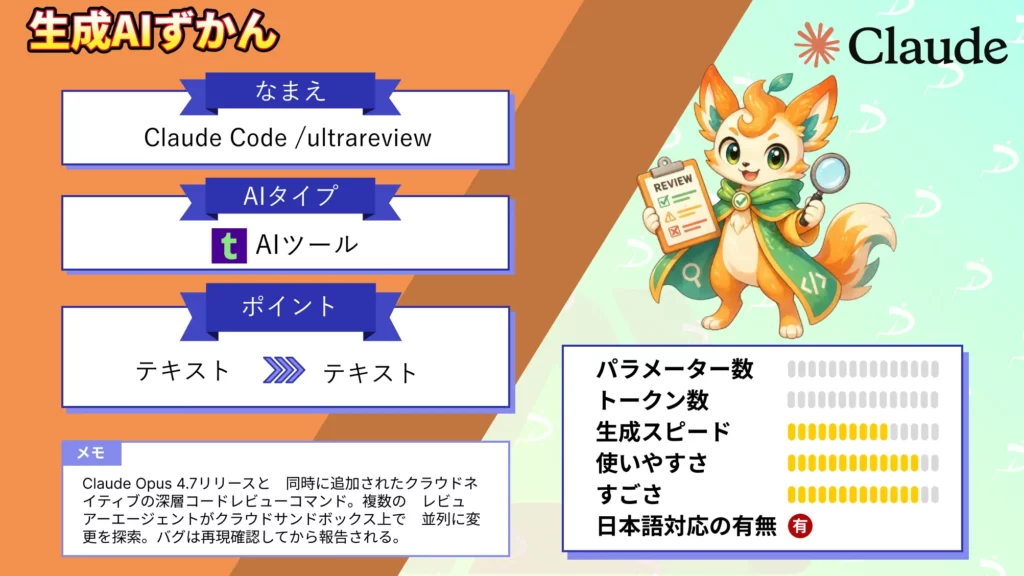
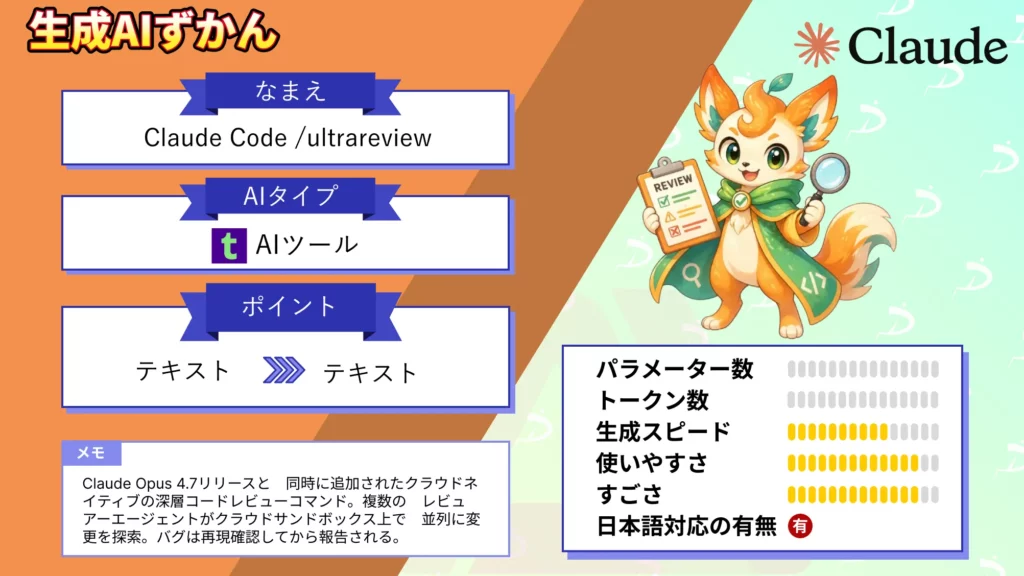
- Claude Code /ultrareviewは、Claude Opus 4.7リリースと同時に追加されたクラウドネイティブの深層コードレビューコマンド
- 複数のレビュアーエージェントがクラウドサンドボックス上で並列に変更を探索し、検出されたバグは独立した検証プロセスで再現確認してから報告される
- Pro・Maxプランのユーザーは2026年5月5日まで3回無料で試用可能
2026年4月17日、AnthropicはClaude Codeのアップデートにおいて、新コマンド「/ultrareview」をリリースしました!
