

- Wan2.1は、オープンソースで高性能な動画生成AIとして、Text-to-Video・Image-to-Video・編集まで幅広く対応
- プロンプト拡張機能により、短い指示でも映像品質と安定性を大きく向上
- ローカル実行からAPI・ComfyUIまで用途と環境に応じた柔軟な使い分けが可能
2025年2月25日、中国のAlibaba Cloudが、大規模マルチモーダルAIモデルシリーズの最新版「Wan2.1」を公開しました!
— Wan (@Alibaba_Wan) February 25, 2025
Announcing Wan2.1 – The Next Evolution in AI Video Generation!
We're thrilled to open-source our cutting-edge video generation suite!#AIart #OpenSource
「Wan2.1」はオープンソースでリリースされており、テキストや画像から高品質な動画を生成できるよう設計されているようです。また、VBenchで総合スコア86.22%と高い評価を記録し、SoraやLuma、Pikaを大きく上回る性能を持つとのこと。
本記事では、そんな「Wan2.1」の概要から使い方までご説明します。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Wan2.1の概要
Wan2.1は、最先端の拡散モデル(DIT:Denoising Diffusion Transformer)と独自開発のVAEを組み合わせ、複雑な動きや空間関係、物理法則の再現に優れたリアルな動画生成を実現しています。
特に、時間軸を捉えるのに優れており、実際の動きを精密に模倣することが可能な仕組みになっています。
また、Wan2.1はマルチモーダル対応モデルであり、「Text-to-Video」だけでなく、「Image-to-Video」、「既存動画の編集」、「テキストから画像生成」、「動画からオーディオ生成」まで、複数のタスクに対応した包括的なモデルです。
上述の通りですが、Wan2.1は主要なオープンソースおよびクローズドソースモデルとのベンチマークテスト比較で、高い評価を得ています。

上記の表は、人間の嗜好に由来する重みを利用して、各次元のスコアに対して加重計算を行った合計スコアの結果です。
Weighted Scoreにおいて、他モデルを上回っていることが分かりますね。
さらに、「Wan2.1」のストロングポイントとして、手軽さが挙げられます。
Wan2.1の小型版モデル「T2V-1.3B」は、必要なVRAMが約8.2GBと軽量で、RTX4090クラスのGPUであれば、約4分で5秒間、480P解像度の動画を生成することができます。
加えて、Wan2.1は画像生成モデル並みの柔軟なカスタマイズ性や、テキスト入り動画生成といったユニークな機能を備えており、総合的に見て現行の他の動画生成AIとの差別化が図られています。
VBenchとWan-Benchの違い
動画生成AIの評価には主にVBenchとWan-Benchという2つのベンチマークが使用されています。
VBenchは、「動画生成品質」を16の階層的な評価次元に分解し、被写体の一貫性、動きの滑らかさ、時間的なちらつき、空間関係など、技術的品質を細かく測定します。VBenchの最大の特徴は、各評価次元が人間の知覚と高い相関性を持つよう設計されている点です。
一方、Wan-Benchは、Alibabaチームが独自に開発した評価フレームワークで、Wan2.1の技術レポートで初めて導入されました。
Wan-Benchは人間の嗜好に基づく重み付けを採用しており、各評価次元のスコアに対して人間が重要視する要素を反映した加重計算を実施。
この手法により、総合スコアが実際のユーザー体験により近い形で算出されるようになっています。
Wan2.2との違いと選び方
2025年9月にWan2.2が公開され、2026年2月現在、Wan2.1とWan2.2の両方が利用可能です。どちらを選ぶべきか迷う方も多いため、ここでは両者の違いとどちらを選ぶべきかを解説します。
Wan2.2の最大の変更点は、アーキテクチャにMixture-of-Experts(MoE)を採用したことで、生成速度が2〜3倍向上し、音声生成がネイティブ対応となった点です。また、最大解像度も720Pから1080Pへ引き上げられています。
一方で、コミュニティからは初回・最終フレームの品質についてWan2.1の方が優れているという報告もあります。
モデルラインナップの全体像
Wan2.1は、用途や環境に応じて選択できる複数のモデルを提供しています。
大きく分けてText-to-Video 、Image-to-Video、First-Last-Frame-to-Video、Video Auto-Caption Encoder の4つで、それぞれに1.3Bまたは14Bのパラメータサイズが用意されています。
