

- 2026年2月25日にAlibaba Qwenチームが公開、35B-A3B・122B-A10B・27Bの3モデルをApache-2.0ライセンスで提供
- Gated Delta Networks + Sparse MoEのハイブリッドアーキテクチャを採用し、アクティブパラメータに対して高い性能効率を達成
- 262,144トークンのネイティブコンテキスト長に対応し、最大1,010,000トークンまで拡張可能
2026年2月25日、Alibaba QwenチームはQwen 3の後継となるQwen 3.5 Mediumシリーズを公開しました。
Gated Delta Networksという独自のハイブリッドアーキテクチャにより、総パラメータ122Bのモデルでもアクティブパラメータはわずか10Bという高い効率を実現しています。
Apache-2.0ライセンスで公開されているため、商用利用も可能です。この記事では、Qwen 3.5 Mediumの仕組みから特徴、料金、実装方法、活用シーンまでくわしく解説します。
\生成AIを活用して業務プロセスを自動化/
Qwen 3.5 Mediumとは

Qwen 3.5 Mediumは、Alibaba CloudのQwenチームが2026年2月25日に公開したLLM(大規模言語モデル)シリーズです。
Qwen 3.5ファミリーのうち、中規模帯に位置するモデル群として、3つのバリエーションが用意されています。フラッグシップの397B-A17Bとは異なり、より少ない計算リソースで動作することを目指して設計されました
モデル一覧
Qwen 3.5 Mediumシリーズは、用途や計算リソースに合わせて選べる3つのモデルとホスト版で構成されています。
| モデル名 | 総パラメータ | アクティブパラメータ | アーキテクチャ | レイヤー数 |
|---|---|---|---|---|
| Qwen3.5-35B-A3B | 35B | 3B | MoE | 40 |
| Qwen3.5-122B-A10B | 122B | 10B | MoE | 48 |
| Qwen3.5-27B | 27B | 27B | Dense | 64 |
| Qwen3.5-Flash | — | — | MoE(ホスト版) | — |
35B-A3BとQwen3.5-122B-A10Bの2モデルはスパースMoE(Mixture-of-Experts)アーキテクチャを採用しており、総パラメータの一部のみを推論時にアクティブにすることで計算コストをおさえています。
Qwen3.5-27Bはすべてのパラメータを使うDenseモデルで、MoEとは異なるアプローチです。Qwen3.5-FlashはAlibaba Cloud DashScope経由で利用できるホスト版で、1Mコンテキストとビルトインツール機能がデフォルトで有効化されています。
なお、同じくQwenシリーズであるQwen3-ASRは音声認識に特化したモデルです。くわしく知りたい方は、以下の記事をご覧ください。
Qwen 3.5 Mediumの仕組み
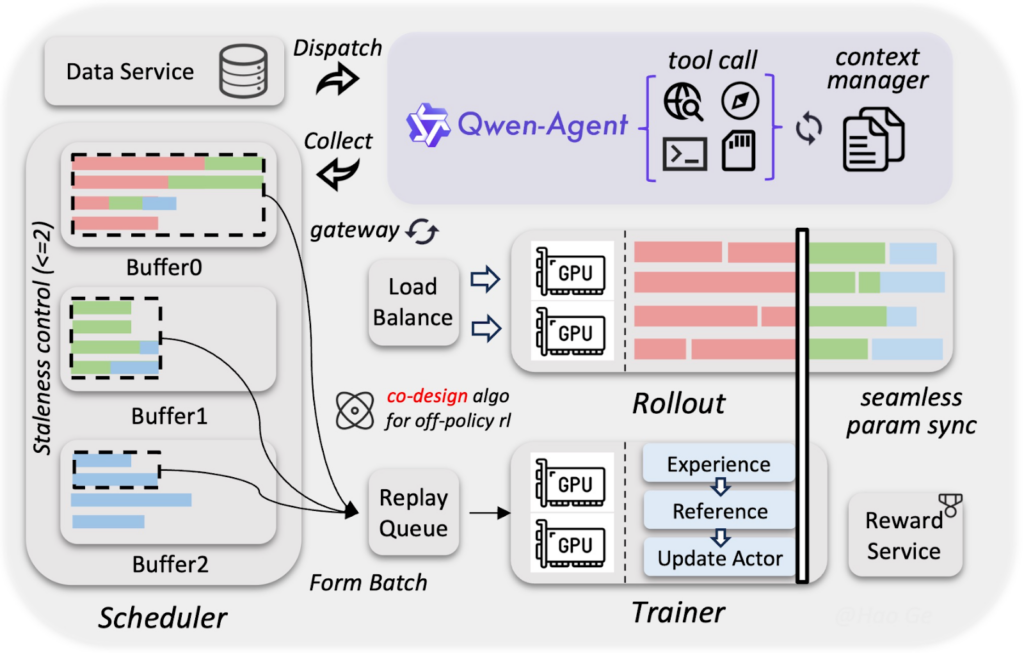
Qwen 3.5 Mediumは、Gated Delta Networks(線形注意)とGated Attention(ソフトマックス注意)を組み合わせたハイブリッドアーキテクチャを採用しています。これまでのTransformerがすべてのレイヤーで正規化していたのに対し、今回のモデルでは多くのレイヤーを線形注意で処理し、一定間隔で正規化を挟む構成になっています。
この設計により、推論コストをおさえつつ高い性能を維持することを目指しています。
Gated Delta Networksとは
Gated Delta Networksは、文章が長くなっても処理が重くなりにくく、遠い文脈まで扱える仕組みです。
一般的な仕組みでは、過去のどこが大事かを広く見回して確かめるため、文章が長いほど計算が増えて遅くなりがちです。一方で、Gated Delta Networksは、トークンを順番に読みながら内部のメモを更新し、必要な情報だけを要約して保持していきます。
その結果、26万トークン級の長いコンテキストでも、推論速度の落ち込みを小さく抑えられます。覚えておく情報と捨てる情報を状況に応じて切り替えているため、大事な文脈を落としにくくなっています。
ハイブリッドレイアウト
Qwen 3.5 Mediumの構成は、3つの線形注意レイヤー+1つのソフトマックス注意レイヤーを繰り返すパターンです。
ソフトマックス注意とは、必要な情報を過去の全体から広く見渡して探し、重要そうな部分に強く注目して取り出すタイプの注意です。精度の高い検索ができる一方で、文章が長いほど処理が重くなりやすい特徴があります。
一方の線形注意は、内部の状態を更新しながら必要な情報をためていく方式で、長い文章でも処理が重くなりにくいのが強みです。
そのためQwen 3.5 Mediumでは、線形注意を3回続けて軽く処理しつつ、一定間隔でソフトマックス注意を挟んで精度を補っています。結果として、重さを抑えながら性能も落としにくいというバランスになっています。
スパースMoE(Mixture-of-Experts)
スパースMoE(Mixture-of-Experts)とは、モデルの中に多くの専門家(エキスパート)を用意しておき、入力に合った一部だけを選んで使う仕組みです。
| 項目 | Qwen3.5-35B-A3B | Qwen3.5-122B-A10B |
|---|---|---|
| 総エキスパート数 | 256 | 256 |
| ルーティングエキスパート | 8 | 8 |
| 共有エキスパート | 1 | 1 |
| Hidden size | 2048 | 3072 |
| Expert dim | 512 | 1024 |
ルーターネットワークが入力トークンごとに最適なエキスパート8個を選択し、残りの248個は推論に参加しません。この仕組みにより、モデルの知識容量は総パラメータ分を維持しつつ、実際の計算コストは抑えられます。


