

- Gemini 3.1 Flash Liveは、Googleが公開したリアルタイムの音声・映像対話に特化した音声生成モデル
- 従来のGemini 2.5 Flash Native Audioと比較し、レイテンシが大幅に低減
- 会話の追跡能力も2倍に向上
2026年3月27日、Googleは音声AIモデルの最新版「Gemini 3.1 Flash Live」を発表しました!
Gemini's audio and voice capabilities just got an upgrade with Gemini 3.1 Flash Live.
— Google (@Google) March 26, 2026
Our new high-quality audio and voice model comes with:Faster response times
More helpful, natural dialogue
2x longer conversation memory in Gemini Live
Multilingual support for… pic.twitter.com/8o6VO3rND0
Google CEOのSundar Pichai氏が自ら「最高品質のオーディオ・音声モデル」と紹介したこのモデルは、リアルタイムの音声・映像対話に特化した設計となっており、AI業界全体から大きな注目を集めています。
従来のGemini 2.5 Flash Native Audioと比較してレイテンシが大幅に低減され、会話中のぎこちない間が解消されたほか、90以上の言語をサポートするなど、グローバルな展開を見据えたモデルとなっています。
そこで本記事では、Gemini 3.1 Flash Liveの概要や仕組み、料金体系、具体的な使い方、活用シーンまでを徹底的に解説します。ぜひ、最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
- Gemini 3.1 Flash Liveとは?
- Gemini 3.1 Flash Liveの仕組み
- Gemini 3.1 Flash Liveの特徴
- Gemini 3.1 Flash Liveの安全性・制約
- Gemini 3.1 Flash Liveの料金
- Gemini 3.1 Flash Liveのライセンス
- Gemini 3.1 Flash Liveの使い方
- 【業界別】Gemini 3.1 Flash Liveの活用シーン
- 【課題別】Gemini 3.1 Flash Liveが解決できること
