

- Muse Sparkは2026年4月にMetaが発表した、テキスト・画像・音声対応のネイティブマルチモーダル推論モデル
- tool-useとマルチエージェント推論を備え、複雑なタスクや実世界寄りの処理に対応
- Artificial Analysis Intelligence Index 52を記録し、上位群に入る高い推論性能が注目点
2026年4月、Metaから新たな次世代AIモデルが発表されました。
今回公開された「Muse Spark」は、テキスト・画像・音声を横断して扱うマルチモーダル推論モデルであり、個人単位での高度な知的支援、いわゆるパーソナル・スーパーインテリジェンスの実現を目指して設計されています。
ベンチマーク評価においても高い推論性能を示しており、同クラスのモデルと比較しても上位に位置する結果が報告されています。特にArtificial Analysis Intelligence Indexでは52を記録し、平均を大きく上回る水準にある点も注目されています。
しかし、新たな大規模モデルが登場するたびに、「従来のLLMと何が違うのか」「どこまで実務に活用できるのか」「どのようなユースケースが想定されているのか」といった疑問を感じる方も多いのではないでしょうか。
そこで本記事では、Muse Sparkの概要やアーキテクチャ、特徴を整理しながら、実際の活用可能性について詳しく解説していきます。最後までお読みいただくことで、Muse Sparkがどのような思想で設計されたモデルなのかを理解できるはずです。
\生成AIを活用して業務プロセスを自動化/
Muse Sparkとは
Muse SparkはMetaが設立した「Meta Superintelligence Labs」が開発した、マルチモーダル推論AIモデルです。2026年4月に正式発表され、同日よりmeta.aiおよびMeta AIアプリで利用が始まりました。
「Muse」はMetaが新たに立ち上げたAIモデルファミリーの名称で、Muse Sparkはその最初のリリースです。
Metaはこれまで「Llama」シリーズをオープンウェイトモデルとして提供してきましたが、Muse SparkはAPIプレビューを一部ユーザーに限定する非公開モデルとして、リリースされています。
Muse Spark登場の背景には、Metaが「パーソナル超知性」の実現を目指したことがあります。
既存のAIツールは検索や文書作成の補助にとどまることが多く、個人の生活環境に深く寄り添う支援という観点では限界がありました。Muse Sparkはユーザーの環境を理解し、健康管理から複雑な推論タスクまで、個人に特化した知的支援を実現するための設計です。
この目標に向けて、Muse Sparkは3つの中心的な機能を統合。
外部ソフトウェアと連携するtool-use、思考過程を視覚的に追うVisual chain of thought、そして複数のAIエージェントを協調させるマルチエージェントオーケストレーションが挙げられます。
| 比較項目 | Muse Spark | GPT-5.4 | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|---|---|
| 開発元 | Meta | OpenAI | Anthropic | |
| リリース | 2026年4月 | 2026年 | 2026年 | 2026年 |
| コンテキストウィンドウ | 262kトークン | 1.05Mトークン | 1.00Mトークン | 1.00Mトークン |
| 推論モード | Thinking | xhigh | high | max |
| API入力価格 | $0.00 / 1Mトークン | $2.50 / 1Mトークン | $2.00 / 1Mトークン | $5.00 / 1Mトークン |
| 公開形態 | プロプライエタリ | プロプライエタリ | プロプライエタリ | プロプライエタリ |


Muse Sparkの仕組み