Qwen 3.5 Mediumの特徴
Qwen 3.5 Mediumには、アクティブパラメータに対する高い性能効率、100万トークン超のロングコンテキスト、そして多言語対応という3つの強みがあります。
MoEアーキテクチャとGated Delta Networksの組み合わせにより、同規模のモデルと比べて高い処理能力を持ちます。
ベンチマーク性能
Qwen3.5-122B-A10Bは、アクティブパラメータ10Bでありながら、GPQA Diamondで86.6という高スコアを記録しています。これは同規模のDenseモデルと比較して圧倒的な効率です。
| ベンチマーク | Qwen3.5-35B-A3B | Qwen3.5-122B-A10B |
|---|---|---|
| MMLU-Pro | 79.1 | 86.7 |
| GPQA Diamond | 73.8 | 86.6 |
| SWE-bench Verified | 72.0 | 72.4 |
| LiveCodeBench v6 | 63.2 | 79.1 |
注目すべきは、Qwen3.5-35B-A3Bがわずか3BのアクティブパラメータでSWE-bench Verifiedで72.0を達成している点です。これはソフトウェアエンジニアリングタスクにおいて、大きなモデルに迫る性能を持つことを示しています。
100万トークン超のコンテキスト長
通常で26万トークン、拡張設定で最大100万トークンのコンテキストに対応します。これは書籍数冊分に相当する分量であり、大規模なコードベースの解析や長文ドキュメントの要約に使えます。
また、Qwen3.5-Flashはホスト版として1Mコンテキストがデフォルトで有効化されており、ビルトインツール機能も搭載されています。ローカルで動かす場合でも、YaRN(Yet another RoPE extensioN)を使った拡張設定により100万トークンまで対応可能です。
この長大なコンテキスト長は、Gated Delta Networksの線形計算量によって効率的に実現されています。
マルチモーダル基盤
公式ブログでは、Qwen 3.5全体の設計方針として「Unified Vision-Language Foundation」を掲げています。テキストと画像を別々の仕組みで扱うのではなく、最初から同じ土台で一体として学習させるという考え方です。
テキストと画像を統一したアーキテクチャで学習するEarly Fusionのアプローチにより、ほぼ100%のマルチモーダル学習効率を達成したと報告されています。
ただし、Mediumシリーズとして公開されているのはテキストモデルであり、マルチモーダル対応版はQwen3-VLやQwen3-Omniが担っています。
なお、マルチモーダルエージェントAIモデルとしてはMoonshot AIのKimi K2.5も注目されています。くわしく知りたい方は、以下の記事をご覧ください。

