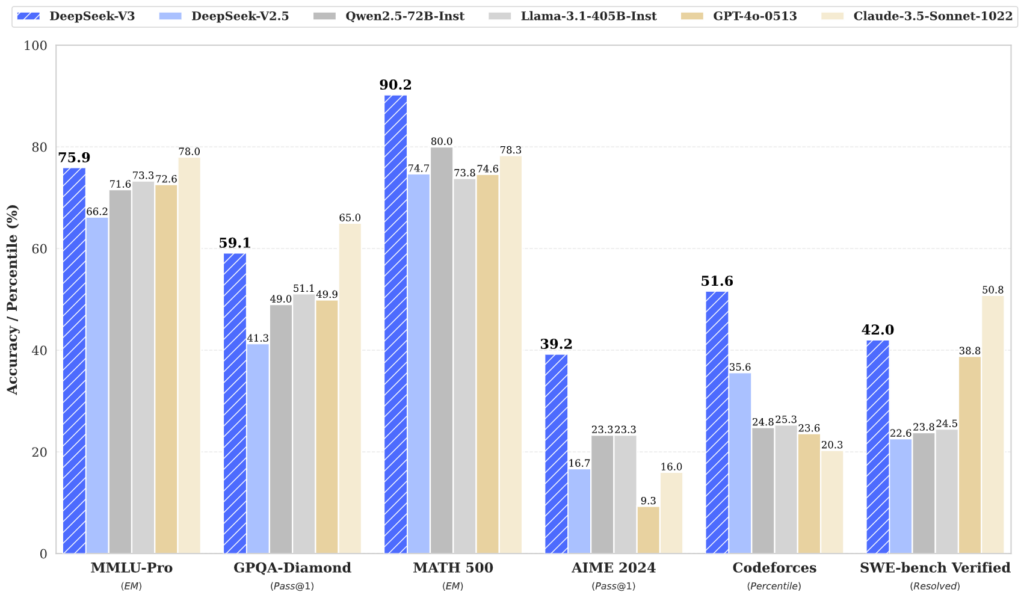
- パラメータ数は671B(計算コストは37B相当)
- 「DeepSeek R1」シリーズの推論能力を蒸留により一部継承
- 推論・数学・コーディングの分野で、GPT-4oやClaude 3.5 Sonnetと同等以上の性能を発揮
- 日本語にも対応
- コンテキストウィンドウは全モデルで128K
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
このDeepSeek-V3は、Webアプリ / モバイルアプリの「DeepSeek」より無料で公開され、当時話題を集めました。
なお、DeepSeek-V3について詳しく知りたい方は下記の記事も併せてご確認ください。

DeepSeek-R1
「DeepSeek-R1」は2025年1月に登場した、正式リリース版の推論モデルです。こちらは強化学習(RL)メインでトレーニングが組まれており、自力で最適な推論パターンを導き出す能力に長けています。その性能は以下のとおりです。
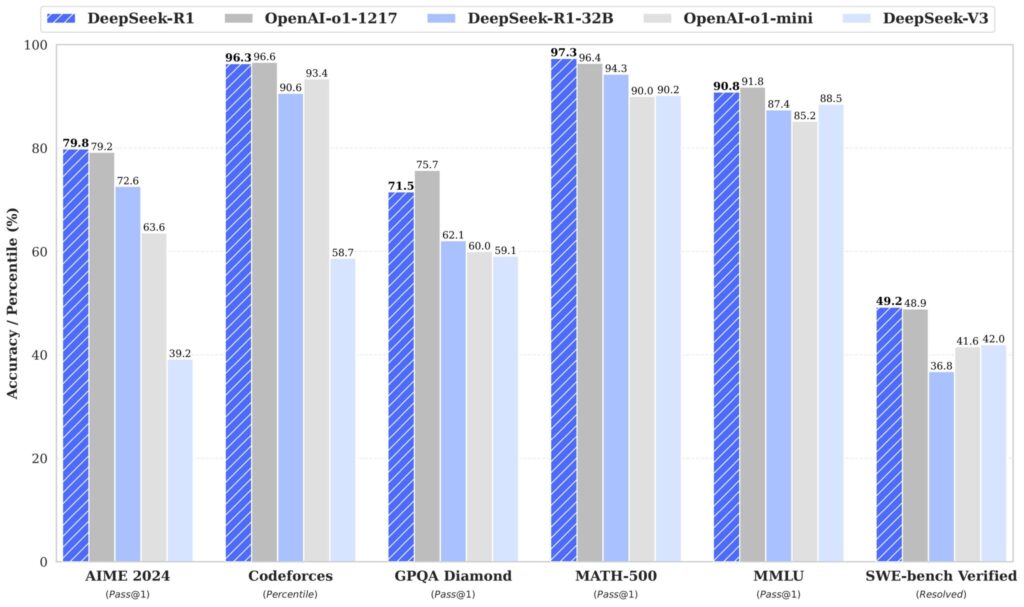
- 「R1-Zero(RLのみ)」と「R1(教師あり学習済)」の2モデル構成
- パラメータ数は671B(計算コストは37B相当)
- 推論・数学・コーディングで、OpenAI o1(正式リリース版)相当の性能を発揮
- 日本語にも対応
- コンテキストウィンドウは全モデルで128K
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
このDeepSeek-R1も、Webアプリ / モバイルアプリ版DeepSeekで公開されており、「無料でOpenAI o1級のモデルが使える」と話題になりました。
なお、DeepSeek-R1について詳しく知りたい方は下記の記事も併せてご確認ください。