- Gemini 3.1 Flash Liveを使ってみた
- よくある質問
- Gemini 3.1 Flash Liveで仕事の常識が変わる!
- 最後に
Gemini 3.1 Flash Liveとは?

Gemini 3.1 Flash Liveは、Googleが開発したリアルタイム対話向けの低レイテンシ音声AIモデルです。モデルIDは「gemini-3.1-flash-live-preview」で、Google AI StudioのLive APIを通じてプレビュー版が公開されています。
このモデルの最大の特徴は、音声から音声への直接的な処理(Audio-to-Audio) に最適化されている点です。テキストを介さずに音声入力をそのまま理解し、自然な音声で応答を返すことができます。入力としてはテキスト、画像、音声、動画のマルチモーダルに対応していて、出力はテキストと音声の両方をサポートしています。

モデルカードによると、Gemini 3.1 Flash LiveのアーキテクチャはGemini 3 Proをベースに、ネイティブオーディオ機能を追加した構成です。つまり、Gemini 3 Proが持つ高い推論能力をキープしながら、リアルタイムの音声ストリーム処理に特化したチューニングが施されています。
コンテキストウィンドウは、入力が最大128Kトークン、出力が最大64Kトークンとなっています。従来モデルから会話の追跡能力が2倍に向上しており、長時間の会話でもコンテキストを見失うことなく、一貫性のある応答を維持できます。
なお、Googleの音声生成AI「Lyria 3・Lyria 3 Pro」について詳しく知りたい方は、以下の記事も参考にしてみてください。

Gemini 3.1 Flash Liveの仕組み
Gemini 3.1 Flash Liveの動作基盤についても整理します。このモデルがどのようにリアルタイムの対話を実現しているのかを理解しておきましょう。
通信プロトコルとセッション管理
Gemini 3.1 Flash LiveのLive APIは、ステートフルなWebSocket接続(WSS) を使用しています。HTTPベースのリクエスト・レスポンス方式ではなく、双方向の常時接続を維持することで、リアルタイムの音声・映像ストリーミングを実現しています。
接続方式は2種類あります。1つ目は、バックエンドサーバーがWebSocketでLive APIに接続するサーバー間接続(Server-to-Server)、2つ目はフロントエンドのコードがLive APIに直接接続するクライアント・サーバー間接続(Client-to-Server) です。後者は音声・映像のストリーミングにおいて一般的にパフォーマンスが優れています。