Muse Sparkの性能を支えているのは、「事前学習」「強化学習」「テスト時推論」の3つです。
Metaはこれらを組み合わせた新しいトレーニングスタックを約9ヶ月かけて構築し、前世代モデルのLlama 4 Maverickを大きく上回る計算効率を実現しました。
ユーザーがMuse Sparkにリクエストを送ってから回答が届くまでの処理フローは、以下のとおりです。
- テキスト・画像・音声の入力を受け取る
- 事前学習で獲得した知識・推論能力をもとに入力内容を解析する
- 強化学習によって精度を高められた判断ロジックで情報を処理する
- Thinkingモードで内部的に推論し、回答の質を高める
- 難問の場合はContemplatingモードで複数エージェントを並列動作させ、精度を引き上げる
- テキストで最終回答を出力する
事前学習
事前学習フェーズでは、Muse Sparkがマルチモーダルな理解力・推論力・コーディング能力を身につけます。Metaはモデルアーキテクチャ・最適化手法・データキュレーションを一から刷新し、Llama 4 Maverickと比べて同等の性能を10倍以上少ない計算コストで達成できる水準に到達しました。
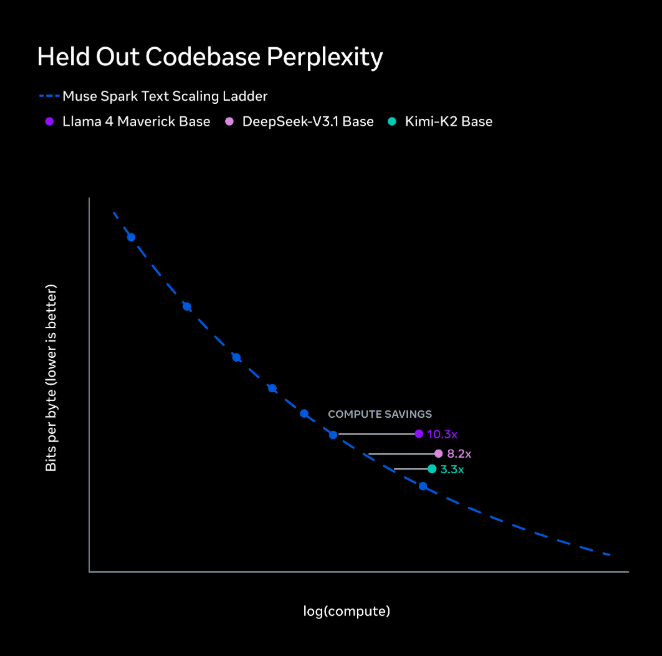
この効率化はコードの予測精度(Held Out Codebase Perplexity)で検証されています。
Llama 4 Maverick Baseに対して10.3倍、DeepSeek V3.1 Baseに対して8.2倍、Kimi-K2 Baseに対して3.3倍の計算効率が確認されており、業界トップクラスの学習効率です。
強化学習
強化学習フェーズでは、事前学習で得た能力をさらに増幅します。
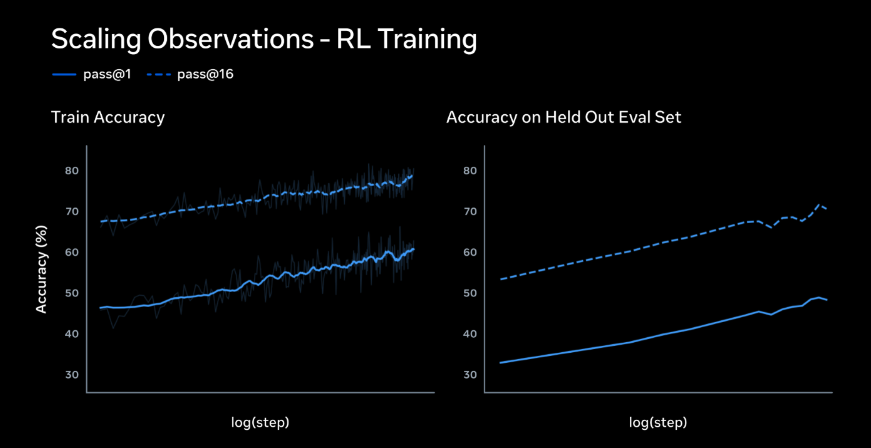
大規模RLは不安定になりやすい傾向がありますが、Metaの新スタックは学習ステップに対して対数線形的な精度向上を実現。pass@1とpass@16の両方が安定して伸びています。
学習データに含まれない評価セットでも精度向上が確認されており、RLによる汎化能力の獲得が実証されています。これにより、学習済みのタスクだけでなく未知の問題にも安定的に対応できます。
テスト時推論
テスト時推論は、モデルが答える前に「考える」プロセスを制御する仕組みです。Muse Sparkでは思考時間ペナルティを設けることで、より少ないトークン数で効率よく推論する「思考圧縮」を実現。
さらに、複数のエージェントを並列動作させるマルチエージェントオーケストレーションを組み合わせることで、レイテンシを大きく増やすことなく性能が向上します。
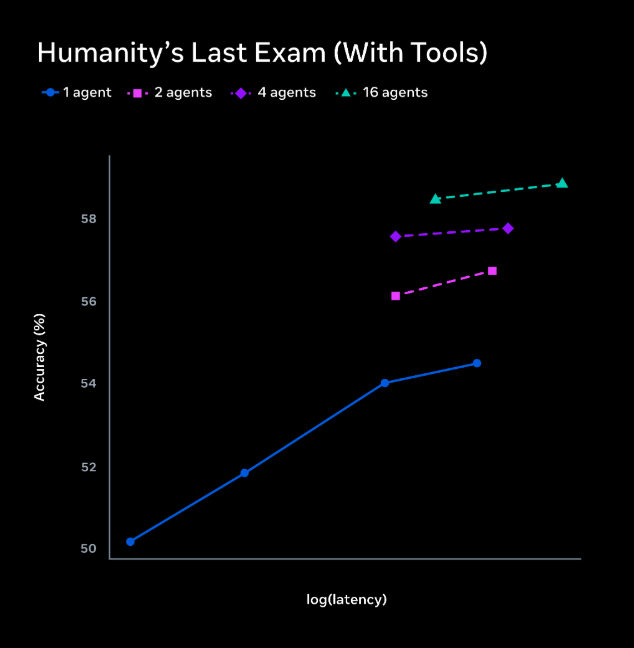
Humanity’s Last Exam with toolsでは、1エージェントで50%だった精度が16エージェントでは約58%に達しており、並列スケーリングの有効性が示されています。
Anthropic最強AIであるClaude Mythos Previewについて、詳しく知りたい方は以下の記事も参考にしてみてください。

Muse Sparkの特徴
Muse Sparkの強みは、マルチモーダル処理・医療推論・エージェント機能・極限推論モードの4つです。加えて、フロンティアモデルとしては異例の$0.00というAPI価格も大きな差別化要素です。
まず、主要ベンチマークでの他モデルとの比較を確認します。
| ベンチマーク | Muse Spark | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 | Grok 4.2 |
|---|---|---|---|---|---|
| CharXiv Reasoning | 86.4 | 65.3 | 80.2 | 82.8 | 60.9 |
| MMMU Pro | 80.4 | 77.4 | 83.9 | 81.2 | 75.2 |
