

- 非構造化テキストを意味理解にもとづき高精度に構造化できるGoogle発PythonライブラリLangExtract
- 根拠位置を明示するソースグラウンディングによりハルシネーションを抑制し業務利用に適した安定出力
- メール・議事録・レビュー・契約書など、大量テキストの分類や要点抽出を自動化できる高い実務適性
2025年7月にGoogleが「LangExtract」を発表しました。GitHubでは2万を超えるスターを獲得しており、非常に注目されています。
LangExtractは構造化されていないテキストを分析し、構造化データとして出力してくれるPythonライブラリです。バラバラな形式のメールから「企業名」や「担当者名」を抜き出すことや、荒削りなカスタマーレビューから顧客の「隠れた不満」を抽出することなどは大事な作業ですが、なかなか骨が折れますよね。
LangExtractを利用すれば、そういったテキストデータから必要な情報を抽出・分類する作業を簡単に行うことが可能です。
この記事ではLangExtractの概要や安全性、実装方法、活用シーンを詳しく解説します。ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
LangExtractの概要
LangExtractは、Googleが2025年に発表した大規模言語モデル(LLM)を活用して自然言語テキストから必要な情報を構造化データとして抽出するためのPythonライブラリです。
生成AIに「情報を抜き出して」と頼んでも、勝手に要約してしまったり、存在しない情報を捏造してあたかも正しいように出力してきたり、出力形式が毎回バラバラだったりという問題に遭遇したことはありませんか?
LangExtractは、これらの問題を解決するために「ソースグラウンディング」「信頼性の高い構造化出力」「LLM の世界知識を活用」といった複数の機能を組み合わせて情報抽出を行っています。
これにより単純なキーワード検索ではなく、文章の持つ「意味」や「流れ」を理解して情報を構造化し「文章を使えるデータに変換する」というデータ活用プロセスの常識を大きく塗り替えようとしています。例えばメールやチャット、議事録、SNSの投稿、PDFの報告書など、ビジネス現場には膨大な「非構造化データ」が溢れています。
その中から必要な情報だけを抜き出し、Excelやデータベースで扱える形式に整理するには、手作業か複雑な正規表現を駆使したプログラムが必要でした。
LangExtractを使えば、いままでそのようなコストは劇的に下がり、専門的な知識が必要な医療、法務、金融といった領域でも柔軟に情報を整理できるようになるのです。なお、それぞれの業界における生成AIの活用方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。
医療はこちら

法務はこちら

金融はこちら

LangExtractの特徴
LangExtractの最大の特徴は、「ソースグラウンディング」にあります。
これは、抽出した各項目が原文の「何文字目から何文字目」にあるのかという位置情報を正確にマッピングし、抽出箇所を視覚的に強調表示して追跡を行うことができます。
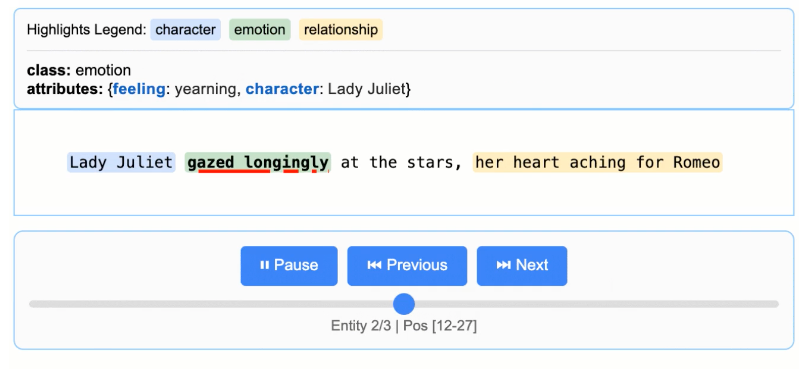
これにより、ユーザーはAIが出力した結果をワンクリックで原文と照らし合わせることができ、AI特有の「もっともらしい嘘」、いわゆるハルシネーションを排除することができます。
例えば、ClaudeやChatGPTといったよく使われている生成AIは汎用LLMであり、情報抽出以外の用途も多いため、プロンプト設計を間違えると余分な文章や表現が混じることがあります。
一方でLangExtractは情報抽出に特化して開発されているため、出力形式のブレが少なく他の処理との相性が良いのも強みとなっています。
特に数万文字を超えるドキュメントを扱う際、LangExtractはチャンク戦略や並列処理を行い、さらに複数回の抽出パスを重ねることで従来のLLM一発の処理では見落としていたようなロングコンテキストの情報抽出を最適化しています。
また、LangExtractは拡張性も高いことも特徴の一つです。
利用できるLLMはGoogleのGeminiやOpenAIのChatGPTといったクラウドベースのLLM以外にもローカルで動作するLlama、Gemmaといったモデルもバックエンドとして使い分けることができます。


