

- YOLOは、画像を一度の処理で解析するリアルタイム物体検出アルゴリズムの代表格
- 検出から識別までを単一CNNで完結し高速かつ高精度な推論を実現
- オープンソースで導入容易一方で小物体や密集物体の検出は課題
スマートデバイスの普及やデジタル技術の進歩により、画像認識技術も向上しています。
画像認識アルゴリズムである「YOLO」は、リアルタイムで画像の位置と名前が推定できるディープラーニング技術として注目され続けています。画像分析の分野にパラダイムシフトを起こした革新的な技術で、すでに私たちの身近なところでも使われているのをご存じでしょうか。
当記事では、そんなYOLOを徹底解説します。その仕組みやメリット・デメリットから、Google Colaboratory上での使い方まで、余すところなくお伝えします。
完読いただくと、YOLOとストリーミングカメラで、いろいろ作ってみたくなるかも…ぜひ、最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
「YOLO」とは?何の略?

YOLOは、画像や動画に映っている物体を高速で検出できる高性能の画像認識アルゴリズムです。YOLOという名称は「You Only Live Once (人生一度きり)」という英文を「You Only Look Once(一度だけ見る)」に変えて頭文字を並べたものです。
人間のように入力画像から一度の処理で物体認識できることを端的に表した言葉であり、2015年にワシントン大学のJoseph Redmon氏らによってYOLOに関する最初の論文が発表されました。※1
このYOLOは現役の手法で「物体検出の代表格」といっても過言ではありません。その主な理由は以下の特徴にあります。
- 他の手法に比べて仕組みがシンプルで処理が高速
- 入力画像から一度の処理で複数の物体を検出可能
- 検出した物体について、バウンディングボックス・クラス(物体の名前)・信頼度を出力
- 2015年登場の初代v1から現行版までバージョンアップを続けている(2026年2月時点の最新版はv26)
その活用の場は小売店から農業、医療現場まで多岐に渡ります。
YOLOの開発はJoseph Redmon氏らオリジナル開発者だけでなく、複数の組織によって独自に改良が進められてきました。
アルゴリズムの基本的な概念や構造を基に、使いやすさを追求したバージョンや特定の領域の性能を高めたバージョンなど、さまざまな派生版が生まれています。