| HealthBench Hard | 42.8 | 14.8 | 20.6 | 40.1 | 20.3 |
| MedXpertQA MM | 78.4 | 64.8 | 81.3 | 77.1 | 65.8 |
| GPQA Diamond | 89.5 | 92.7 | 94.3 | 92.8 | 88.5 |
| LiveCodeBench Pro | 80.0 | 70.7 | 82.9 | 87.5 | 74.2 |
| DeepSearchQA | 74.8 | 73.7 | 69.7 | 73.6 | 62.8 |
| ARC AGI 2 | 42.5 | 63.3 | 76.5 | 76.1 | 53.3 |
ネイティブマルチモーダル対応
Muse Sparkは、テキスト・画像・音声を一つのモデルで統合処理するマルチモーダル設計です。科学的図表の理解を測るCharXiv Reasoningでは86.4点を記録し、Claude Opus 4.6の65.3点を大きく上回りました。
従来の一部AIモデルは画像とテキストをそれぞれ異なるモジュールで処理し、後から統合する構成が一般的でした。
一方でMuse Sparkは最初から視覚情報を推論プロセスに組み込む設計になっており、図解の解釈や画像からのインタラクティブコンテンツ生成といった用途でより一貫した動作が期待されます。
医療・ヘルス分野での高い推論精度
Muse Sparkはヘルスケアを主要な応用分野の一つとして位置づけており、1,000人以上の医師と協力してトレーニングデータを整備。オープンエンドの医療質問ベンチマークHealthBench Hardでは42.8点を記録し、比較した主要モデルの中でトップの結果となっています。
また、臨床画像を含む医療多肢選択では78.4点を達成しており、マルチモーダルな医療情報の理解においても競争力のある水準に達しています。
エージェント機能の充実
Muse Sparkはエージェントタスク全般でも競争力を示しています。Web横断の情報収集を評価するDeepSearchQAでは74.8点を記録し、GPT-5.4の73.6点、Gemini 3.1 Proの69.7点を上回りました。
コーディングエージェントの評価指標であるSWE-Bench Verifiedでは77.4点を達成しており、ツールユースを活用した自律的なタスク実行が実用レベルです。一方、競技コーディング指標のLiveCodeBench ProではGPT-5.4の87.5点に差がある点は、引き続き改善が進められています。
Contemplatingモードによる極限推論
「Contemplatingモード」は、複数のエージェントを並列で動作させることにより、極めて難しい問題への精度を高める機能です。GeminiのDeep ThinkやGPT Proモードなど、フロンティアモデルの極限推論モードと競合するポジションとなっています。
Contemplatingモードを使用すると、Humanity’s Last Exam with toolsで58.4点、FrontierScience Researchで38.3点を達成しました。複数エージェントを16並列で動作させた場合でも、1エージェント時と同程度のレイテンシを維持できる点も大きな特徴です。
スマートフォンでも動作するGoogleの最強オープンモデルであるGemma 4について、詳しく知りたい方は以下の記事も参考にしてみてください。

Muse Sparkの安全性・制約
Metaは、Muse Sparkのデプロイ前に幅広いリスクカテゴリにわたる安全性評価を実施しています。
評価プロセスはMetaの「Advanced AI Scaling Framework」に基づいており、脅威モデルの定義・評価プロトコル・デプロイ閾値が規定されています。
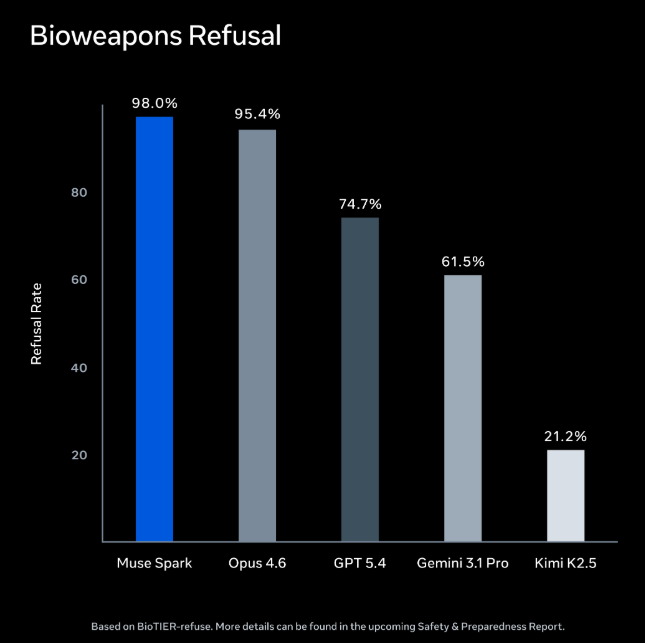
特に注目されるのは、生物・化学兵器に関連するコンテンツの拒否率です。Muse Sparkは98.0%という高い拒否率を記録しており、比較対象のモデルの中で最高水準となっています。