Anthropicの公式ブログでは、同社のエンジニアひとりあたりのコード出力量が、この1年で200%も増加したと明かされています。コードを書く速度は飛躍的に上がったのに、レビューするキャパシティはそれに追いついていない状況が深刻化していたそうです。
/ultrareviewは、まさにこのボトルネックを解消するために生まれた機能です。Anthropicのクラウドインフラ上で複数のAIレビュアーエージェントを同時に起動し、変更差分を多角的に精査してくれます。見つかった問題は、独立した検証ステップを通過してから報告されるため、ノイズの少ない確度の高い指摘を得ることができます。
そこで本記事では、/ultrareviewの概要から仕組み、料金体系、具体的な使い方、活用シーンまで徹底的に解説していきます。ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
- Claude Code /ultrareviewとは?
- Claude Code /ultrareviewの仕組み
- Claude Code /ultrareviewの特徴
- Claude Code /ultrareviewの安全性・制約
- Claude Code /ultrareviewの料金
- Claude Code /ultrareviewのライセンス
- Claude Code /ultrareviewの使い方
- 【業界別】Claude Code /ultrareviewの活用シーン
- 【課題別】Claude Code /ultrareviewが解決できること
- Claude Code /ultrareviewを使ってみた
- よくある質問
- Claudeの歴代モデル一覧
- Claude Code /ultrareviewを試してみよう!
- 最後に
Claude Code /ultrareviewとは?

Claude Code /ultrareviewは、マージ前のコードレビューの精度と信頼性を飛躍的に引き上げるために設計された、クラウドベースの深層レビューコマンドです。
まず前提として、Claude Codeにはもともと「/review」というローカル実行型のレビューコマンドが存在しています。
/reviewは数秒〜数分で結果が返ってくる手軽さが魅力ですが、単一パスでの分析が中心です。一方の/ultrareviewは、Anthropicのクラウドサンドボックス上で複数のレビュアーエージェントをフリートとして起動し、変更差分を並列に探索するというまったく異なるアプローチを採用しています。
公式ドキュメントでは、/ultrareviewの優位性として3つのポイントが挙げられています。

1つ目は「Higher signal(高いシグナル)」で、報告される指摘はすべて独立した再現・検証を経たものであり、スタイル提案ではなく実際のバグに焦点を当てている点です。
2つ目は「Broader coverage(幅広いカバレッジ)」で、多数のエージェントが並行して変更を探索するため、シングルパスでは見逃されがちな問題が浮かび上がる点です。
3つ目は「No local resource use(ローカルリソース不使用)」で、レビュー全体がリモートサンドボックスで実行されるため、開発者のターミナルは別の作業に使えるという点です。
Claude Codeについて、詳しく知りたい方は以下の記事も参考にしてみてください。

Claude Code /ultrareviewの仕組み
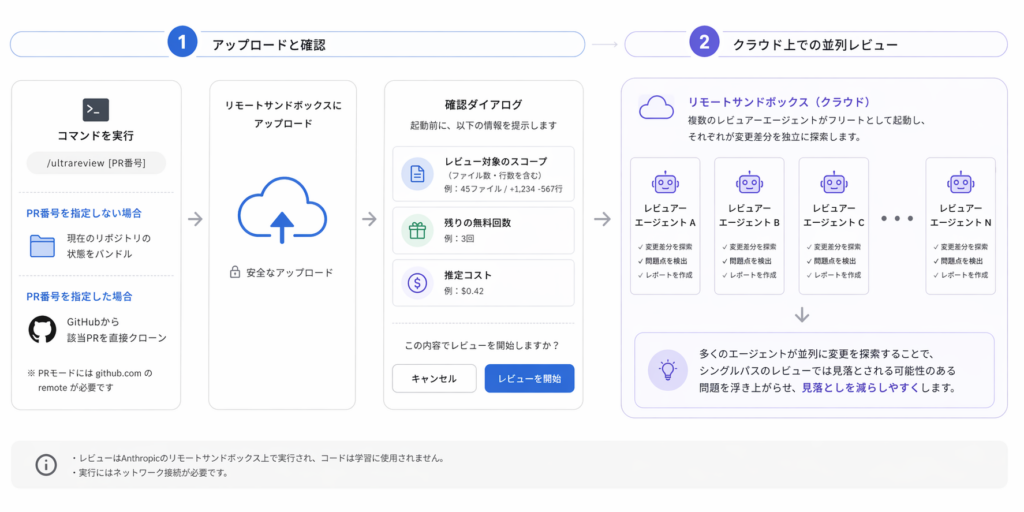
/ultrareviewの動作は、コマンド実行からfindingsの報告まで、いくつかの段階を経て進行します。
コマンドを実行すると、まずClaude Codeがリポジトリの現在の状態をバンドルし、Anthropicのリモートサンドボックスにアップロードします。PR番号を指定した場合は、GitHubから直接PRをクローンする方式に切り替わります。この段階で確認ダイアログが表示され、レビュー対象のスコープ(ファイル数や行数を含む)、残りの無料回数、推定コストが提示されます。
確認後、クラウド上で複数のレビュアーエージェントがフリートとして起動し、それぞれが変更差分を独立に探索します。


Claude Code /ultrareviewの特徴
/ultrareviewが従来のコードレビュー手段と決定的に異なる特徴をもう少し掘り下げていきましょう。
findingsの検証プロセス
まず最も重要なのは、findingsの検証プロセスです。
ローカルの/reviewコマンドをはじめ、多くの自動レビューツールでは「バグかもしれない」「検討すべき」といった確度の低い提案が混在しやすい側面があります。/ultrareviewでは、エージェントが検出した問題を別のプロセスで独立に再現・検証し、確認できたものだけを報告します。