Qwen 3.5 Mediumの安全性・制約
Qwen 3.5 Mediumを利用するうえでは、モデルの安全性対策と技術的な制約の両方を理解しておくことが大切です。
自由度が高い反面、モデルの重みを直接操作できる環境では想定外の使われ方もありえます。AIを業務で導入や運用する際のリスク管理として、ぜひ参考にしてください。
安全性対策
Qwen 3.5シリーズは全体にわたるスケーラブルな強化学習を実施しています。安全性に関する学習データやRLHF(人間のフィードバックによる強化学習)のプロセスにより、有害なコンテンツの出力を抑制する仕組みが組み込まれています。
ただし、Apache-2.0ライセンスのオープンウェイトモデルであるため、モデルの重みを直接操作できる環境では安全性のガードレールが機能しない可能性があります。
企業で導入する際は、アプリケーション層で独自のフィルタリングや入力検証を追加することが推奨されます。
技術的な制約
2026年2月25日時点では、Qwen 3.5 Mediumはテキスト入出力専用です。画像や音声の入出力には対応していません。
| 制約項目 | 内容 |
|---|---|
| 入出力 | テキストのみ(マルチモーダル非対応) |
| コンテキスト上限 | 26万トークン〜100万トークン(拡張時) |
| MoEモデルのVRAM | 総パラメータ数分のモデルロードが必要 |
| 学習データカットオフ | 非公開 |
MoEモデルは推論時のアクティブパラメータは少ないですが、モデルファイルのロードには総パラメータ分のVRAMが必要です。
たとえばQwen3.5-122B-A10Bをフル精度で読み込むには、少なくとも240GB以上のVRAMが求められます。量子化を活用すれば必要VRAMを削減できますが、性能への影響をチェックする必要があります。
Qwen 3.5 Medium利用時の制約
オープンウェイトモデルとして公開されているため、利用自体への制限は少ないのが特徴です。ただし、いくつかの点で注意が必要です。
Hugging Faceからモデルの重みをダウンロードし、対応する推論フレームワーク上で自由に利用できます。API経由で使う場合は、Alibaba Cloud DashScopeのアカウントが必要です。
ホスト版のQwen3.5-Flashについては、DashScopeの利用規約に従う必要があります。商用利用は可能ですが、出力コンテンツの品質と安全性については利用者側の責任となる点に気をつけてください。
Qwen 3.5 Mediumの料金
オープンウェイトモデルはApache-2.0ライセンスで無料公開されており、商用利用にも料金はかかりません。ダウンロードして自社環境にデプロイすれば、追加の利用料金は発生しません。
クローズドなAPIサービスとは異なり、月額課金やトークン単価の負担なしに使えるのが大きなメリットといえます。ただし、GPUサーバーの調達・運用費や、API経由での利用料金は別途かかるため、用途に応じたコスト計算が必要です。
ローカル利用
Hugging Faceからモデルをダウンロードし、自社のGPU サーバー上で動かす場合はモデル利用料が無料です。ハードウェアコスト(GPUサーバーの調達・運用)が主な費用になります。
クラウドGPUサービス(AWS、GCP、Azureなど)を使う場合はインスタンスの時間課金が発生しますが、モデル自体のライセンス費はかかりません。プロトタイピングや検証用途であれば、コストをおさえながら機能評価ができます。
API利用(Qwen3.5-Flash)
Alibaba CloudのDashScopeを通じてAPI経由で利用する場合は、DashScopeの従量課金が適用されます。
Qwen3.5-Flashは1Mコンテキストとビルトインツール機能がデフォルトで有効化されたホスト版として提供されています。ローカル環境の構築が難しい場合や、まずは手軽に試したい場合に適しています。
Qwen 3.5 Mediumのライセンス
3モデルすべてがApache-2.0ライセンスで公開されています。商用利用、改変、再配布が許可されており、ファインチューニングして自社サービスに組み込むことも可能です。
Apache-2.0は、特許権の付与や貢献者からの特許ライセンスを含むとても寛容なライセンスです。Hugging Faceの各モデルカードにもライセンス表記が記載されています。
Qwen 3.5 Mediumの実装方法
Qwen 3.5 Mediumは、主要な推論フレームワークに対応しており、導入の選択肢が豊富です。本番環境での高スループットなサービングから、ローカルでの実験的な利用まで、用途に応じた環境構築ができます。
ここでは動作環境とHugging Face Transformersでの具体的な環境構築の手順とサンプルコード例を紹介します。
動作環境・前提条件
| 項目 | 内容 |
|---|---|
| 対応フレームワーク | Hugging Face Transformers SGLang vLLM KTransformers |
| 推奨GPU(35B-A3B) | NVIDIA A100 40GB × 1枚以上(量子化時) |
| 推奨GPU(122B-A10B) | NVIDIA A100 80GB × 4枚以上 |
| 推奨GPU(27B Dense) | NVIDIA A100 40GB × 1枚以上 |
| Python | 3.10以上推奨 |
Qwen 3.5 Mediumを動かすための前提条件を以下にまとめました。モデルのサイズごとに必要なGPUが異なるため、導入前にかならず自社のハードウェア構成と照らし合わせてください。
Hugging Face Transformersでの利用