LangExtractの安全性・制約
LangExtractは情報の抽出に役立つPythonライブラリですが、利用するにあたって安全性や制約について理解しておく必要があります。LangExtractは単体で動くものではなく、LLMと連携し情報抽出を行います。
そのため、LangExtractを利用するにあたって最も注意しなければいけないのは連携するLLMの安全性と制約です。
まず、安全性についてですが連携先のLLMのセキュリティに準じます。多くの生成AIを利用する上で重要な「個人情報や機密情報などを入力しない」といったことに気をつけましょう。
LangExtractを利用して機密情報などから情報抽出したい場合は、データが外に出ないようにローカルで動作するLLMを利用するのも一つの手段となるでしょう。
LangExtractの料金
LangExtract自体は「無料」のオープンソースソフトウェアとなっています。GitHubからダウンロードし、自分のプログラムに組み込んで使用することに対して費用は発生しません。
実際のコストが発生するのは、バックエンドとして利用するLLMのAPIキーの利用を行うときとなります。
例えば、バックエンドにGPTを使うのであれば「OpenAI APIキー」の費用が必要となります。
LangExtractのライセンス
LangExtractは、Apache License 2.0のもとで提供されています。
Apache License 2.0は非常に自由度の高いライセンスで、商用利用、ソフトウェアの改変や再配布、特許利用や私的利用も原則として許可されます。
| 利用用途 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 | |
| 配布 | |
| 特許使用 | |
| 私的使用 | |
LangExtractの実装方法
LangExtractの実装は非常にシンプルです。事前準備として利用するLLMのAPIキーあるいはローカルLLM環境をセットアップしておきましょう。
今回はGoogleColab上でLangExtractを実装するので、Gemini APIキーを用意してColabファイルのシークレットに登録しておきました。
LangExtractのインストール
まず、pipを使用してライブラリをインストールします。
!pip install langextract以上でLangExtractのセットアップは完了です。
LangExtractの動作確認
LangExtractの公式Githubに掲載されているサンプルを実行し、動作確認を行います。なお、下記コードはGoogleColab用に少し変更しています。
なお、「unicode_tokenizer = tokenizer.UnicodeTokenizer()」の部分がないと日本語を正常にカウントしてもらえず、解析できないのでご注意ください。
import os
import langextract as lx
from langextract.core import tokenizer
from google.colab import userdata
# 1. APIキーの設定
# Colabの「シークレット(鍵アイコン)」に GOOGLE_API_KEY を登録している前提です
os.environ["LANGEXTRACT_API_KEY"] = userdata.get('GOOGLE_API_KEY')
# 解析対象
input_text = "東京出身の田中さんはGoogleで働いています。"
# 抽出プロンプト
prompt_description = "Extract named entities including Person, Location, and Organization."
# お手本データ
examples = [
lx.data.ExampleData(
text="大阪の山田さんはソニーに入社しました。",
extractions=[
lx.data.Extraction(extraction_class="Location", extraction_text="大阪"),
lx.data.Extraction(extraction_class="Person", extraction_text="山田"),
lx.data.Extraction(extraction_class="Organization", extraction_text="ソニー"),
]
)
]
# 2. UnicodeTokenizerの初期化
# 日本語の文字数カウントを正確に行うために必須です
unicode_tokenizer = tokenizer.UnicodeTokenizer()
# 3. 抽出の実行
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt_description,
examples=examples,
model_id="gemini-2.5-flash",
tokenizer=unicode_tokenizer, # トークナイザーを渡す
extraction_passes=2 # 位置特定(Alignment)の精度を上げるために追加推奨
)
# 4. 結果の表示
print(f"Input: {input_text}\n")
print("Extracted Entities:")
for entity in result.extractions:
position_info = ""
# 位置情報(char_interval)が取得できているか確認
if entity.char_interval:
start, end = entity.char_interval.start_pos, entity.char_interval.end_pos
position_info = f" (pos: {start}-{end})"
print(f"• {entity.extraction_class}: {entity.extraction_text}{position_info}")出力結果はこちらです。
LangExtract: model=gemini-2.5-flash, current=24 chars, processed=0 chars: [00:01]
Input: 東京出身の田中さんはGoogleで働いています。
Extracted Entities:
• Location: 東京 (pos: 0-2)
• Person: 田中 (pos: 5-7)
• Organization: Google (pos: 10-16)LangExtractの活用シーン
LangExtractの「意味を理解して構造化する」という従来の生成AIとは違う機能は、あらゆる業界の課題を解決するポテンシャルを秘めています。
単なる文字情報の抜き出しではなく、文脈を捉えた抽出ができるためこれまでは人間にしかできなかった高度な判断業務の自動化が可能になります。
ここでは、様々な分野における具体的な活用例をピックアップし、LangExtractをどのように活用できるのかを紹介します。
問い合わせメールやチャットの分類・優先度付け
問い合わせメールやチャットをLangExtractで読み取り、「請求」「解約」「不具合」などのカテゴリ・緊急度・必要な対応を自動で分類や優先度付けを行うことができます。
文面が長い・要件が混在するケースでも論点を分解、整理して出力されるため、一次対応の工数削減が期待できます。
なお、生成AIを活用したチャットボットに関しては下記の記事を参考にしてください。