入出力の処理フロー
音声入力はRAW 16ビットPCM(16kHz、リトルエンディアン)形式で受け付けられ、音声出力はRAW 16ビットPCM(24kHz、リトルエンディアン)形式で返されます。画像入力はJPEG形式で1FPS以下、テキスト入力も併用可能となっています。
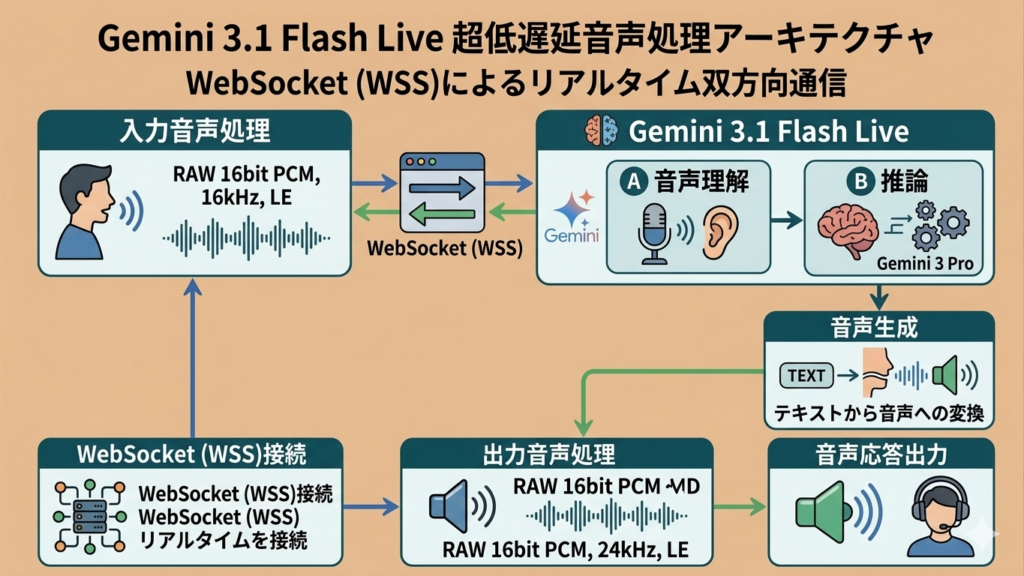
Thinkingモード
Gemini 3.1 Flash Liveには、推論の深さを制御するthinkingLevelパラメータが用意されており、minimal(デフォルト)、low、medium、highの4段階で設定できます。
タスクの複雑さに応じてThinkingの深さを調整することで、レイテンシと推論品質のバランスを取ることが可能です。


Gemini 3.1 Flash Liveの特徴
ここからは、Gemini 3.1 Flash Liveが従来モデルや競合と比較してどのような強みを持っているのかを、ベンチマークスコアも交えながらご紹介します。
ベンチマーク性能
Google DeepMindのモデルカードによると、主要なベンチマークでのスコアは以下の通りです。
ComplexFuncBench Audioというマルチステップの関数呼び出しをさまざまな制約下で評価するベンチマークで、90.8%とトップスコアを記録しています。リアルタイム会話中にツールを正確に呼び出す能力の高さが分かります。
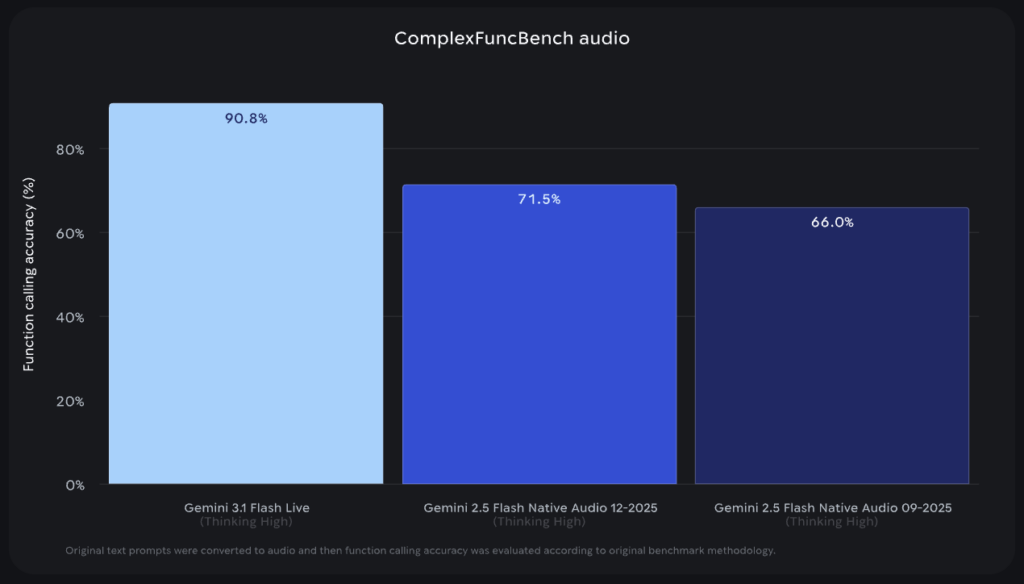
他にも、Scale AIが開発した、ユーザーの言いよどみや背景騒音(テレビの音、交通騒音など)がある環境下での音声理解力を評価するベンチマークであるAudio MultiChallengeで36.1%と、GPT-Realtime 1.5の34.7%を上回っています。
騒音環境への強さ
Gemini 3.1 Flash Liveは、音の高低やペースといった音響的なニュアンスの認識精度が従来の2.5 Flash Native Audioから大幅に向上しているため、交通騒音やテレビの音声が流れる環境でも、関連する発話と環境音を的確に聞き分けることができます。
Google Japan公式でも「不自然な間を排除し、思考の速さに並走する応答を実現」と紹介されています。
Gemini Live 3.1 新登場