T2V-1.3B / T2V-14B
T2V-1.3Bは、わずか13億パラメータという軽量設計ながら、必要VRAMが8.19GBと非常に低く抑えられており、RTX 3060やRTX 4060でも動作可能。
480P解像度の5秒動画をRTX 4090で約4分で生成でき、個人開発者や限られたリソース環境での利用に最適です。ただし、720P解像度での生成も技術的には可能ですが、学習データの制約により480Pでの利用が公式推奨されています。
一方、T2V-14Bは140億パラメータの大規模モデルで、480Pと720Pの両方に対応。より複雑な動きや高精細な表現が可能で、商用レベルの高品質動画生成に適しています。
I2V-14B(480P・720P)
Image-to-Videoは解像度別にI2V-14B-480PとI2V-14B-720Pの2つのバリエーションが用意されています。
I2V-14B-480Pは、低解像度ながら安定した動画生成が可能で、必要VRAMも比較的抑えられています。一方、I2V-14B-720Pは高解像度での動画生成に対応し、より精細な動きと画質を実現。
入力画像のアスペクト比は生成動画に引き継がれるため、ポートレートや風景など多様な構図に対応可能です。
FLF2V-14B
First-Last-Frame-to-Video (FLF2V) モデルは、動画の最初と最後のフレームを指定することで、その間の動きを補間生成するモデル。2025年4月にリリースされたFLF2V-14Bは、140億パラメータで720P解像度に対応しています。
FLF2Vの最大の特徴は、開始フレームと終了フレームの一致率が98%に達する高精度な制御性です。
これにより、シームレスなループ動画の作成や、ストーリーボードに基づいた正確なシーン遷移が可能になります。例えば、鳥が地面にいる画像と空を飛んでいる画像を指定すれば、離陸の過程を自然に補間した動画を生成できます。
VACE(1.3B / 14B)
Video Auto-Caption Encoder (VACE) は、Wan2.1の中で最も多機能なオールインワンモデル。動画生成だけでなく、動画編集、自動キャプション生成まで対応する統合型モデルとして2025年5月に公開されました。
VACE-1.3Bは480P推奨で低VRAM環境でも動作し、VACE-14Bは480Pと720Pの両方をサポート。
通常のT2VやI2Vと異なり、VACEはテキストプロンプト、動画、マスク、参照画像などの複数入力を組み合わせた生成が可能です。
実際にVACEを使われている方がXにいらっしゃいましたが、最初と最後の画像だけを指定して、間の動きを補完してくれるようです。
【動画生成の新基準】Wan2.1 VACEが凄すぎる!
— ハカセ アイ(Ai-Hakase)
最初と最後の画像を指定するだけで、AIが間の動きを完璧に補完!高解像度720P対応で、意図通りの映像制作が驚くほど簡単に。動画編集の常識を塗り替える最強ツールです最新トレンドAIのためのX
Wan2.1のモデルをそれぞれまとめると下記のようになります。
| モデル名 | パラメータ | 解像度 | 必要VRAM目安 | 主なタスク | 推奨環境 |
|---|---|---|---|---|---|
| T2V-1.3B | 13億 | 480P推奨 | 8.19GB | テキストから動画生成 | 個人開発・低VRAM |
| T2V-14B | 140億 | 480P/720P | 24GB+ | テキストから動画生成 | 商用・高品質制作 |
| I2V-14B-480P | 140億 | 480P | 16GB+ | 画像から動画生成 | 写真アニメーション |
| I2V-14B-720P | 140億 | 720P | 24GB+ | 画像から動画生成 | 高精細I2V |
| FLF2V-14B | 140億 | 720P | 24GB+ | 開始終了フレーム指定 | ループ動画・遷移 |
| VACE-1.3B | 13億 | 480P推奨 | 8GB+ | 統合編集・生成 | オールインワン低負荷 |
| VACE-14B | 140億 | 480P/720P | 24GB+ | 統合編集・生成 | プロ級編集ワークフロー |
Wan2.1の機能
では次にWan2.1の機能を詳しくみていきましょう。
Text-to-Video (T2V)
Text-to-Video (T2V) は一般的に動画生成でよく使われる、テキストプロンプトから動画を生成する機能で、Wan2.1でも中核を担う機能です。
自然言語で入力されたテキストプロンプトをもとに、その内容に沿った映像を生成することが可能です。
たとえば「猫がピアノを弾いている」や「未来都市を飛び回るドローン」といった指示を与えるだけで、意味を解釈してアニメーション動画を作成することができます。
Image-to-Video (I2V)
1枚の静止画をもとに、その画像に動きを加えた動画を生成できるのがImage-to-Video(I2V)です。