近年、業務効率化からAIチャットボットを導入する企業が増えてきています。
AIチャットボットについて詳しく知りたい人におすすめの記事です。
続きを読む
口コミ・レビューの要点を抽出
商品レビューやSNS投稿、口コミから、良い点・不満点・利用シーンなどを抽出し、要点別に集計できます。
単なる感情分析ではなく「何が不満なのか」を具体的な項目に落とし込み、構造化することができるので、商品やサービス改善の優先順位付けの効率化を図ることができます。
なお、感情分析AIについては下記の記事をご覧ください。

議事録・面談メモの決定事項の整理
会議の議事録やメモから、決定事項・担当や期限・未決事項・リスクなどを抽出してタスク管理にも活用することができます。会話調の文章は時系列が崩れがちですがLangExtractなら「誰が何をいつまでに」を構造化しやすいのが特徴です。
JSONでの出力も可能なのでNotion/Slack/スプレッドシートへなど、他サービスへの連携・インポートなども可能です。
なお、生成AIを活用した議事録作成については下記の記事をご覧ください。

契約書・規約の条項抽出しチェックリスト化
利用規約や契約書から、支払い条件・解約条件・免責・損害賠償・更新・通知義務などの条項を抜き出し、比較しやすい表やチェックリストに変換できます。
リビジョンごとの差分比較にも使えるため、レビューの前段で論点整理が可能です。
ただし、最終判断は必ず専門家による確認が必要ですのでご注意ください。
技術ドキュメント・障害報告の構造化
障害報告やバグ報告、専門用語の多い技術メモからでも、再現手順・環境情報・エラーコード・影響範囲・暫定対応・恒久対応案を抽出し、テンプレ化されたレポートに整形することができます。
報告者ごとに書き方が違っていても必要項目を揃えることができるので、調査着手が早くなるためナレッジ蓄積・報告・対応もしやすくなります。
このように、「情報の形式がバラバラで、かつ情報の量が多い」という課題や、単なる抽出だけでなく「なぜその結果になったのか」という透明性が必要な業務プロセスにおいてLangExtractは最適といえるでしょう。
なお、テキスト・画像・動画など異なるモダリティ間の検索について詳しく知りたい方は、下記の記事を合わせてご確認ください。
LangExtractを実際に使ってみた
LangExtractの実力を見るために、今回は日本語の問い合わせメールを題材に「送信者名」「主分類」「緊急度」「依頼事項」を抽出するデモを行いました。
また、通常の生成AIとの出力内容の比較も行いましたので使い分けのイメージも持って頂けると思います。
LangExtractでの日本語の問い合わせメールの解析
日本語は「高文脈文化」とも言われており、文脈が大切と言われていますよね。LangExtractはハイコンテクストの日本語の文章をきちんと情報抽出してくれるのでしょうか
import os
import textwrap
import langextract as lx
from google.colab import userdata
# 1. APIキーの設定
os.environ["LANGEXTRACT_API_KEY"] = userdata.get('GOOGLE_API_KEY')
# 2. プロンプトの定義(何を抽出するかを明確に指示)
prompt = textwrap.dedent("""\
お問い合わせメールから以下の情報を抽出してください。
- sender_name: メールを送信した人の氏名
- primary_category: 主なトピック(例:請求、技術、プランなど)
- urgency: 文面に基づいた緊急度(高、中、低)
- requested_actions: ユーザーが当社に期待する具体的な対応のリスト
可能な限り、メール本文のテキストをそのまま使用してください。""")
# 3. お手本(Example)の定義
# 形式をAIに教えるため、短いダミーメールを例にします
examples = [
lx.data.ExampleData(
text="田中です。ログインできません。至急確認してください。",
extractions=[
lx.data.Extraction(
extraction_class="問い合わせ情報",
extraction_text="田中",
attributes={
"sender_name": "田中",
"primary_category": "技術",