— Google Japan (@googlejapan) March 26, 2026最新の音声モデル Gemini 3.1 Flash Live を搭載したことで、スピードと知能、日本語体験が劇的に進化。
・レイテンシを大幅に削減:不自然な「間」を排除し、思考の速さに並走する応答を実現。… pic.twitter.com/nEZT3LFveE
感情認識と応答の適応
ユーザーの声のトーンから苛立ちや困惑といった感情を読み取り、応答のスタイルを動的に調整するアフェクティブダイアログ(感情対応対話) 機能を備えています。
回答の長さやトーンをその場の状況に合わせて変化させるため、より人間らしい対話体験が実現されています。
Gemini 3.1 Flash Liveの安全性・制約
Gemini 3.1 Flash Liveの安全性と、利用上の制約についても確認していきましょう。
モデルカードによると、開発過程では自動評価と人間による評価の両方が、モデルの学習期間中および完了後に継続的に実施されているそうです。安全性に関しては、児童搾取コンテンツ、ヘイトスピーチ、危険なコンテンツ、ハラスメント、露骨なコンテンツ、医療上の誤情報の6つのコアポリシーが適用されています。
Gemini 3.1 Flash Liveの料金
Gemini 3.1 Flash Liveは、Google AI StudioのLive APIを通じて利用できます。
無料枠と有料プランの両方が用意されていて、開発段階から本番運用まで段階的にスケールアップすることが可能です。無料枠では、すべての入出力トークンが無料で利用でき、プロトタイプ開発や検証用途に適しています。
| 項目 | 無料枠 | 有料プラン(100万トークンあたり) |
|---|---|---|
| テキスト入力 | 無料 | $0.75 |
| 音声入力 | 無料 | $3.00($0.005/分) |
| 画像・動画入力 | 無料 | $1.00($0.002/分) |
| テキスト出力 | 無料 | $4.50 |
| 音声出力 | 無料 | $12.00($0.018/分) |
| Google検索連携 | 対応(月5,000プロンプトまで) | $14/1,000検索クエリ |
Gemini 3.1 Flash Liveのライセンス
Gemini 3.1 Flash Liveは、オープンソースモデルではなく、Googleが提供するクローズドなAPI型サービスです。
利用に際しては、Google APIs利用規約とGemini API追加利用規約の両方に同意する必要があります。
| 項目 | 可否 | 備考 |