Hugging Face Transformersではモデル名を切り替えるだけで、35B-A3B、122B-A10B、27Bのいずれも同じコードで利用できます。
初回実行時にはモデルのダウンロードが発生するため、ネットワーク環境には余裕を持たせておきましょう。
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3.5-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
messages = [
{"role": "user", "content": "Qwen 3.5 Mediumの特徴を教えてください"}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)device_map=”auto”を指定することで、利用可能なGPUに自動的にモデルが配置されます。torch_dtype=”auto”はモデルカードに記載されたデフォルトのデータ型を使用します。
【業界別】Qwen 3.5 Mediumの活用シーン
Qwen 3.5 Mediumは、オープンウェイトかつ高いコスト効率を持つLLMとして、さまざまな業界での導入が見込まれます。特にApache-2.0ライセンスで自社環境にデプロイできる点が、データセキュリティの要件が厳しい業界にとって大きな魅力です。
ファインチューニングも自由に行えるため、業界固有のデータでカスタマイズして活用することもできます。ここでは、代表的な業界ごとの具体的な導入ユースケースを紹介します。
ソフトウェア開発
コードの生成やレビュー、バグ修正といった開発タスクにQwen 3.5 Mediumは強みを発揮します。SWE-bench Verifiedで72.0〜72.4というスコアは、実際のソフトウェアエンジニアリングタスクでの高い実用性を示しています。
262Kトークンのコンテキスト長により、大規模なコードベースを一度に入力してコードレビューや脆弱性チェックができます。Qwen3-Coderとあわせて利用することで、コーディング支援のカバー範囲をさらに広げられるでしょう。
なお、生成AIを活用したシステム開発に興味がある方は、下記の記事を参考にしてください。

金融・法務
規制文書の分析や契約書レビューにおいて、ロングコンテキストの強みが活きます。
数百ページにおよぶ法令文書や契約書を一度に読み込んで要約や比較分析できる点は、法務部門の業務効率化に直結します。特に金融分野では規制変更が頻繁に発生するため、素早い文書解析はビジネス上の重要課題です。
オープンウェイトモデルを自社環境にデプロイすれば、機密性の高い文書データを外部に送信する必要がありません。金融機関のコンプライアンス要件を満たしながら、AI活用を進められます。
なお、金融や法務分野における生成AIを活用した業務効率化については、下記の記事を参考にしてください。
金融はこちら