"urgency": "高",
"requested_actions": ["ログインできない原因の確認"]
},
),
],
)
]
# 4. 解析対象のメール本文
input_text = textwrap.dedent("""\
【問い合わせ】
お世話になっております。山本と申します。
先月からスタンダードプランを利用しています。
本題なのですが、3月分の支払いについて少し気になっています。
クレジットカードの明細では3月10日に決済されているように見えるのですが、
管理画面上では現在も「未払い」と表示されたままです。
実は、以前(たしか1月頃だったと思います)にも
同じような表示になったことがあり、
その際は特に連絡せず、しばらくしたら自然に解消されました。
今回も同じようなケースなのか判断がつかず、念のためご連絡しました。
急ぎの対応をお願いしたいわけではないのですが、
もしこの状態が続くとサービスが停止される可能性があるのであれば困ります。
停止の条件やタイミングが決まっていれば、事前に教えていただけると助かります。
また、もし原因がこちらの設定や手続き不足によるものであれば、
どのように対応すればよいかもあわせてご案内いただけますでしょうか。
お手数ですが、ご確認のほどよろしくお願いいたします。
""")
# 5. 抽出の実行
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
# 6. 結果を見やすく表示
print("="*50)
print("📧 メール解析結果")
print("="*50)
for ext in result.extractions:
attrs = ext.attributes
print(f"👤 送信者名 : {attrs.get('sender_name')}")
print(f"📁 主分類 : {attrs.get('primary_category')}")
print(f"🚨 緊急度 : {attrs.get('urgency')}")
print(f"📝 依頼事項 :")
actions = attrs.get('requested_actions', [])
if isinstance(actions, list):
for action in actions:
print(f" ・ {action}")
else:
print(f" ・ {actions}")
print("="*50)生成結果はこちらです。
LangExtract: model=gemini-2.5-flash, current=450 chars, processed=0 chars: [00:06]
==================================================
📧 メール解析結果
==================================================
👤 送信者名 : 山本
📁 主分類 : 請求
🚨 緊急度 : 中
📝 依頼事項 :
・ 管理画面の未払い表示の確認
・ サービス停止の条件やタイミングの提示
・ 対応方法の案内
==================================================ChatGPTでの日本語の問い合わせメールの解析
では次にChatGPTに同じ内容のメールを解析してもらいましょう。
プロンプトはLangExtractのものをそのままで、下記のように入力しました。
下記お問い合わせメールから以下の情報を抽出してください。
- sender_name: メールを送信した人の氏名
- primary_category: 主なトピック(例:請求、技術、プランなど)
- urgency: 文面に基づいた緊急度(高、中、低)
- requested_actions: ユーザーが当社に期待する具体的な対応のリスト
可能な限り、メール本文のテキストをそのまま使用してください。
#メール本文
【問い合わせ】
お世話になっております。山本と申します。
先月からスタンダードプランを利用しています。
本題なのですが、3月分の支払いについて少し気になっています。
クレジットカードの明細では3月10日に決済されているように見えるのですが、
管理画面上では現在も「未払い」と表示されたままです。
急ぎの対応をお願いしたいわけではないのですが、
もしこの状態が続くとサービスが停止される可能性があるのであれば困ります。