|---|---|---|
| 商用利用 |  | |
| 出力の改変 | | |
| 再配布 |  | 出力コンテンツの再配布は可能だが、モデル自体の再配布は不可 |
| 特許利用 | – | Googleの知的財産権に関する個別のライセンスは付与されていない |
| 私的利用 | |
なお、Vertex AI経由で利用する場合はGoogle Cloud Platform利用規約が適用され、本番環境や商用目的での利用、生成出力の第三者への開示が認められています。
Gemini 3.1 Flash Liveの使い方
ここからは、Gemini 3.1 Flash Liveを実際に使うための手順をご紹介します。大きく分けて、Google AI Studioでの対話的な利用と、API経由での利用の2つの方法があります。
Google AI Studioで音声対話
1番お手軽にGemini 3.1 Flash Liveを体験できる方法です。コーディング不要で、ブラウザからすぐにリアルタイム音声対話を開始できます。
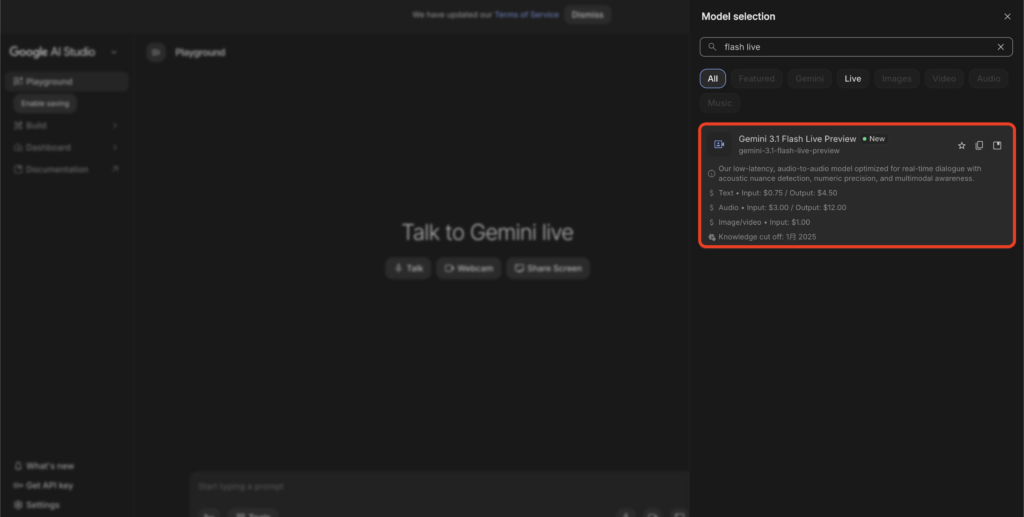
モデルを選択する
モデル選択ドロップダウンから「Gemini 3.1 Flash Live Preview」を選びます。
音声対話を開始する
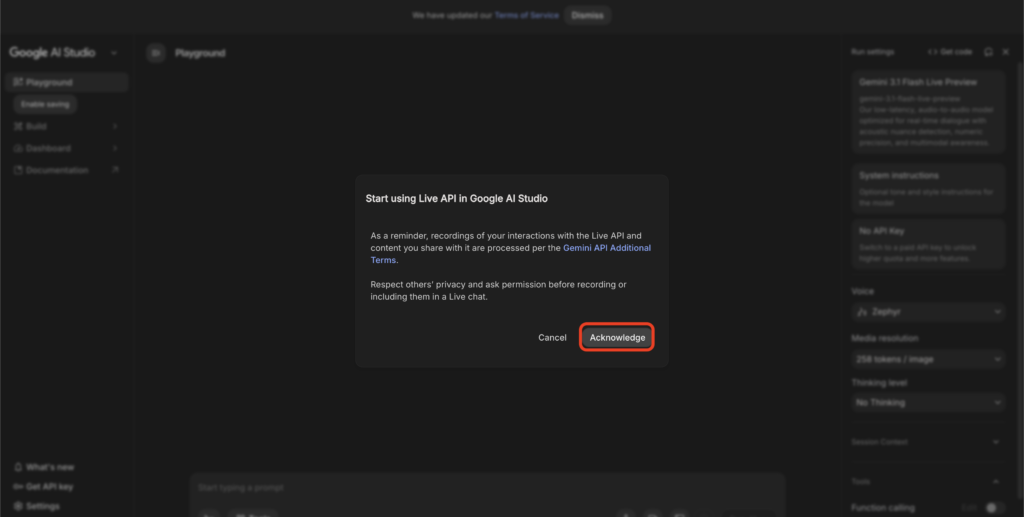
マイクのアイコンをクリックして音声入力を開始します。Liveモードのスタート確認およびブラウザからマイクへのアクセス許可を求められるので、許可してください。
話しかけると、モデルがリアルタイムで音声応答を返します。
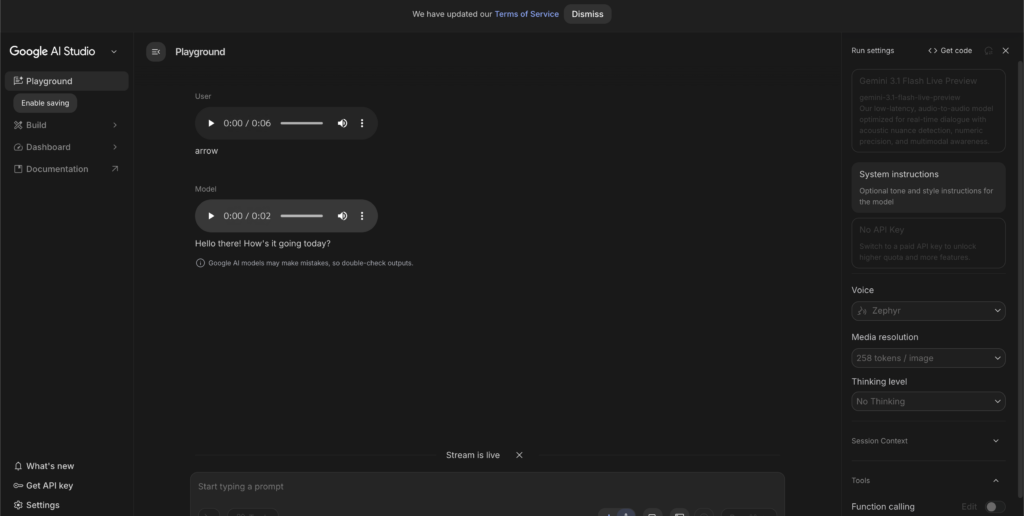
設定を調整する(任意)
左側のパネルでThinking Levelやシステムインストラクションを設定できます。複雑なタスクを依頼する場合はThinking Levelをhighに上げると、より深い推論が行われます。
Python(GenAI SDK)でLive APIに接続する
バックエンドサーバーからLive APIに接続する方法です。音声エージェントやカスタムアプリケーションの開発に適しています。
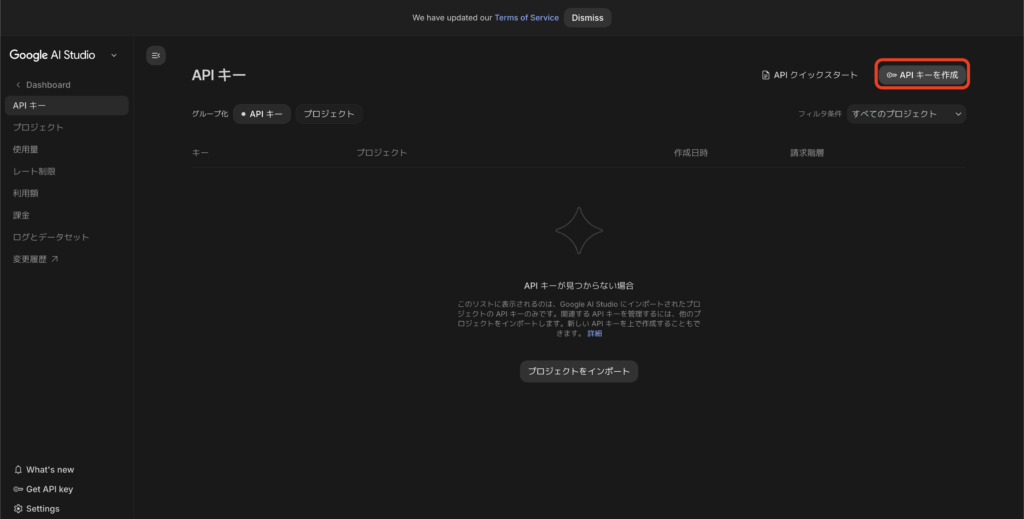
GenAI SDKをインストールする
pip install google-genaiLive APIに接続してリアルタイム対話を開始する
以下はPythonでの基本的な接続例です。