YOLOが開発された背景と物体検出技術の進化
現在、画像認識やAIによる映像解析の分野において「YOLO(You Only Look Once)」は、リアルタイム物体検出を代表する技術として広く知られています。2015年に登場して以来、世界中のエンジニアや研究者たちが改良を重ねてYOLOは進化を続けており、今やリアルタイム物体検出の「代名詞」となりました。
ここではYOLOが登場するまでの画像認識認識技術における背景と、なぜYOLOが物体検出の世界を大きく変えたのかをご紹介します。
YOLO以前の物体検出技術が抱えていた課題とは
YOLOが登場する前、物体検出は主に「画像の中から物体らしい領域をしらみつぶしに探す」という方法をとっていました。ただ、この方法はある精度が高いものの処理の流れが非常に複雑でした。
手順としては、まず画像の中から「物体がありそうな場所」を複数抽出し、その候補領域を1つずつニューラルネットワークに通して分類します。つまり、1枚の画像を分析するために、同じ処理を何度も繰り返す必要がありました。
単純な画像分析や研究用途としては問題ありませんでしたが、実用化の面では非常に大きな壁となったのです。
YOLOの登場とリアルタイム処理への進化
前述の通り、従来の物体検出は「まず物体候補を探し、その後で分類する」という二段階構造を繰り返し行うものでした。
一方でYOLOは、「画像全体を一度に見て、どこに何があるかを同時に予測する」という全く異なるアプローチを採用しました。この思想が「You Only Look Once(画像を一度だけ見る)」という名前の由来です。
この発想によって、処理の回数が劇的に減少しました。結果として物体検出は初めて「リアルタイム処理が可能な技術」へと進化したのです。
しかし、初期のYOLOv1は速度面では画期的でしたが、精度面ではまだまだ低く改善の余地がありました。その後、精度の低さを克服したv2、そして特徴抽出能力を大幅に強化したv3が登場するなど、凄まじいスピードで物体検出技術は進化してきました。
近年のYOLOは、研究用途だけでなく実務で使うことを前提に設計されています。例えば、YOLO26はエッジデバイスでのリアルタイム物体検出に最適化されたモデルであり、NMSの排除やDFLの削除、CPU推論の高速化など、実用性と効率性を重視した設計が特徴です。
YOLOの仕組みと他の手法との違い
YOLOの処理速度は、他の物体検出の手法と比べてはるかに高速です。その秘訣は、YOLOに採用された革新的な仕組みにあります。まず、YOLO以前の物体検出では以下の手法が主に用いられていました。
- スライディングウィンドウ法:フレームを画像の端から端まで徐々にスライドさせて物体のある場所を探し出す。その後、別のAIモデルで物体を識別する。(※2)
- 領域提案法:画像を格子状に分割して物体のある場所だけを切り抜く。その後、別のAIモデルで物体を識別する。
これらの手法を用いる物体検出アルゴリズムでは、まず物体を検出した後、別のAIモデルで物体を識別するという2つのステップを踏む必要がありました。
YOLOでは物体の検出から識別までを1つの畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)が担います。YOLOでの物体検出の流れは以下の通りです。
- 画像を格子状(グリッドセル)に分割
- 物体の場所・名前を予測
- バウンディングボックスの候補を列挙&物体が存在する確率を算出
- 同時にクラス(物体の名前)が合っている確率も算出
- 物体が存在する確率とクラスが合っている確率を掛け合わせた「信頼度」を含めて出力
以上の流れをすべて1つのモデルで完結させてしまうため、処理速度が高速になります。この特徴により、YOLOによる高精度なリアルタイム物体検出が可能になっています。。
なお、画像認識全般について詳しく知りたい方は、下記の記事を合わせてご確認ください。

YOLOのメリット
1つのAIモデルで物体の検出から識別までをこなすYOLOには、下記4点のメリットがあります。
- 高速な処理能力:リアルタイムでの物体検出が可能
- 高精度:誤検出が低い
- 実装が容易
- 一般化が可能
以下、それぞれについて詳しくみていきましょう!
高度な処理能力:リアルタイムでの物体検出が可能
画像を小分けにして1つのAIモデルで素早く処理を行うYOLOなら、リアルタイムでの物体検出が行えます。
そのため、従来の手法では難しかったストリーミングカメラとの連携が実現。各種監視カメラや自動車のADAS(先進運転支援システム)への組み込みが可能となっています。
高精度
従来の手法と異なり、YOLOでは背景も含めて包括的に画像を分析します。そのため物体検出・識別の精度が大幅UP。あらゆる用途での使い勝手が向上しています。
導入が容易
個人から企業まで、誰でも簡単に導入・利用できるのもYOLOの強みです。
YOLOはオープンソースソフトウェアであり、完全無料で使用可能。さらに全バージョンで「AGPL-3.0ライセンス」を採用しているため、下表のとおり商用利用まで自由にできてしまいます。
| 利用用途 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 | |
| 配布 | |
| 特許使用 | |
| 私的利用 | |
また「pip install」で使えるPython用のライブラリも出ており、以下についても簡単に準備できます。
- トレーニング済みのYOLOモデルの利用
- YOLOモデルのカスタマイズ
- YOLOモデルを使った物体検出システムの構築
一般化が可能
ディープラーニングモデルを採用したYOLOは、物体の特徴まで捉えます。そのため、学習範囲外の物体に対しても検出・識別(一般化)も可能です。具体的には次のようなことができます。
- 本物の花の画像を学習させた状態で、花のイラストを識別させる
- 学習範囲外のニホンアナグマを識別させる(後述)
なお、画像認識が可能なAIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