マルチエージェントの並列探索によるカバレッジの広さ
次に、マルチエージェントの並列探索によるカバレッジの広さです。
人間のレビュアーであれAIであれ、シングルパスのレビューではどうしても注意が特定の箇所に偏ります。/ultrareviewは複数のエージェントが同時に異なる角度からコードを精査するため、単一パスでは見落とされる問題を拾い上げる設計になっています。
ローカルリソースを一切消費しない
さらに、ローカルリソースを一切消費しない点も見逃せません。
レビュー処理はすべてAnthropicのリモートサンドボックス上で実行されます。私たち開発者は自身のターミナルを自由に使い続けられるほか、ターミナルを完全に閉じてしまっても処理は継続されます。進行状況の確認や停止は/tasksコマンドで管理できます。
Claude Code /ultrareviewの安全性・制約
/ultrareviewを利用する際には、いくつかの制約事項を把握しておくことが重要です。
認証面ではClaude.aiアカウントでのログインが必須です。APIキーのみで認証している場合は、Claude Code内で/loginコマンドを実行してClaude.aiアカウントに再認証する必要があります。また、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry経由でClaude Codeを利用している場合は/ultrareviewを利用できません。
データフローの観点では、ブランチモードの場合、リポジトリの現在の状態がAnthropicのリモートサンドボックスにアップロードされます。社内の機密コードを含むリポジトリで利用する際は、このデータフローが組織のセキュリティポリシーに適合するかを事前に確認しておくことが推奨されます。
Claude Code /ultrareviewの料金
/ultrareviewはプレミアム機能として位置づけられており、通常のプラン利用枠(included usage)ではなく「extra usage(追加利用)」として課金される仕組みです。
| プラン | 無料回数 | 無料回数消費後 | 備考 |
|---|---|---|---|
| Pro(月額$20) | 3回(ワンタイム) | extra usageとして課金 | 無料回数はアカウントごとの1回限り。更新なし。2026年5月5日に期限切れ |
| Max(月額$100〜) | 3回(ワンタイム) | extra usageとして課金 | 同上 |
| Team | なし | extra usageとして課金 | 組織でextra usageの有効化が必要 |
| Enterprise | なし | extra usageとして課金 | 同上 |
公式ドキュメントによると、1回あたりのレビュー費用は変更のサイズに応じておおむね5ドルから20ドルの範囲が目安とされています。レビュー起動前の確認ダイアログに推定コストが表示されるため、実行前に金額感を確認できます。
特に重要なポイントは、Pro・Maxプランの無料3回はアカウントごとのワンタイム付与であり、月ごとにリセットされるものではないということです。さらに、この無料回数には2026年5月5日という有効期限が設定されています。
Claude Code /ultrareviewのライセンス
/ultrareviewはClaude Codeの一機能として提供されているため、利用条件はAnthropicの各種利用規約に準拠します。
| 項目 | 可否 | 備考 |
|---|---|---|
| 商用利用 |  | |
| CI/CDへの組み込み |  | /ultrareview自体はCLI手動実行のコマンド。CI/CDにはGitHub Actionsベースの別機能(Code Review)が存在 |
| 第三者への再配布 |  | /ultrareview機能そのものの再配布・再販は利用規約上不可 |
| 特許利用 | − | Anthropicの利用規約に個別の特許ライセンス条項は明示されていない |
| 私的利用 | |
/ultrareviewは独立したOSSではなく、Claude Codeのプロプライエタリ機能として提供されています。そのため、コマンドのソースコードを改変・再配布するといった利用はできません。
Claude Code /ultrareviewの使い方
ここからは、Claude Code /ultrareviewを実際に使い始めるまでの手順を解説します。
前提条件を確認
Claude Code /ultrareviewを利用するには、以下の3つの条件を満たす必要があります。