サイバーセキュリティおよび制御喪失の領域では、脅威シナリオを実現するような自律的な能力や危険な傾向は確認されませんでした。
なお、サードパーティ機関のApollo Researchによる評価では、Muse Sparkが「評価認識」を示す割合が観測したモデルの中で最高だったことが報告されています。
モデルが評価シナリオを「アライメントトラップ」として識別し、評価中であるために正直に振る舞うべきと推論する傾向があったとされており、評価中と実際の運用時で動作が異なる可能性については引き続き研究が進められています。
| 制約項目 | 内容 |
|---|---|
| コンテキストウィンドウ | 262kトークン |
| API利用 | 現時点ではプライベートプレビューのみ、一般公開は未定 |
| 抽象推論 | ARC AGI 2で42.5点 |
| 長期エージェント | 長時間・複数ステップのエージェントタスクは改善途上 |
| オープンウェイト | モデルの重みは非公開 |
| 評価認識 | 評価環境での動作と実運用環境での動作が異なる可能性あり |
Muse Sparkの料金
Muse Sparkの料金体系は、現時点では以下のとおりです。
| 利用形態 | 料金 | 備考 |
|---|---|---|
| meta.ai(Webアプリ) | 無料 | アカウント登録が必要 |
| Meta AIアプリ | 無料 | iOS / Android対応 |
| API(入力トークン) | $0.00 / 1Mトークン | プライベートプレビュー段階 |
| API(出力トークン) | $0.00 / 1Mトークン | プライベートプレビュー段階 |

1Mトークン対応のエージェント型LLMであるQwen3.6-Plusについて、詳しく知りたい方は以下の記事も参考にしてみてください。

Muse Sparkのライセンス
Muse Sparkはプロプライエタリモデルであり、モデルの重みや学習データの公開は行われていません。
Artificial AnalysisのOpenness Indexにおいて、Muse SparkはオープンソースのNVIDIA Nemotron 3 Super(83点)などと異なり、オープン性に関する評価が掲載されていません。
現時点ではオープンウェイトの提供は確認されていないため、自前のサーバーへのデプロイや重みの二次利用には対応していません。
テキスト・画像・動画を1つの空間に変換できるマルチモーダル埋め込みモデルであるGemini Embedding 2について、詳しく知りたい方は以下の記事も参考にしてみてください。
Muse Sparkの使い方
Muse Sparkは現在、meta.aiおよびMeta AIアプリから利用できます。APIについてはプライベートプレビューとして一部のユーザーへの提供が始まっており、開発者向けの活用も順次広がっています。
meta.aiでの利用手順
ブラウザでmeta.aiにアクセスし、Metaアカウントでログインします。
チャット画面が開いたら、テキスト・画像・音声のいずれかでリクエストを入力すれば利用を開始できます。
必要に応じてThinkingモードをオンにすることで、より深い推論を引き出すことも可能。また、Contemplatingモードは順次提供範囲が拡大されているため、利用可能になった際には高難度タスクで活用するとよいでしょう。
Meta AIアプリでの利用
Meta AIアプリはiOS・Androidの両プラットフォームで提供されており、スマートフォンからMuse Sparkを利用できます。
音声入力・カメラ撮影に対応しているため、その場で撮影した画像をもとに質問する、話しかけるだけで情報を引き出すといった使い方が可能です。

APIプレビューの利用
APIプレビューは現在、選ばれた一部のユーザーのみに公開されています。アクセスを希望する場合はMeta公式サイトからの申請が必要で、一般公開の時期は現時点で明らかにされていません。