DeepSeek-R1-Distill
同じく2025年1月に登場した「DeepSeek-R1-Distill」は、DeepSeek-R1の推論パターンを小型LLMに移植した蒸留モデルです。その詳細は下記のとおりで、小型ながらに一線級のスペックを誇ります。
- QwenベースとLlamaベースの大きく2系統に分岐
- Qwen系についてはパラメータ数が1.5B / 7B / 14B / 32Bの4種類
- Llama系についてはパラメータ数が8B / 70Bの2種類
- Qwen系の32BモデルはOpenAI-o1-miniを上回る性能を発揮
- Qwen系は「Apache 2.0ライセンス」で商用&私的利用・改変・配布・特許使用が可能
- Llama系はLlamaのライセンスに準拠(公開先のユーザー数により制限あり)
ローカル環境で動かせるLLMのなかでは、最高峰といえる性能でしょう。
DeepSeek-V3-0324
「DeepSeek-V3-0324」は2025年3月に登場したDeepSeek-V3の改良版で、下記の性能を備えています。
- 基本設計はDeepSeek-V3に準拠
- タスク全般・数学・コーディングでの性能が向上
- Function Calling(外部ツール連携)の精度も改善
- 日本語にも対応
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
こちらはAIエージェントやAIツールとしての使用も想定したセッティングが特徴です。
DeepSeek-V3.1
「DeepSeek-V3.1」は2025年8月にリリースされた、DeepSeek-V3の後継モデル。こちらは先代比で全般的に性能が向上しているほか、推論のON・OFFを切り替えられる「ハイブリッド推論」を採用している点が特徴です。
- パラメータ数は685B
- 1モデルで推論あり / 推論なしの両方をこなす「ハイブリッド推論」を採用
- 低コストでDeepSeek-R1と同等以上の性能を発揮
- 特に、コーディング・検索タスクでの性能が向上
- ツール使用の能力や複雑なタスクの実行能力も向上、よりAIエージェント向きに
- 日本語にも対応
- コンテキストウィンドウは全モデルで128K
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
このDeepSeek-V3.1は、AIエージェントとしての能力にも磨きがかかっており、生成AI業界のトレンドを押さえたモデルとなっています。
なお、DeepSeek-V3.1について詳しく知りたい方は下記の記事も併せてご確認ください。

DeepSeek-V3.2-Exp
2025年9月に登場した「DeepSeek-V3.2-Exp」は、DeepSeek-V3.1の後継にあたる試験モデルです。こちらは、性能をそのままに低コストを実現する新技術「DeepSeek Sparse Attention(DSA)」を採用。下記のとおり、先代比でよりお得なモデルとなりました。
- 基本設計はDeepSeek-V3.1に準拠
- 長文入力時の性能向上と計算コストの削減を達成
- 日本語にも対応
- 「MITライセンス」採用で私的使用・商用利用・改変・配布が可能
なお、このDeepSeek-V3.2-Expについては、API版での利用料金が先代の半額以下に抑えられています。
DeepSeek-OCR 2
2026年1月に登場した「DeepSeek-OCR 2」は、視覚・ドキュメント理解・OCR向けのVLM(Vision-Language Model:視覚言語モデル)です。
DeepEncoder V2により、従来の「左上→右下」の固定グリッド的な読み取りではなく、人間のような論理的な順序で画像をスキャンできる点が特徴となっていて、これにより、複雑なレイアウト(列の追従、ラベルと値の対応付け、表の一貫読解、テキスト+構造が混ざる画像など)でのOCR性能がアップするとされています。
なお、DeepSeekのWebアプリ / モバイルアプリについて詳しく知りたい方は下記の記事も併せてご確認ください。