- Claude Codeのバージョンがv2.1.86以降であること
- Claude.aiアカウント(Pro・Max・Team・Enterpriseのいずれか)でログイン済みであること
- gitリポジトリ内で作業していること
バージョンの確認は以下のコマンドで行えます。
claude --version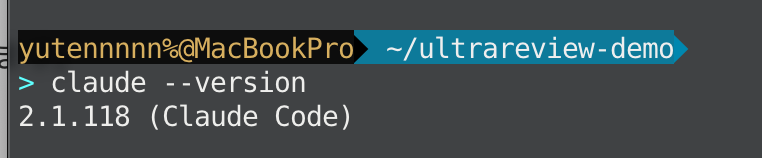
APIキーのみで認証している場合は、Claude Code内で以下のコマンドを実行してClaude.aiアカウントで再認証してください。
/loginブランチモードでレビューを実行
最もシンプルな使い方は、作業ブランチ上で引数なしのコマンドを実行する方法です。
/ultrareview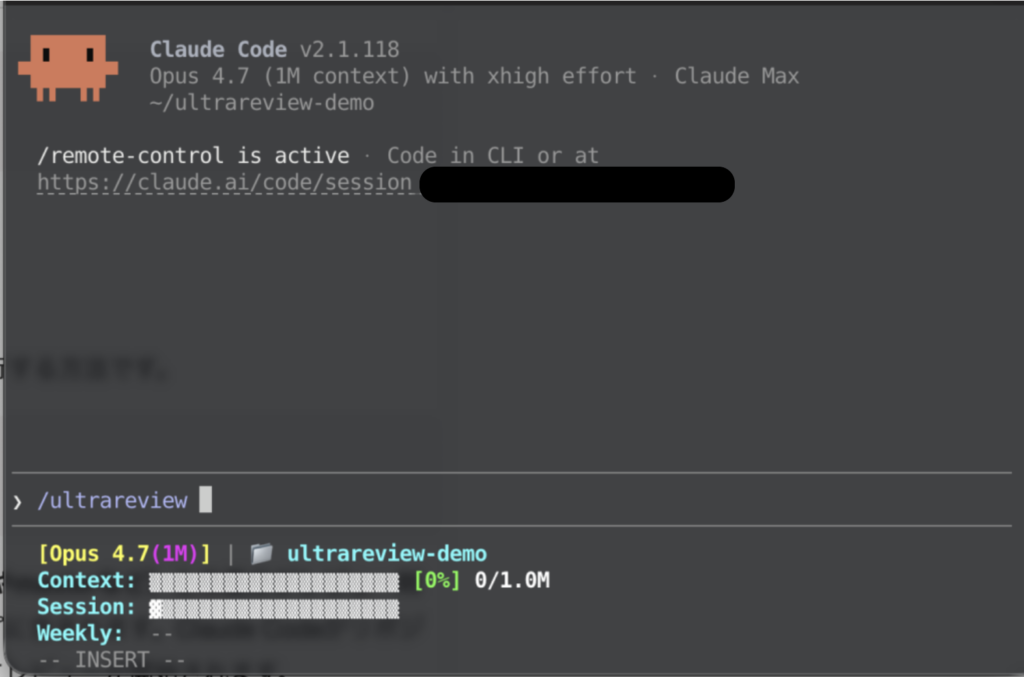
引数なしで実行すると、現在のブランチとデフォルトブランチ(mainやmasterなど)との差分がレビュー対象となります。未コミットの変更やステージング済みの変更もスコープに含まれます。Claude Codeがリポジトリの状態をバンドルし、リモートサンドボックスにアップロードしてレビューが開始されます。
PRモードでレビューを実行
GitHub上でプルリクエストを作成済みの場合は、PR番号を指定してレビューを実行できます。
/ultrareview 1234PRモードでは、ローカルのワーキングツリーをバンドルする代わりに、リモートサンドボックスがGitHubから直接PRをクローンします。リポジトリが大きすぎてバンドルできない場合は、ブランチをプッシュしてドラフトPRを開いたうえでPRモードを使用してください。PRモードの利用にはリポジトリにgithub.comのリモートが設定されている必要があります。
確認ダイアログで内容を確認し、承認
コマンド実行後、レビュー開始前に確認ダイアログが表示されます。ここにはレビュー対象のスコープ(ブランチレビュー時はファイル数・行数を含む)、残りの無料回数、推定コストが記載されています。
内容を確認して承認すると、レビューがバックグラウンドで開始されます。なお、/ultrareviewはユーザーが明示的に実行した場合にのみ動作し、Claude Codeが自動で開始することはありません。
レビューの進行状況を確認
レビューの実行中・完了後の状況は、/tasksコマンドで確認できます。
/tasksここから実行中のレビューの詳細ビューを開いたり、進行中のレビューを停止したりできます。停止した場合はクラウドセッションがアーカイブされ、部分的なfindingsは返されません。
【業界別】Claude Code /ultrareviewの活用シーン
Claude Code /ultrareviewは、マージ前の深いコードレビューを自動化する機能であるため、コードの品質がビジネスに直結するあらゆる業界で活用の余地があります。ここからは、特に相性の良いユースケースを業界別に紹介します。
フィンテック・金融業界
決済処理や口座管理など、一行のバグが金銭的な損失やコンプライアンス違反につながりかねない金融系システムでは、/ultrareviewの検証済みfindingsのみ報告という特性が大きな安心材料になります。
認証・認可ロジックの変更やトランザクション処理のリファクタリングなど、影響範囲の大きい変更に対して、マージ前の最終チェック手段として活用できるでしょう。
金融業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

SaaS・Webサービス開発
継続的にデプロイを行うSaaS企業では、日々大量のPRが発生します。すべてのPRに人力で深いレビューを行うのは現実的ではなく、特にAI生成コードの比率が高まっている昨今、自分が書いていないコードのレビューには盲点が生まれやすくなっています。
全PRに対しては通常の/reviewやCI上の自動チェックを適用しつつ、重要度の高いPRや、APIの認証フロー変更やデータベースマイグレーションに絞って、/ultrareviewをかけるという運用が費用対効果の面で有効といえるでしょう。
生成AIを搭載したSaaSについて、詳しく知りたい方は以下の記事も参考にしてみてください。

研究・アカデミア
研究プロジェクトで開発されるコードは、実験の再現性に直結するかと思います。
そこで、データパイプラインの本番移行前や論文submission前に、Claude Code /ultrareviewでチェックしておくことで、意図しないデータ変換ミスやロジックバグの混入を未然に防ぐことが期待できます。