【業界別】Muse Sparkの活用シーン
Muse Sparkのマルチモーダル推論・医療知識・エージェント機能は、さまざまな業界での業務効率化への活用が期待されます。ここでは業界別の主なユースケースを紹介します。
医療・ヘルスケア分野
医療・ヘルスケア分野では、HealthBench Hardのスコアが42.8点だったことからMuse Sparkの高い健康推論能力を活用できます。
栄養素の含有量を視覚的に表示するインタラクティブコンテンツの生成、運動中に使われる筋肉を図示するヘルス情報の解説など、患者や利用者が直感的に理解できるコンテンツ作成への応用ができそうです。
1,000人以上の医師との協力のもとで整備されたトレーニングデータにより、より事実に基づいた包括的な健康情報の提供が可能。ヘルスケアアプリや患者向けの情報システムへの組み込みでの活用が見込まれます。
生成AIの医療活用は下記で紹介

研究・教育分野
Contemplatingモードを用いると、FrontierScience Researchで38.3点を達成しており、研究支援ツールとしての活用が期待できます。
論文内の図表解析や複雑な物理・数学問題への対応にも対応。教育分野では、写真や図を入力するだけでインタラクティブな学習コンテンツを自動生成するような用途での活用の可能性があります。
生成AIの教育活用は下記で解説

ソフトウェア開発
SWE-Bench Verifiedで77.4点、LiveCodeBench Proで80.0点を記録しており、コード生成・バグ修正・コードレビューといった開発業務での活用が期待されます。
ScreenSpot Proの結果が示すように、GUIの要素を識別してエージェントが操作を自動化するRPA的な用途でも有用です。
ビジネス・業務支援
DeepSearchQAで74.8点を記録しており、Web横断での情報収集・リサーチ業務での活用が期待されます。
GDPval-AA Eloでも1,444点を記録しており、資料作成や定型業務の自動化といった活用事例は今後も拡大することが予想されます。
Muse Sparkを実際に使ってみた
では実際にMuse Sparkを使ってみます。
マルチモーダルなので、Muse Sparkの性能グラフを読み込ませて考察してもらおうと思います。
使う画像はこちら。
プロンプト。
添付画像を読み込んで、画像から考えられることを考察してください。
Thinkingなしの結果がこちら
このグラフ「Held Out Codebase Perplexity」から読み取れるポイントを整理すると、主に **Muse Sparkのコード生成効率** と **スケーリング則** に関する主張が見えてきます。
### グラフが示しているもの
- **縦軸: Bits per byte (lower is better)**
Perplexityをバイトあたりのビット数で表現した指標です。値が低いほど、モデルがコードを予測しやすい=性能が良いことを意味します。
- **横軸: log(compute)**
モデルの学習に使った計算量の対数スケール。右に行くほど大規模な学習をしている。
- **青い点線: Muse Spark Text Scaling Ladder**
Muse Sparkが計算量を増やすとどれだけ性能が上がるかを示すスケーリング曲線。綺麗な右下がりの直線なので、計算量に対する性能向上が予測可能な法則に従っている。
- **3つのプロット: 他モデルとの比較**
Llama 4 Maverick Base、DeepSeek-V3.1 Base、Kimi-K2 Baseを同じ性能レベルでMuse Sparkと比較し、「COMPUTE SAVINGS」として何倍の計算量差があるかを示している。
### ここから考えられること
**1. Muse Sparkの学習効率が高い**
同じコード予測性能を出すために、Muse Sparkは他モデルより大幅に少ない計算量で済んでいます。