停止の条件やタイミングが決まっていれば、事前に教えていただけると助かります。
また、もし原因がこちらの設定や手続き不足によるものであれば、
どのように対応すればよいかもあわせてご案内いただけますでしょうか。
お手数ですが、ご確認のほどよろしくお願いいたします。ChatGPTの回答はこちらです。特に指示していませんがJSONで出力してくれました。
{
"sender_name": "山本",
"primary_category": "請求(支払い状況/未払い表示)",
"urgency": "中",
"requested_actions": [
"「クレジットカードの明細では3月10日に決済されているように見える」一方で「管理画面上では現在も『未払い』と表示」されている件の確認",
"「この状態が続くとサービスが停止される可能性がある」ため、「停止の条件やタイミングが決まっていれば、事前に教えていただけると助かります」という案内",
"「原因がこちらの設定や手続き不足によるものであれば、どのように対応すればよいか」の案内"
]
}ChatGPTも特に問題なく情報の整理と分類が行われていますね。
LangExtractとChatGPTの差は「出力データの使いやすさ」にあり
何度も同じプロンプトを試しているとChatGPTは汎用生成AIらしさが出力結果に現れるようになりました。ChatGPTによる2回目と3回目の出力は下記の通りです。
ChatGPTの2回目の出力
{
"sender_name": "山本",
"primary_category": "請求",
"urgency": "中",
"requested_actions": [
"管理画面上では現在も「未払い」と表示されたままです。ご確認のほどよろしくお願いいたします。",
"停止の条件やタイミングが決まっていれば、事前に教えていただけると助かります。",
"もし原因がこちらの設定や手続き不足によるものであれば、どのように対応すればよいかもあわせてご案内いただけますでしょうか。"
]
}ChatGPTの3回目の出力
{
"sender_name": "山本",
"primary_category": "請求(支払い・未払い表示)",
"urgency": "中",
"requested_actions": [
"「クレジットカードの明細では3月10日に決済されているように見えるのですが、管理画面上では現在も『未払い』と表示されたままです。」の状況確認・原因調査",
"「停止の条件やタイミングが決まっていれば、事前に教えていただけると助かります。」への回答(サービス停止の条件・タイミングの案内)",
"「もし原因がこちらの設定や手続き不足によるものであれば、どのように対応すればよいかもあわせてご案内いただけますでしょうか。」への対応方法の案内"
]
}送信者と緊急度は同じ情報が出力されていますが、「主分類」と「依頼事項」の出力内容に差があります。
例えば主分類だと「請求(支払い・未払い表示)」というように単純なカテゴリではなく問い合わせ内容も少し考慮したものになっています。
ChatGPTは単発の分析だと問題ありませんが、大量のメールを分析する場合このようなブレがあると正常に分類できません。
一方で、LangExtractは何度生成しても、「送信者名:山本」「 主分類: 請求」「緊急度:中」というようにラベリングしやすい項目は一貫して同じ情報が出力されており、「依頼事項」の部分も重要な箇所のみ箇条書きになっていました。


LangExtractに関するよくある質問
なお、生成AIを使ってデータ分析を行う方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではLangExtractの概要から仕組み、実際の使い方やChatGPTとの比較について解説をしました。
導入が非常にシンプルなのに、精度が高い情報抽出を行うことが可能なLangExtractを利用すれば、テキストデータから必要な情報を抽出・分類する作業にかかる時間を大幅にカットすることができます。
ぜひ皆さんも本記事を参考にLangExtractを使ってみてください!

最後に
いかがだったでしょうか?
メール・議事録・契約書の情報抽出を、根拠付きでブレなく自動化。弊社のサポートなら、LangExtract導入PoCの設計からKPI・費用試算まで、失敗しない進め方を整理します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