法務はこちら

研究・教育
論文要約や多言語翻訳、学習教材の生成にも適しています。201言語対応により、多言語環境での研究活動をサポートできます。
国際的な共同研究にも活かせるでしょう。MoEアーキテクチャにより比較的少ないGPUリソースで動作するため、大学の研究室レベルのリソースでも実験できます。
オープンウェイトであるため、モデルの内部構造を解析したり、特定ドメイン向けにファインチューニングしたりといった研究用途にも向いています。
なお、生成AIを活用した教育業界の業務効率化については下記の記事を参考にしてください。

カスタマーサポート
Qwen-Agentフレームワークと組み合わせれば、外部ツールを呼び出しながら顧客の質問に回答するAIエージェントを構築できます。
Qwen Chatでの利用実績を踏まえ、対話の品質にも信頼性があります。ロングコンテキストに対応しているため、過去の対話履歴を踏まえた回答も生成できます。
カスタマーサポートで大活躍するAIチャットボットについては下記の記事を参考にしてください。

また、Qwen3-Omni-Flashを利用すれば、自然な音声をリアルタイムに出力できるため、さらに便利なカスタマーサポートの仕組みを構築できるかもしれません。くわしく知りたい方は、ぜひ以下の記事をご覧ください。

【課題別】Qwen 3.5 Mediumが解決できること
Qwen 3.5 Mediumは、企業がAI導入時に直面する代表的な課題に対して解決策を提供します。コスト、セキュリティ、カスタマイズ性といったハードルを、オープンウェイト×MoEアーキテクチャの組み合わせで乗り越える方法を整理しました。
推論コストを大幅にカットできる
高性能なLLMほどパラメータ数が大きく、推論にかかるGPUコストが膨らむのが悩みどころです。Qwen 3.5 MediumはMoEアーキテクチャにより、総パラメータ122Bのモデルでもアクティブパラメータをわずか10Bに限定して計算コストを削減できます。
機密データを外部に送信せずにAIを使える
クラウドAPIにデータを送ることへの懸念から、AI導入を見送っている企業は少なくありません。Qwen 3.5 Mediumはオープンウェイトでオンプレミス環境にデプロイできるため、社内データを外部に一切送信せずにLLMを活用できます。
自社ドメインに特化したモデルを構築できる
汎用モデルでは自社業界の専門用語や業務フローに対応しきれないことがあります。Apache-2.0ライセンスのため、ファインチューニングやカスタマイズが自由に行えるので、自社固有のデータで学習させた専用モデルを構築できます。
グローバル展開にも対応できる多言語サポート
海外拠点との連携や多言語コンテンツの制作には、幅広い言語対応が欠かせません。Qwen 3.5 Mediumは201言語をサポートしており、日本語はもちろん、英語・中国語を含むグローバルな言語環境に一つのモデルで対応できます。
Qwen 3.5 Mediumの活用事例
— Qwen (@Alibaba_Qwen) February 24, 2026
Introducing the Qwen 3.5 Medium Model Series
Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27BMore intelligence, less compute.
• Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality,… pic.twitter.com/ZWPibMn6at
Qwenチームの公式アカウントによるX上の発表は大きな反響を呼びました。特にMoEアーキテクチャによるアクティブパラメータの少なさと高いベンチマークスコアの両立に注目が集まっています。
ここでは開発者コミュニティの期待と初期評価を紹介します。
ファインチューニングでさらに向上
Qwen 3の0.6Bモデルをファインチューニングしたところ、分類タスクで83.5%の精度を達成したと報告しています。この数値はGemini 2.5 Proの85%に次ぐもので、わずか0.6Bのモデルがトップクラスの大規模モデルに迫る性能を出せることを示しました。
M3 Ultra上でリアルタイム動作する様子も公開されており、Qwenシリーズのファインチューニング適性の高さが実証されています。
HuggingChatで簡単に実行が可能
Qwen 3.5 is available on HuggingChat
— Victor M (@victormustar) February 17, 2026
Warning: it's epic – working extremely well. pic.twitter.com/hKRQH4yNRE