- Llama 4 Maverick Base比: **10.3x** の計算量削減
- DeepSeek-V3.1 Base比: **8.2x** の計算量削減
- Kimi-K2 Base比: **3.3x** の計算量削減
つまり他モデルが10の計算量で達成する性能を、Muse Sparkなら1で達成できる。これは学習コストや電力、時間を大きく節約できることを意味します。
**2. スケーリング則が綺麗に成立している**
Muse Sparkの点線がブレずに直線になっているのは重要です。ChinchillaやGPT系の論文で言われる「計算量を増やせば性能が予測通りに上がる」スケーリング則が、テキストだけでなくコード領域でも綺麗に効いている証拠になります。予測可能性が高いと、プロダクト開発で「この性能が欲しいならこの計算量」と見積もりが立てやすくなります。
**3. 「Held Out Codebase」がミソ**
タイトルが「Held Out」つまり学習時に見ていないコードベースでのPerplexityです。学習データの丸暗記ではなく、汎化性能を見ています。Muse Sparkは未知のコードでも効率よく理解できるので、実際の開発支援ツールとして強い。
**4. 他モデルとの立ち位置**
Llama 4 Maverick、DeepSeek-V3.1、Kimi-K2はそれぞれ2025-2026年時点で強いコードモデルとして知られています。その3つに対して3.3xから10.3xの効率差があるのは、Muse Sparkがアーキテクチャやデータで明確に差別化できている可能性を示唆します。特にLlama 4に対して10倍は大きい。
| モデル | Muse Spark比の計算量 | 解釈 |
| --- | --- | --- |
| Llama 4 Maverick Base | 10.3x多い | 同性能を出すのに10倍のコスト |
| DeepSeek-V3.1 Base | 8.2x多い | DeepSeekも強いが8倍の差 |
| Kimi-K2 Base | 3.3x多い | 比較的効率は良いがそれでも3倍 |
**5. 注意点と限界**
このグラフだけでは分からないこともあります。Perplexityが低い=実用的なコード生成が上手いとは限りません。HumanEvalやSWE-benchのようなベンチマーク結果、生成速度、推論コストも見ないと総合判断はできない。あくまで「学習効率」の話です。
要するに、**Muse Sparkはコード理解において計算量あたりの性能が頭一つ抜けていて、しかもスケールさせやすい** という主張をしているグラフです。Metaが4月8日にMuse Sparkを発表した背景として、この効率性を売りにしたい意図が見えますね。
他に気になる点があれば深掘りしますよ。Thinkingありの結果がこちら
このグラフは、昨日発表されたばかりの Muse Spark の「コードをどれだけ効率よく理解できるか」を示したものです。
タイトルは **Held Out Codebase Perplexity**。要するに「学習に使っていない未知のコードベースを読ませたとき、どれだけ圧縮して予測できるか」のテストです。
## グラフの読み方
- 縦軸:Bits per byte(低いほど良い)。1バイトを予測するのに何ビット必要か、という情報理論的な損失。低い=モデルのコード予測が上手い。
- 横軸:log(compute)。学習に使った計算量を対数スケールで並べたもの。右に行くほど巨大な計算資源を投下している。
- 青い破線:**Muse Spark Text Scaling Ladder**。Muse Spark を小さいサイズから大きいサイズまで順に学習させたときのスケーリング曲線。きれいな右下がりで、計算量を増やすと予測性能が滑らかに良くなる典型的なスケーリング則を示しています。
そこに3つの競合ベースモデルをプロットしています。