YOLOのデメリット

高精度で高速な物体検出が可能なYOLOですが、デメリットも存在します。
- 密集した複数物体の同時識別が苦手
- 小さい物体の検出が苦手
現状ではYOLOも万能なアルゴリズムではないため、苦手な要素を十分に理解した上で利用することが大切です。それぞれ詳しくみていきましょう!
密集した物体の同時識別が苦手
YOLOは密集した複数の物体を同時に検出・識別することが苦手です。その原因は、画像を細かい区画(グリッドセル)に分けてから分析する仕組みにあります。開発当初のYOLOには以下の制約がありました。
- 分割した1区画内で、検出できる物体の数は2つまで
- 分割した1区画内で、名前を識別できる物体の数は1つまで
現在のYOLOは上記のような制約はなく、大きさや形の異なる複数の区画を重ねて予測したり、異なる解像度の特徴マップを組み合わせたりすることで、密集した物体も1つずつ正確に捉えられるようになっています。
ただ、物体同士が極端に重なり合っている場合などは、依然として個々の物体を正確に分離して認識するのが難しいという課題が残っています。YOLOで正確に密集した物体を識別するには、縮尺を変えたり、物体同士の密度を下げたりなどの工夫が必要です。
小さい物体の検出が苦手
YOLOは小さい物体の検出精度も低いと言われています。こちらは高解像度の画像を用意したり、画像を拡大したりすると精度向上が期待できるでしょう。
YOLOによる物体検出をPythonで実践!
YOLOの事態を理解するには、自分で操作して体験することが重要です。
今回は無料で利用可能なGoogle Colaboratoryを用いて、YOLOによる物体検出の具体的なやり方を分かりやすく解説します。それでは早速、物体検出のための準備から始めましょう!
下準備:Google ColaboratoryとYOLOの実行環境構築
今回は、Google Colaboratory上でYOLOの最新版「YOLO26」を動かします。まず、YOLOの実行に必要な環境・ライブラリを準備します。
自分のGoogleアカウントにログインした後、Google Colaboratoryにアクセスします。「ノートブックを開く」から「ノートブックを新規作成」を選択します。

今回はトレーニング済みのYOLOモデルが使えるオールインワンのPythonライブラリ「Ultralytics」を利用してみましょう。以下のコマンドを入力して実行してください。!pip install ultralytics
実行後、以下のような画面になれば、インストール成功です。メッセージの下部に「Successfully Installed ultralytics-(version名)」が表示されています。

Ultralyticsライブラリをインストールした後はYOLOモデルのインポートです。今回はすぐに使えるトレーニング済み(pretrained)の最新版「YOLOv10」を使います。以下のコードを実行してください。
#YOLOv26-Nをロード
from ultralytics import YOLO
model = YOLO("yolov26n.pt")この状態になれば、YOLOが使えるようになります。
最後に、物体検出させたい画像をGoogle Colabにアップロードします。こちらは「content」ディレクトリ内に新しくファイルを作って画像を格納しておくと、後のコーディングが楽です。今回は……
このように「images」という名前でフォルダを作ってみました!
それでは次項から、YOLOでの物体検出を試していきましょう。
物体検出
ここからは、実際にYOLOを使って物体検出を試していきます。手始めに、物体検出用のソースコードを下記の関数にまとめて、使いやすくしましょう!
#画像フォルダをカレントディレクトリに指定
%cd images
#YOLOの一連コードを関数化
def detect_objects_in_image(model, image_path):
results = model(image_path)
return resultsあとは、下記のソースコードを実行するだけで結果が得られます。
#画像の読み込み
image_path = '画像ファイル名.jpg'
results = detect_objects_in_image(model, image_path)ここからさらに、バウンディングボックス・クラス(物体の名前)・信頼度を画像上に表示させたい場合は……
#バウンディングボックスの表示
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
def visualize_results(image_path, results):
img = cv2.imread(image_path)
for r in results:
boxes = r.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(img, f"{r.names[int(box.cls.item())]}", (int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0,255,0), 2)
cv2.putText(img, f"{box.conf}", (int(x1)+300, int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0,255,0), 2)
cv2_imshow(img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 使用例
visualize_results(image_path, results)以上を付け加えることで準備完了です。それでは早速、下記の画像3枚でYOLOの実力をみていきましょう!