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
# Live APIセッションの設定
config = {
"response_modalities": ["AUDIO"],
"thinking_config": {"thinking_level": "minimal"},
}
# WebSocketセッションを開始
async with client.aio.live.connect(
model="gemini-3.1-flash-live-preview",
config=config,
) as session:
# テキストメッセージを送信
await session.send_client_content(
turns={"role": "user", "parts": [{"text": "こんにちは、今日の天気を教えて"}]}
)
# レスポンスを受信
async for response in session.receive():
if response.text:
print(response.text)セキュリティ設定(本番環境向け)
本番環境では、標準のAPIキーではなくエフェメラルトークンの利用が推奨されています。クライアント・サーバー間接続でAPIキーがフロントエンドに露出するリスクを軽減できます。
【業界別】Gemini 3.1 Flash Liveの活用シーン
Gemini 3.1 Flash Liveのリアルタイム音声対話機能は、さまざまな業界で活用が見込まれます。こちらでは、具体的な業界ごとの導入イメージを紹介します。
カスタマーサービス・コールセンター
Gemini 3.1 Flash Liveの低レイテンシ音声対話と感情認識機能は、コールセンターの自動化に最適です。
ComplexFuncBenchで90.8%のスコアを記録していることからも分かる通り、リアルタイム会話中に予約システムやCRMなどの外部ツールを正確に呼び出せるため、顧客の問い合わせに対して情報検索から手続き処理までをワンストップで対応できます。実際に、VerizonやThe Home Depotがすでにカスタマーインタラクションの改善に向けたテストを行っているそうです。
コールセンターにおける生成AI導入について、詳しく知りたい方は以下の記事も参考にしてみてください。

教育・語学学習
90以上の言語をサポートするマルチリンガル対応と、ピッチやペースといった音響ニュアンスの認識能力は、語学学習アシスタントとしての活用に向いています。学習者の発音やイントネーションに対してリアルタイムでフィードバックを返したり、会話練習の相手として自然なやり取りを行ったりすることが可能です。