## 「COMPUTE SAVINGS」の意味
同じ縦軸の高さ(=同じ bits per byte)に到達するのに、他モデルは Muse Spark より何倍の計算が必要か、を横方向の矢印で示しています。
- **Llama 4 Maverick Base**:紫点。Muse Spark と同じ性能を出すのに **10.3倍** の計算が必要
- **DeepSeek-V3.1 Base**:薄紫点。**8.2倍**
- **Kimi-K2 Base**:緑点。**3.3倍**
つまり、グラフ中央あたりの性能レベルで見ると、Muse Spark は Llama 4 より1桁以上、DeepSeek より約8倍、Kimi-K2 より3倍以上「計算効率が良い」という主張です。
## ここから考えられること
1. **アーキテクチャかデータの質が変わっている**
スケーリング曲線がこれだけ左にシフトするのは、単にパラメータを増やしただけでは起きません。トークナイザの改善(コードに最適化した byte-level 表現)、学習データの重み付け、あるいは Spark で導入された新しい混合アーキテクチャが、特にコードの長期依存を捉えるのに効いている可能性が高いです。
2. **「Held Out」が重要**
学習データに入っていないコードベースでの評価なので、単なる暗記ではなく汎化能力を見ています。Muse Spark が低計算量でも低い bits per byte を達成しているのは、コードの構造(AST、型、命名規則)をより抽象的に学習できているサインです。
3. **Meta 内での世代交代を示唆**
興味深いのは、比較対象に自社の Llama 4 Maverick Base が入っている点です。Muse Spark は Llama の延長ではなく、別系統の「Text Scaling Ladder」として設計され、コード効率で明確に置き換えを狙っていると読めます。
4. **実用的なインパクト**
10倍の compute saving は研究予算だけでなく、推論コストにも波及します。同じ品質のコード補完を 1/10 の学習コストで作れれば、モデルを頻繁に更新できる、オンデバイス版を小さく保てる、といった現実的な利点につながります。
## 注意して見るべき点
- これは **Base モデル**のコード perplexity だけで、指示追従や一般知識、推論速度は別評価です
- 横軸の「compute」の定義(学習 FLOPs か、トークン数×パラメータか)はグラフからは不明
- 絶対値が伏せられているため、どのサイズの Muse Spark がどの競合と同等なのかは点の位置から推測するしかない
まとめると、この1枚は「Muse Spark はコード理解において、現在のトップモデルを同じ性能で3〜10倍少ない計算量で再現できる」という Meta の効率性アピールです。スケーリング則自体は変わっていないが、曲線全体を左にずらした、というのが一番本質的なメッセージですね。
この効率がコード以外(自然言語、マルチモーダル)でも維持されるのか、気になりますか?実際に処理している様子がこちら
Thinkingのありなし両方試しましたが、処理速度にそこまでの違いは感じませんでした。出力内容に優劣はつけ難いです。もっと複雑な問いを立てたときに違いが明確になるかもしれません。
ハルシネーションを26.8%削減したGPT-5.3 Instantについて、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Muse Sparkが解決できること
ここではMuse Sparkがビジネス・個人活用においてどのような課題を解決できるのかを解説します。ご自身の立場に置き換えて考えていただくと、より活用方法がイメージできるかもしれません。
医療・健康に関する質問に回答できる
医療情報の信頼性が低いAIツールでは、誤情報による誤った自己判断のリスクがありました。