教育業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Claude Code /ultrareviewが解決できること
Claude Code /ultrareviewは、開発チームが日常的に直面するさまざまな課題に対応できるよう設計されています。ここからは具体的な課題ごとに、/ultrareviewがどのように役立つかを整理します。
レビュー待ちによるマージの遅延を解消
コードレビューの待ち時間は、多くのチームにとって開発速度のボトルネックです。Anthropic社も公式ブログで、AI支援コーディングの普及でコード出力量は増えたがレビューのキャパシティが追いついていないという不均衡を指摘しています。
/ultrareviewは、人間のレビュアーの代替ではありませんが、まずマルチエージェントの深いチェックを通しておき、人間のレビュアーは高レベルの設計判断や文脈理解に集中するといったワークフローを構築することで、レビューの質と速度の両立を支援してくれます。
AI生成コードの品質担保
Claude CodeやGitHub Copilotなどで生成されたコードは、一見正しく動作するものの、微妙なロジックバグやセキュリティリスクを内包していることがあります。
自分で書いていないコードほど、レビューの精度が下がりやすいという人間の認知的な傾向を、マルチエージェントによる多角的な検証で補完できる点は/ultrareviewの大きな強みです。
セキュリティ脆弱性の見落とし防止
認証フロー、入力バリデーション、アクセス制御など、セキュリティに関わるコードの変更は一箇所のミスが重大なインシデントにつながります。
そこで、Claude Code /ultrareviewのエージェントは、複数の視点からコードを探索してくれるため、シングルパスのレビューでは気づきにくい脆弱性の検出が期待できます。
Claude Code /ultrareviewを使ってみた
それでは実際に、/ultrareviewと/reviewの比較検証をしていきましょう。
今回は、意図的にセキュリティ上のアンチパターンを仕込んだ約30行のPythonモジュールを用意し、ローカルの/reviewと/ultrareviewの両方で同じ変更差分をレビューしてもらうことで、検出精度の違いを比較しました。
検証用のファイルは ~/ultrareview-demo/auth.py に配置した、以下のようなシンプルな認証モジュールです。
認証モジュールはこちら
import hashlib
USERS = {
"alice": "5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8",
}
def hash_password(password: str) -> str:
return hashlib.sha256(password.encode()).hexdigest()
def verify_password(username: str, password: str) -> bool:
if username not in USERS:
return False
expected = USERS[username]
actual = hash_password(password)
return expected == actual
def login(username: str, password: str) -> str:
if verify_password(username, password):
return f"Welcome, {username}!"
return "Invalid credentials"1点目のアンチパターンは、verify_password内のハッシュ比較に==演算子を使っているので、文字列を先頭から順に比較するため、処理時間の微妙な差から正解のバイト列を推測される「タイミング攻撃」に対して脆弱になります。
2点目のアンチパターンは、パスワードをソルトなしのSHA-256で直接ハッシュしている点で、SHA-256は高速に計算できる汎用ハッシュ関数であり、レインボーテーブルやブルートフォースに弱いため、パスワード保存にはbcrypt・scrypt・argon2のようなパスワード専用アルゴリズムを使うのが最新のベストプラクティスとされています。
/reviewの出力結果はこちら
Overview
A tiny auth module: SHA-256 hashes a password, looks up the user in an in-memory dict, and returns a greeting on match. Works as a demo; not safe for any real use.