DeepSeek「モデル地図」
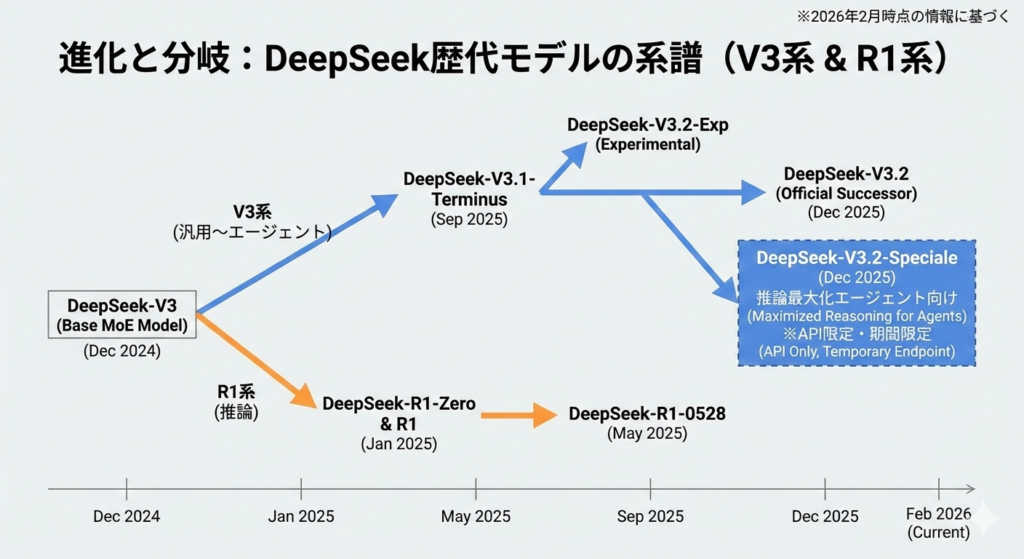
DeepSeekの歴代モデルを理解するうえで重要なのは、V3系(汎用〜エージェント) と R1系(推論) が、それぞれアップデートを重ねながら用途が分岐している点です。
たとえば、V3.2はV3.2-Expの後継として位置づけられ、V3.2-ExpはV3.1-Terminusを土台にした実験モデルとされています。
また、V3.2-Specialeは「推論を最大化したエージェント向け」として案内されており、2026年2月時点ではAPI限定で提供されること、さらに提供期間やエンドポイントが「暫定」とされているので、運用上は注意しておくポイントとなります。
DeepSeekモデル選定の早見表(目的別)
| 用途 | モデル |
|---|---|
| 日常の汎用(要約・文章・軽い推論) | V3.2(バランス型) |
| 重い推論(数学・論理・難問) | R1系(R1-0528を含む) |
| エージェント(推論+ツール利用前提の設計) | V3.2系(Speciale含む) |
| ローカルで軽量に回したい | Distill系(R1蒸留など)を含め、用途とライセンスで選択 |
よくある質問(FAQ)
こちらでは、DeepSeekに関するFAQを4つご紹介します。
DeepSeekの進化は止まらない!
当記事では、中国発のLLM「DeepSeek」シリーズについて、各モデルの概要をご紹介しました。
DeepSeekの各モデルについては、計算コスト削減と性能向上を両立する新技術が盛り込まれています。「ChatGPT超え」で話題を集めたDeepSeek-V3 / DeepSeek-R1も衝撃的でしたが、アップデートを繰り返し、DeepSeekのモデルは更なる進化を遂げています。今後もDeepSeekの動向からは目が離せません!

最後に
いかがだったでしょうか?
自社業務に生成AIを導入するなら、コストと性能の両立は欠かせません。DeepSeekのような高性能LLMのビジネス活用については、弊社・株式会社WEELにお任せください。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。