まずは、1枚目「猫がお腹を見せて寝そべっている写真」をYOLOに読み込ませてみます。その結果は……

YOLOの結果
image 1/1 /content/images/yolo-s1.jpg: 640x480 1 cat, 479.0ms
Speed: 28.8ms preprocess, 479.0ms inference, 6.7ms postprocess per image at shape (1, 3, 640, 480)以上のとおりで、猫の検出・識別に成功しました。ただ、猫を「犬」としてもカウントしていたり、落ち葉を「フリスビー」と誤認していたりと細かな粗も目立ちます。このあたりは、さらなるトレーニングが必要ですね。
さて、気を取り直して2枚目「ニホンアナグマの写真」もYOLOに読み込んでもらいましょう!YOLOv10はニホンアナグマを知らないはずですが、その結果はいかに……

YOLOの結果
image 1/1 /content/images/S__58638340_0.jpg: 480x640 1 bear, 186.9ms
Speed: 3.4ms preprocess, 186.9ms inference, 0.3ms postprocess per image at shape (1, 3, 480, 640)見事、YOLOはニホンアナグマに対して、アドリブで「クマ」と識別してくれました。ディープラーニングならではの汎用性・余裕が活きていますね。
最後に、3枚目「ソファーの上で猫が寝そべっている写真」でも、YOLOの実力を試してみます。気になる結果は……
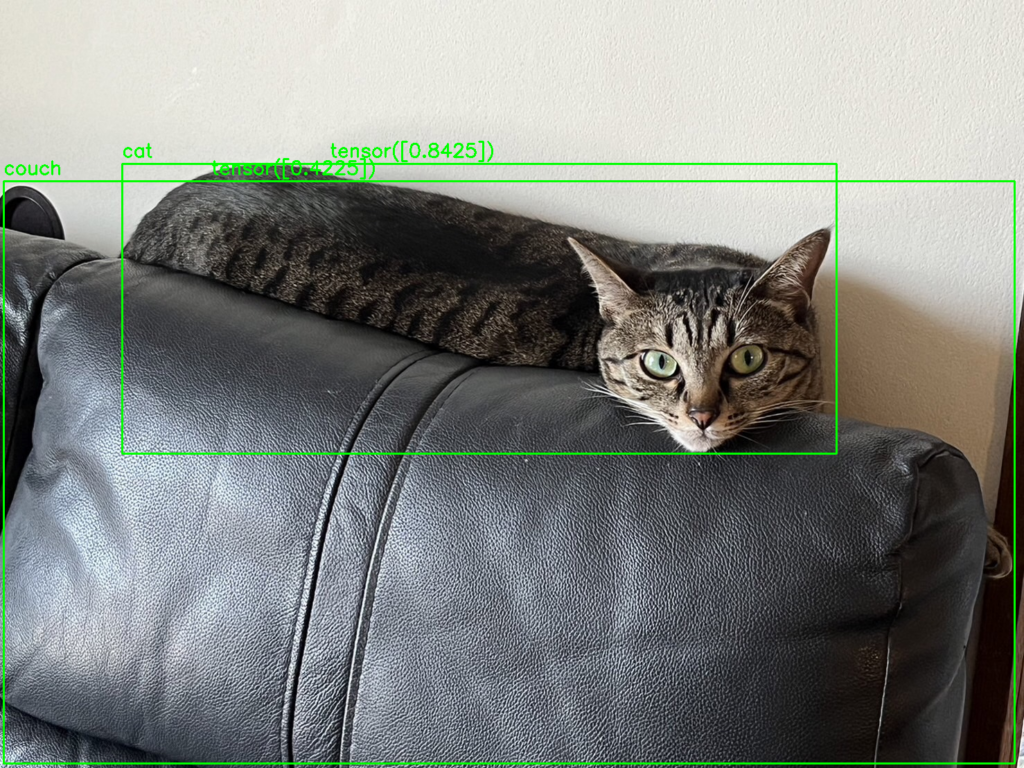
YOLOの結果
image 1/1 /content/images/S__58638346_0.jpg: 480x640 1 cat, 1 couch, 183.9ms
Speed: 4.2ms preprocess, 183.9ms inference, 0.3ms postprocess per image at shape (1, 3, 480, 640)お見事です!「猫」に加え、なんと「ソファー(couch)」まで検出・識別してくれています。専用のトレーニングをしていない状態でここまで識別できるとは……YOLO、恐るべしですね。