たとえば、風景写真を入力すれば、空が流れたり人物が歩き出すようなモーションが加わった映像が生成されます。
Video Editing
Wan2.1は入力された動画に対して「編集」を加える機能が搭載されています。
具体的には、入力した動画の一部だけを変更したり、スタイルを変えたりエフェクトを追加するといった処理が可能です。単なる動画生成だけでなく、素材の加工や再構成ができるようになっています。
Text-to-Image
動画だけでなく、テキストから静止画(画像)を生成する機能も搭載しています。
これにより、まずテキストプロンプトで画像を作り、それを元に動画を生成させるという2段階構成の制作も可能になりました。
Video-to-Audio
Wan2.1では、生成した動画や入力された動画から、そのシーンにマッチする効果音などを自動生成する機能も搭載されています。
これにより、無音の動画にリアルな効果音を付ける作業を自動化できるようになりました。
ただ、BGM(音楽)というよりも効果音・環境音というイメージが強いようなので、現時点ではしっかりBGMをつけたいなら別途動画とBGMを合わせる方がよいでしょう。
テキスト生成
英語と中国語に限られますが、Wan2.1は動画生成時にテキストも追加することが可能です。
動画の中にキャッチコピーを入れたり、字幕を出すことができるので動画とテキストが一体化した
作品を一度の生成プロセスで作れるようになりました。
プロンプト拡張について
Wan2.1では、入力したプロンプトを自動的に詳細化・拡張するプロンプト拡張(Prompt Extension)機能があります。プロンプト拡張は、シンプルなプロンプトから生成される動画の品質を大幅に向上させることが可能。
例えば「猫がピアノを弾く」という短いプロンプトが、「ふわふわした毛並みの白い猫が、木製のグランドピアノの前に座り、前足で鍵盤を優雅に押している。柔らかな室内光が猫の毛並みを照らし、背景には本棚と観葉植物がぼやけて見える。カメラは猫の横からのミディアムショットで、ピアノの音色に合わせた動きを捉えている」といった詳細な記述に変換されます。
この拡張により、動きのリアリティ、映像美、意味理解の精度が改善されます。
Dashscope API活用
Dashscope APIはQwenシリーズの大規模言語モデルがクラウド上で実行されるため、ローカル環境のVRAMやCPU負荷を一切消費せずにプロンプト拡張が可能です。
Dashscope APIを使用するには、事前にAlibaba Cloud Model StudioでAPIキーを取得する必要があります。
実際に使用する場合には、既存の動画もしくは画像が入力としてある前提で、それを編集・参照・拡張することになります。
サンプルコードはこちら
import requests
import json
import time
DASHSCOPE_API_KEY = ""
BASE_URL = "https://dashscope-intl.aliyuncs.com"
CREATE_URL = f"{BASE_URL}/api/v1/services/aigc/video-generation/video-synthesis"
headers = {
"Authorization": f"Bearer {DASHSCOPE_API_KEY}",
"Content-Type": "application/json",
"X-DashScope-Async": "enable",
}
payload = {
"model": "wan2.1-vace-plus",
"input": {
"function": "image_reference",
"prompt": "A woman standing calmly",
"ref_images_url": [
"https://weel.co.jp/wp-content/uploads/2025/11/image-415.png"
]
},
"parameters": {
"prompt_extend": True,
"obj_or_bg": ["obj"],
"size": "1280*720"
}
}
res = requests.post(CREATE_URL, headers=headers, json=payload)
print("create:", res.status_code, res.json())
res.raise_for_status()
task_id = res.json()["output"]["task_id"]
print("task_id:", task_id)
TASK_URL = f"{BASE_URL}/api/v1/tasks/{task_id}"
while True:
r = requests.get(TASK_URL, headers={"Authorization": f"Bearer {DASHSCOPE_API_KEY}"})