Security Issues (critical)
- Unsalted SHA-256 is broken for password storage (auth.py:9-10). SHA-256 is a fast general-purpose hash — a commodity GPU tries billions/sec. The stored hash 5e88…42d8 is literally sha256("password") and appears in every rainbow table. Use a password KDF: bcrypt, argon2-cffi (Argon2id preferred), or stdlib hashlib.scrypt. Each stores a per-user salt + cost factor inside the hash string.
- Timing-attack on comparison (auth.py:18). expected == actual short-circuits on the first mismatched byte. Use hmac.compare_digest(expected, actual). (Moot once you switch to bcrypt/argon2, whose verify functions are constant-time.)
- Username enumeration via early return (auth.py:14-15). Returning immediately when the user is missing makes the "unknown user" path measurably faster than the "known user, wrong password" path. Always run a dummy hash verification when the user doesn't exist.
- Hardcoded credential in source (auth.py:4-6). Even as a demo, committing alice / password encourages copy-paste into real code. At minimum add a comment making the demo-only intent explicit, or load from env/config.
Code Quality
- login returning a str that callers must string-compare is fragile (auth.py:21-24). A bool (or raising on failure) is clearer; the greeting is a presentation concern, not auth.
- login leaks which half failed only via a generic message — good. Keep that behavior when you refactor.
- No logging, no rate limiting, no lockout — fine to call out as out-of-scope for a demo, but worth noting.
Tests
None. For a real module I'd want cases for: valid login, wrong password, unknown user, empty inputs, and a timing-parity smoke test (unknown-user path ≈ wrong-password path).
Suggested Minimal Fix
import hmac, os
from argon2 import PasswordHasher
from argon2.exceptions import VerifyMismatchError
_ph = PasswordHasher()
# Stored values are argon2id hashes, not raw sha256
USERS = {"alice": os.environ.get("ALICE_HASH", "")}
_DUMMY_HASH = _ph.hash("dummy") # constant-time fallback for unknown users