YOLOの活用・応用事例
リアルタイムで高精度な物体検出ができるYOLOは、幅広い分野での活躍が見込まれています。代表的な活用・応用事例を見てみましょう。
- 自動車の運転支援・自動運転
- 信号機の検出・色の識別(※3)
- 道路標識(停止線・ダイヤマーク)の検出・識別
- 製造ラインの異常検知
- 積層信号灯(パトランプ)の光色の検出・識別(※4)
- 牛の柄による個体識別(※5)
- 鶏の行動パターン識別(※5)
- 医療での画像診断
- エコー画像の異常所見の検出(※6)
- 人流計測
- 観光地での人流の分析(※7)
- 災害対策への応用(※7)
- 商品管理
- 商品棚の欠品の検出(※8、9)
- セキュリティ・防犯対策
- 不審人物の検出(※10)
その他、合成データを活用したトレーニングの効率化にも注目が集まっています。(※10)
工夫次第で多様な利用法があり、多くのアイデアが実現できる可能性があります。
なお、合成データについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

YOLOに関してのよくある質問
「YOLO」ならリアルタイム&高精度の物体検出が実現!
画像内に映っているものを識別するには、高度な画像処理技術が求められます。高精度かつ高速な処理が可能なYOLOは、2015年の発表以来、画像認識分野で多くの注目を集めてきました。
物体の検出から識別までを1つのAIモデルでこなすYOLOの特徴は、以下の通りです。
- リアルタイムでの物体検出が可能
- 高精度
- 導入が容易
- 一般化が可能
この特徴を活かし、製造業や小売業、農業など幅広い分野での活躍が見込まれています。比較的簡単に使えますのでぜひぜひ、一度その実力を体感してみてくださいね。

最後に
いかがだったでしょうか?
「YOLO」の可能性を理解し、生成AI活用の道を広げることで、高速かつ高精度な物体検出がもたらすビジネスチャンスを掴めるかもしれません。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。
- ※1:You Only Look Once: Unified, Real-Time Object Detection
- ※2:2章 機械学習による画像理解
- ※3:【自動運転】信号機認識に挑む / 走行画像15,000枚のアノテーションとYOLOXモデルによる深層学習実践
- ※4:ディープラーニングの産業利用の事例紹介
- ※5:YOLOの畜産分野における利用事例 修士課程1年 渠 一村
- ※6:画像診断における人工知能の応用と超音波 AI の開発
- ※7:画像認識 AI を用いた人流実測および車流実測技術
- ※8:棚から売上へ:Ultralytics チームによるYOLOv8 「在庫管理への影響」の探求
- ※9:疑似的に生成した商品棚画像を用いた商品物体検出
- ※10:セキュリティアラームシステム・プロジェクトUltralytics YOLOv8

【監修者】田村 洋樹
株式会社WEELの代表取締役として、AI導入支援や生成AIを活用した業務改革を中心に、アドバイザリー・プロジェクトマネジメント・講演活動など多面的な立場で企業を支援している。
これまでに累計25社以上のAIアドバイザリーを担当し、企業向けセミナーや大学講義を通じて、のべ10,000人を超える受講者に対して実践的な知見を提供。上場企業や国立大学などでの登壇実績も多く、日本HP主催「HP Future Ready AI Conference 2024」や、インテル主催「Intel Connection Japan 2024」など、業界を代表するカンファレンスにも登壇している。