HuggingChatでQwen 3.5が利用可能になったことも話題を呼んでいます。HuggingChat上でQwen 3.5を試した結果「epic(最高)」と評価し、Three.jsを使って魚が泳ぐ3Dアニメーション動画を生成する様子を公開しました。
コーディングタスクでの実用的な出力品質の高さが確認できる事例であり、ブラウザだけで手軽にQwen 3.5の実力を体験できる点も注目されています。ローカル環境を構築しなくても、HuggingChat経由ですぐに試せるのは導入検討の第一歩として便利です。
Qwen 3.5 Mediumを実際に使ってみた
今回はHuggingChatを使って、Qwen 3.5の実力を試してみました。HuggingChatではフラッグシップのQwen3.5-397B-A17Bが無料で利用可能で、ブラウザからすぐにアクセスできます。
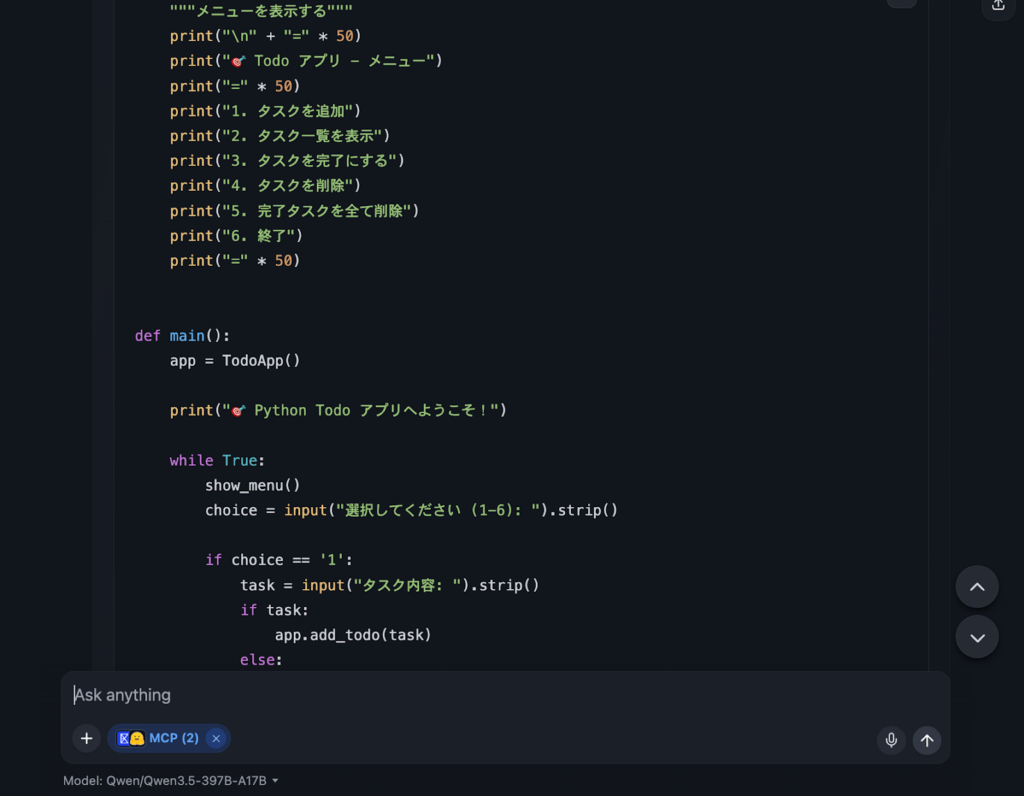
試しに日本語で「Pythonで簡単なTodoアプリのコードを書いてください」と指示したところ、Flaskを使った完成度の高いコードが即座に返ってきました。
コメントも日本語で丁寧に付与されており、日本語での指示理解とコード生成の品質はかなり高いと感じました。また、生成スピードも早く、推論時間がほとんどなく生成がされて驚きました。

次に、「Canvas APIでパーティクルアニメーションを作って」と指示すると、滑らかに動くアニメーションが表示されました。サイズやスピード、色なども選ぶこともできます。日本語の簡単な指示からここまで完成度の高いコードを一発で出せるのは、コーディング性能の高さを感じます。
よくある質問
まとめ
Qwen 3.5 Mediumは、Gated Delta Networks + Sparse MoEのハイブリッドアーキテクチャにより、アクティブパラメータに対する性能効率で新たな水準に達したモデルです。
35B-A3B、122B-A10B、27Bの3モデルがApache-2.0ライセンスで公開されており、商用利用を含めた幅広い用途に対応します。262Kトークンのネイティブコンテキスト長や201言語対応など、実用面での強みも充実しています。
推論コストの削減とデータセキュリティの確保を両立したい企業にとって、有力な選択肢となるでしょう。今後のマルチモーダル対応やファインチューニング済みモデルの展開にも注目です。

最後に
いかがだったでしょうか?
Qwen 3.5 Mediumを自社環境でどう活かすか。弊社のサポートなら、導入判断を一気に整理できます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