def verify_password(username: str, password: str) -> bool:
stored = USERS.get(username, _DUMMY_HASH)
try:
_ph.verify(stored, password)
return username in USERS
except VerifyMismatchError:
return False
Risk Summary
┌────────────────────────────────┬───────────────────────────┐
│ Issue │ Severity │
├────────────────────────────────┼───────────────────────────┤
│ Unsalted SHA-256 for passwords │ 🔴 Critical │
├────────────────────────────────┼───────────────────────────┤
│ Timing-unsafe comparison │ 🟠 High │
├────────────────────────────────┼───────────────────────────┤
│ Username enumeration │ 🟡 Medium │
├────────────────────────────────┼───────────────────────────┤
│ Hardcoded demo creds │ 🟡 Low (demo) / 🔴 (prod) │
└────────────────────────────────┴───────────────────────────┘
If you meant to review a GitHub PR, give me the PR number (e.g. /review 42) and I'll pull it via gh.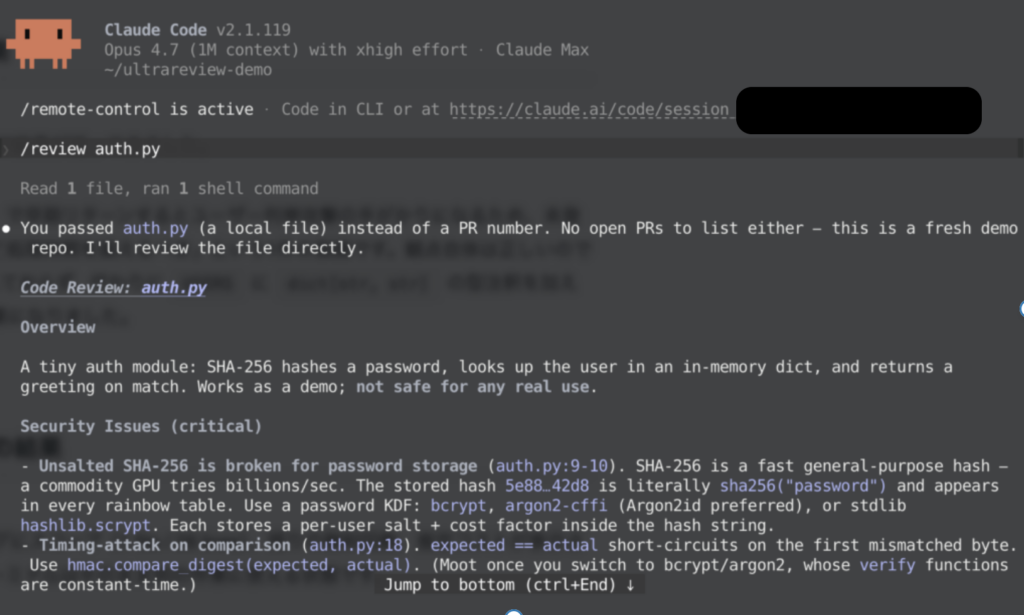
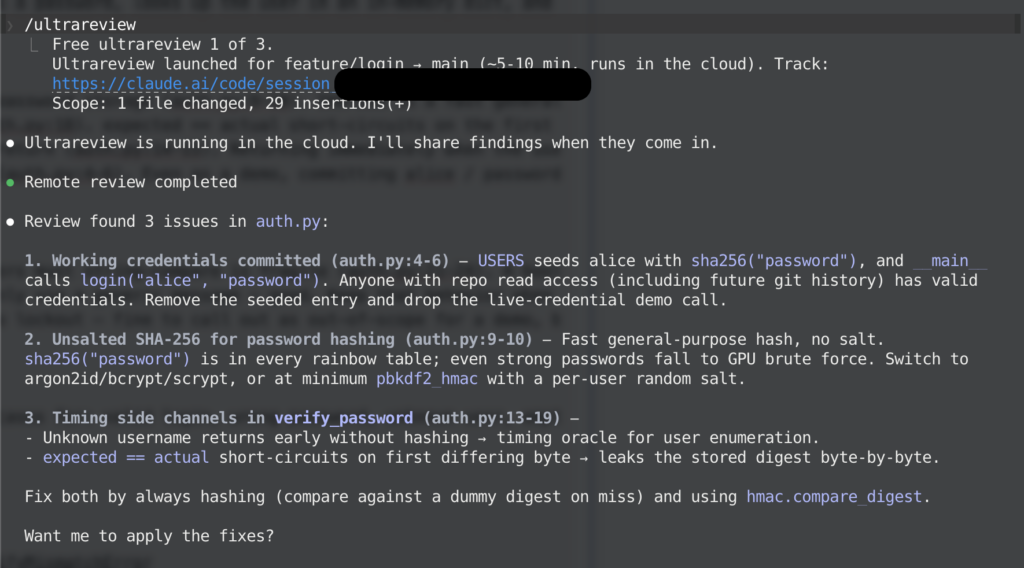
/ultrareviewの出力結果はこちら
Ultrareview is running in the cloud. I'll share findings when they come in.
⏺ Remote review completed
Review found 3 issues in auth.py:
1. Working credentials committed (auth.py:4-6) — USERS seeds alice with sha256("password"), and __main__ calls login("alice", "password"). Anyone with repo read access (including future git history) has valid credentials. Remove the seeded entry and drop the live-credential demo call.
2. Unsalted SHA-256 for password hashing (auth.py:9-10) — Fast general-purpose hash, no salt. sha256("password") is in every rainbow table; even strong passwords fall to GPU brute force. Switch to argon2id/bcrypt/scrypt, or at minimum pbkdf2_hmac with a per-user random salt.
3. Timing side channels in verify_password (auth.py:13-19) —
- Unknown username returns early without hashing → timing oracle for user enumeration.
- expected == actual short-circuits on first differing byte → leaks the stored digest byte-by-byte.
Fix both by always hashing (compare against a dummy digest on miss) and using hmac.compare_digest.
Want me to apply the fixes?