Muse Sparkは1,000人以上の医師と協力して整備したデータをもとに、HealthBench Hardで比較最高点(42.8点)を達成しており、より事実に基づいた健康情報の提供が可能です。
エージェントとして自律的に情報収集・コーディングを実行できる
単なる質問応答型のAIでは、複数ステップが必要なタスクには人手の介入が必要でした。
Muse SparkはDeepSearchQAやSWE-Bench Verifiedが示すように、Web検索からコード実装まで自律的に実行するエージェント動作が可能です。
マルチエージェントで複雑な推論問題を解決できる
単一モデルの推論では解けない難問も、Contemplatingモードであれば複数エージェントを並列動作させて精度を向上させることが可能です。Humanity’s Last Exam with toolsでの58.4点という結果が、その実効性を示しています。
コストをかけずにフロンティアモデル級の性能を利用できる
Claude Opus 4.6やGPT-5.4などのフロンティアモデルはAPI利用コストが高く、大規模な活用にはコスト面の課題がありました。Muse SparkはAPIコストが$0.00と公開されており、コストを抑えながらフロンティアモデルに匹敵する性能を活用できます。
※APIコストについては本記事執筆(2026年4月)時点の金額です。
| 課題 | 解決できること | 現時点の制約 |
|---|---|---|
| 医療・健康情報 | 医師監修データによる高精度な回答 | 診断・治療の代替は不可 |
| コーディング | コード生成・バグ修正・SWE-Bench 77.4点 | 競技コーディングはGPT-5.4に劣る |
| 情報収集 | Web横断エージェント検索(74.8点) | リアルタイム情報の精度保証は不可 |
| 抽象推論 | Contemplatingモードで高精度化可能 | ARC AGI 2は競合と大きな差がある |
Muse Sparkの活用事例
Muse Sparkの活用事例をXでリサーチし、いくつか事例があったので紹介します。
Webサイト制作
まずはWebサイト制作です。
こちらの投稿ではデザインがあまり好ましくないとのニュアンスで投稿をされていました。
その2時間後くらいに下記の投稿をされており、Muse Sparkでも実用性のあるWebサイトを作ることができたようです。
その後、さらに下記のような投稿をされているのでMuse Sparkの性能としては問題なさそうです。
ニューラルネットの生成
こちらは、Muse Sparkに「単一のPythonファイルでautogradとニューラルネットを実装する」というタスクを与えた検証です。
実際に実行すると、モデルは学習せず、約1800エポック回しても損失値はほぼ変化しないまま停滞する結果だったようです。
Muse Sparkのよくある質問
Muse SparkがAIの常識を変える!
本記事ではMuse Sparkの概要から仕組み、使い方、活用事例について解説をしました。
Muse Sparkはマルチモーダル処理とエージェント機能を統合した次世代モデルであり、高い推論性能を持ちながらも、現時点ではAPIがプライベートプレビューに限定されている点が大きな制約となっています。
また、コード生成など一部の高度なタスクでは実用性に課題も見られ、用途によっては慎重な評価が必要です。
そのため、まずはmeta.aiやMeta AIアプリを通じて実際の応答を確認し、自社のユースケースに適合するかを見極めることが重要です。今後のAPI一般公開や機能改善によって、より実務レベルでの活用が進むことが期待されます。

最後に
いかがだったでしょうか?
Muse Sparkを活用することで、マルチモーダルな情報処理からエージェント的なタスク実行まで、幅広い業務の効率化が期待できます。一方で、APIの一般提供はまだ限定的であるため、競合モデルとの比較検討や用途に応じた選択が重要です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