教育業界における生成AIを活用した業務効率化について、詳しく知りたい方は以下の記事も参考にしてみてください。

ヘルスケア・医療相談
医療現場において、Gemini 3.1 Flash Liveは、音声ベースの問診アシスタントや、患者の症状ヒアリングの一次対応として活用できるかと思います。騒音環境でも正確に音声を聞き分ける能力は、病院の待合室や在宅医療の現場でも安定した動作を期待できる要素です。
医療現場における生成AI活用事例について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Gemini 3.1 Flash Liveが解決できること
ここからは、Gemini 3.1 Flash Liveが特に強みを発揮してくれる課題についても整理していきましょう。
リアルタイム対話でのレイテンシを解消
従来の音声AIでは、ユーザーが話し終えてから応答が返るまでに数秒の遅延が生じることがありました。
それに対して、Gemini 3.1 Flash Liveは、2.5 Flash Native Audioと比較してレイテンシを大幅に低減し、「不自然な間」を排除しています。ユーザーの思考のスピードに追従する応答速度を実現しており、ストレスのないリアルタイム対話が可能になるでしょう。
騒音環境での音声認識精度
交通騒音やテレビの音、周囲の会話など、雑音が多い環境での音声認識は多くのモデルにとって課題でした。
それに対してGemini 3.1 Flash Liveは、関連する発話と環境音を高精度に聞き分ける能力を備えており、Audio MultiChallengeベンチマークでGPT-Realtime 1.5を上回るスコアを達成しています。
長時間会話でのコンテキスト喪失を改善
音声エージェントが長い会話の途中でコンテキストを見失い、同じ質問を繰り返したり、前の発言と矛盾する応答をしたりする問題は、ユーザー体験を大きく損ないます。
Gemini 3.1 Flash Liveは、従来モデルの2倍の長さの会話を追跡できるようになり、一貫性のある対話を維持してくれます。
感情を考慮しない画一的な応答
ユーザーが苛立っているのか、困惑しているのかによって、適切な応答のトーンは異なります。
Gemini 3.1 Flash Liveのアフェクティブダイアログ機能は、声のトーンから感情を読み取り、応答のスタイルを動的に調整することで、よりパーソナライズされた対話体験を提供してくれるようになります。