今回の検証においては、/reviewと/ultrareviewは、検出力の差というよりレビューの性質の違いが確認できました。
/reviewは、セキュリティ問題からコード設計、テスト方針まで幅広く拾い上げてくれる網羅型のレビュアーで、開発の初期段階で設計のフィードバックが欲しいときや、コード全体の改善ポイントを洗い出したいときには頼りになりそうです。
一方の/ultrareviewは、検証済みの実リスクだけに絞り込む精度型のレビュアーで、スタイル提案やベストプラクティスの改善案は除外され、このままマージしたら本当に困るものだけが報告されました。さらに、関連する問題を根本原因で統合してくれるので、対処すべきことがぱっと見るだけで明確になります。
よくある質問
最後に、Claude Code /ultrareviewについて、多くの方が気になるであろう質問とその回答をご紹介します。
Claudeの歴代モデル一覧
 Claude 1 Anthropicが初めて公開した対話型AI。長いコンテキスト(文脈)を理解できる能力が特徴。 |  Claude 2 推論能力、コーディング能力、安全性が強化されたモデル。 Claude 2の解説はこちら | 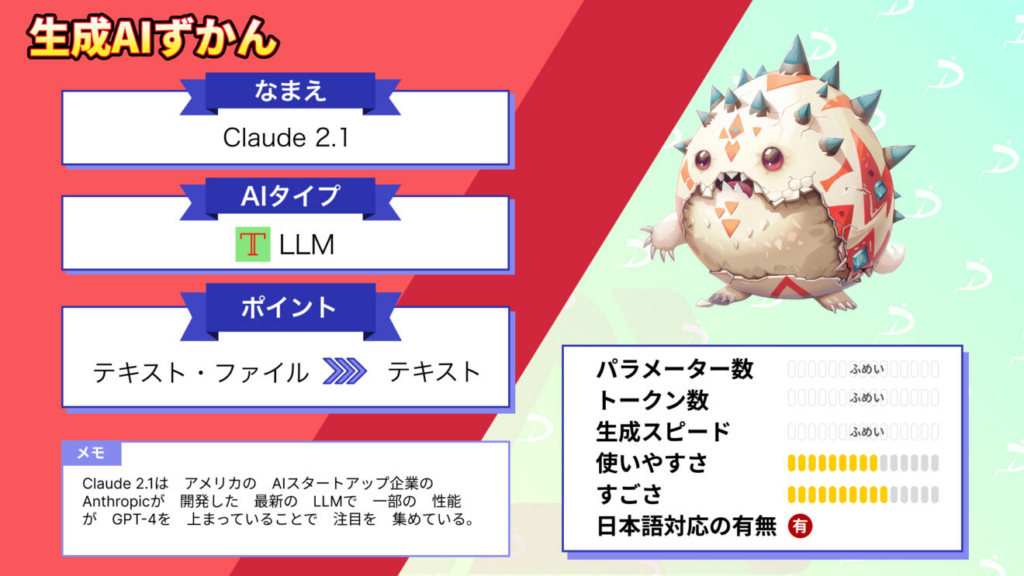 Claude 2.1 2.1ではさらに長い情報処理(約15万トークン)に対応。 Claude 2.1の解説はこちら |
 Claude 3 Claude 3 ファミリー ・Opus (オパス): 最高性能の最上位モデル。複雑な推論に強い。 ・Sonnet (ソネット): 速度と知能のバランスが取れたモデル。初期の無料版で採用。 ・Haiku (ハイク): 最速・最軽量のモデル。応答速度に特化。 Claude 3の解説はこちら |  Claude 3.5 Sonnet Claude 3 Opusをも上回る速度と性能を低コストで実現したモデル。Artifacts機能(生成したコードのプレビュー機能)が追加。 Claude 3.5 Sonnetの解説はこちら |  Claude 3.5 Haiku 軽量モデルのHaikuも3.5シリーズへアップデート Claude 3.5 Haikuの解説はこちら |
 Claude 3.7 Sonnet 従来モデルに比べて安全性と性能を追求したハイブリッド型モデル。 Claude 3.7 Sonnetの解説はこちら |  Claude Sonnet 4.5 プログラミングや自律的エージェントの支援に特化したモデル Claude Sonnet 4.5の解説はこちら |  Claude Haiku 4.5 軽量で動作が速いモデル Claude Haiku 4.5の解説はこちら |
 Claude Opus 4.5 コーディングから事務作業まで幅広い実務で高い処理性能を発揮するモデル Claude Opus 4.5の解説はこちら |  Claude Opus 4.6 Opusファミリーで初めて100万トークンのコンテキストウィンドウ(ベータ版)に対応 Claude Opus 4.6の解説はこちら |  Claude Opus 4.7 ソフトウェアエンジニアリングやエージェント領域で大幅な性能向上。複雑で長時間にわたるタスクを一貫性を保ったまま遂行可能。 Claude Opus 4.7の解説はこちら |
Claudeの基本を詳しく知りたい方はこちらをチェック!

Claude Code /ultrareviewを試してみよう!
本記事では、2026年4月17日にClaude Codeのアップデートとしてリリースされた新コマンド「/ultrareview」について、公式情報を中心に概要から仕組み、料金、使い方、活用シーンまでをご紹介しました。
/ultrareviewの最大の価値は、複数のAIエージェントがクラウド上で並列にコードを探索し、検出された問題を独立した検証プロセスで再現確認してから報告するという確度の高い深層レビューを実現している点です。
従来のlintツールやシングルパスのレビューでは拾いきれなかったロジックバグやセキュリティ脆弱性を、マージ前に発見できる可能性が大きく広がりました。
Pro・Maxプランでは2026年5月5日まで3回の無料実行が利用可能ですので、まずはご自身のプロジェクトで最も影響の大きい変更に対して試してみることをおすすめします。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。