Gemini 3.1 Flash Liveを使ってみた
それでは実際に、Gemini 3.1 Flash Liveの実力を確かめるために、Google AI StudioのLive機能を使って検証していきましょう。
検証1:日本語での自然な音声対話
Google AI StudioのLiveモードでGemini 3.1 Flash Live Previewを選択し、日本語で話しかけてみました。「来週の京都旅行のプランを一緒に考えてほしい」と伝えたところ、2〜3秒でスムーズな日本語音声で応答が返ってきました。
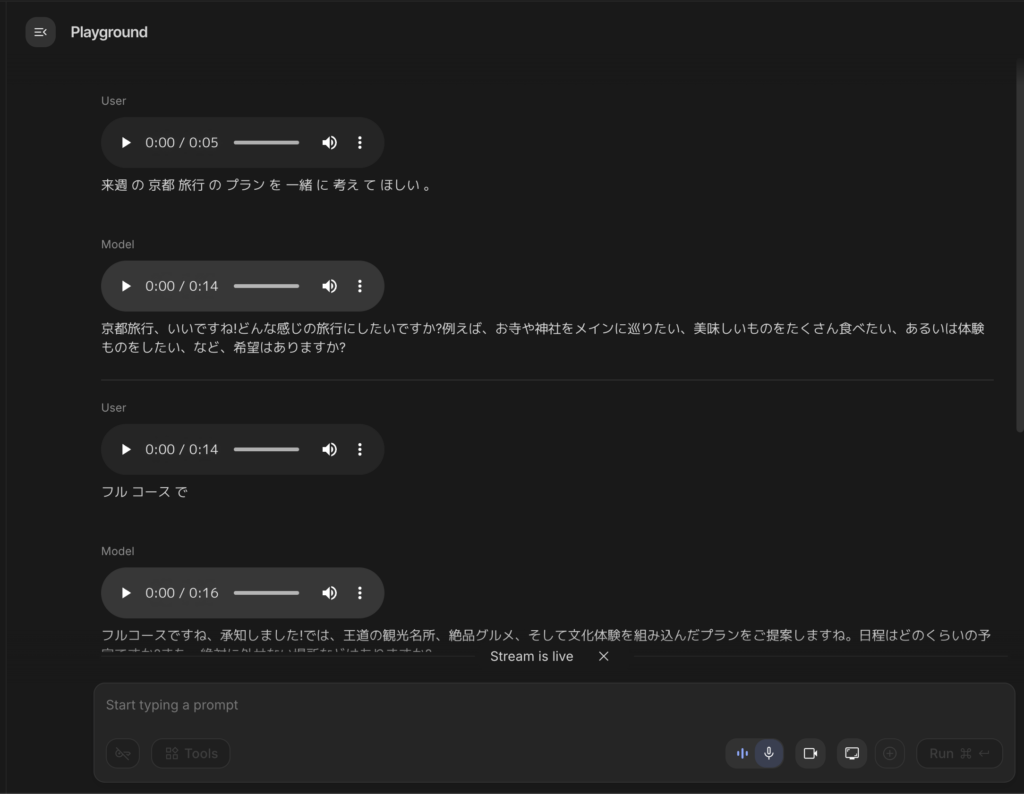
従来のGeminiモデルと比較して日本語の音声品質が明らかに向上している感じがします。特に、語尾の処理や助詞の発音が自然で、AIと話しているという感覚がほとんどない印象です。
会話を続けて「日程は4泊5日。外せない場所は清水寺かな。」と条件を追加すると、先ほどの会話内容を踏まえた上で具体的なプランを提案してくれました。
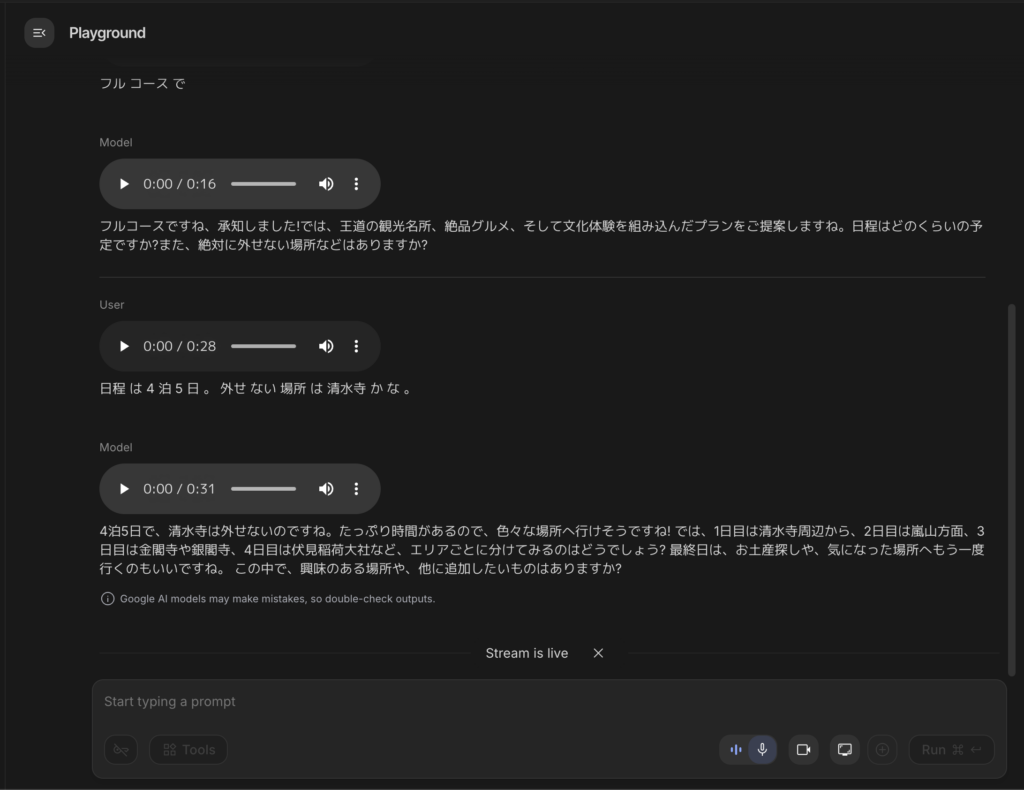
今回は短いやり取りなのでそこまで効果は実感できませんが、会話の追跡能力が2倍になったということで、問題なく、過去のやり取りを踏まえた回答をしてくれました。
また、淡々と「その説明分かんなかったんだけど」と伝えたところ、より詳細に説明をしてくれました。
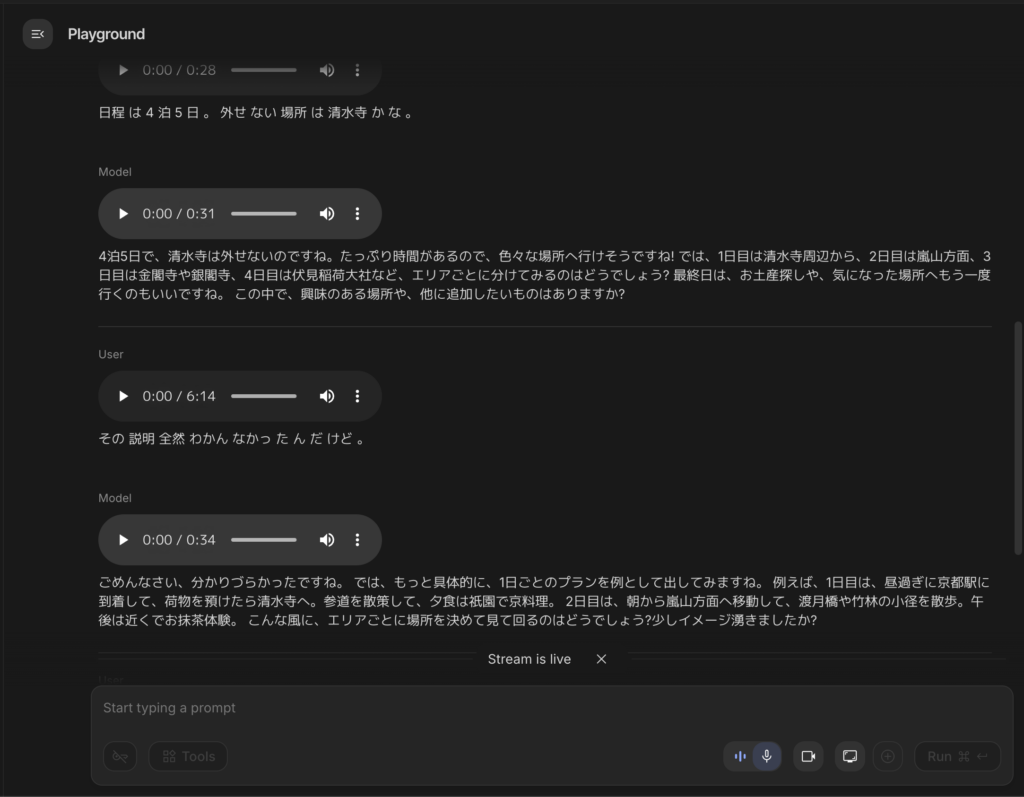
感情を読み取って謝罪文から入ってくれていますね。
よくある質問
最後に、Gemini 3.1 Flash Liveに関して、多くの方が気になるであろう質問とその回答をご紹介します。
Gemini 3.1 Flash Liveで仕事の常識が変わる!
本記事では、Googleの最新リアルタイム音声AIモデル「Gemini 3.1 Flash Live」について、様々な観点からご紹介してきました。
Gemini 3.1 Flash Liveの最大の強みは、低レイテンシのリアルタイム音声対話と、関数呼び出し精度の高さを両立している点です。騒音環境での堅牢性、感情に応じた応答の適応、90以上の言語サポートなど、実用的な音声エージェントの構築に必要な要素が揃っています。
2026年3月30日時点ではプレビュー版ですが、Google AI Studioの無料枠で手軽に試すことができますので、気になった方はぜひ一度試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