r.raise_for_status()
data = r.json()
status = data["output"]["task_status"]
print("status:", status)
if status == "SUCCEEDED":
out = data["output"]
print("\n=== ORIG PROMPT ===\n", out.get("orig_prompt"))
print("\n=== ACTUAL PROMPT (EXTENDED) ===\n", out.get("actual_prompt"))
print("\n=== VIDEO URL ===\n", out.get("video_url"))
break
if status in ("FAILED", "CANCELED"):
raise RuntimeError(json.dumps(data, ensure_ascii=False, indent=2))
time.sleep(15)結果はこちら
=== ORIG PROMPT ===
A woman standing calmly
=== ACTUAL PROMPT (EXTENDED) ===
纪实摄影风格,一位三十岁左右的东亚女性静静伫立在晨光微照的旧巷中。她身穿米白色风衣,长发松散垂肩,双手自然垂落,神情沉静,目光平和望向远方。背景是斑驳青砖墙与半开木门,光影柔和斜洒于她侧脸与衣摆。微风轻拂发丝与衣角,呈现细微动态。中景半身站姿,略低角度仰拍,突出从容气场。日本語訳はこちら
プロンプトは拡張されましたが、中国語で出力されました。
また、今回参照した画像はこちらの記事で取り扱っている、女性の画像です。
実際に生成された動画がこちら
ローカルQwen系の選択肢
ローカルQwen系モデルを使用する方法は、Hugging FaceからQwenモデルをダウンロードしてローカル環境で実行する形式です。この方法では、API費用が発生せず、オフライン環境でも動作するというメリットがあります。
モデルサイズが大きいほど拡張品質は向上しますが、その分VRAM消費も増加。
下記はモデルごとの必要VRAM目安です。
| モデル名 | タスク対応 | 必要VRAM目安 | 拡張品質 | 実行速度 |
|---|---|---|---|---|
| Qwen2.5-14B-Instruct | T2V | 約28GB | 最高 | 遅い |
| Qwen2.5-7B-Instruct | T2V | 約14GB | 高い | 中程度 |
| Qwen2.5-3B-Instruct | T2V | 約6GB | 中程度 | 速い |
| Qwen2.5-VL-7B-Instruct | I2V/FLF2V | 約16GB | 高い | 中程度 |
| Qwen2.5-VL-3B-Instruct | I2V/FLF2V | 約8GB | 中程度 | 速い |
使うべきケースと注意点
プロンプト拡張は、動画品質を向上させる便利な機能ですが、すべてのケースで必要というわけではありません。
プロンプト拡張を使うべきケースとして、シンプルまたは短いプロンプトしか用意できない場合です。
「犬が走る」のような基本的な記述だけでは、モデルは動きの詳細や環境情報を自由に解釈してしまうため、結果にばらつきが生じます。プロンプト拡張により、これらの曖昧さが具体的な記述に変換され、安定した品質が得られます。
Wan2.1の料金プラン
Wan2.1そのものはオープンソースモデルであり、モデルをダウンロードすることで無料で利用できます。
また、APIも用意されており、API使用料金は下記の通りです。
| モデル | 用途 | 解像度 | 料金(秒単位) | 5秒動画の料金 |
|---|---|---|---|---|
| wan2.1-t2v-turbo | Text-to-Video | 480P | $0.036/秒 | $0.18 |
| wan2.1-t2v-turbo | Text-to-Video | 720P | $0.036/秒 | $0.18 |
| wan2.1-t2v-plus | Text-to-Video | 720P | $0.10/秒 | $0.50 |
| wan2.1-i2v-turbo | Image-to-Video | 480P | $0.036/秒 | $0.18 |
| wan2.1-i2v-turbo | Image-to-Video | 720P | $0.036/秒 | $0.18 |
| wan2.1-i2v-plus | Image-to-Video | 720P | $0.10/秒 | $0.50 |
Wan.videoでもWanを利用することができ、料金は下記の通りです。
| プラン | Free | Pro | Premium |
|---|---|---|---|
| 月額料金 | US$ 0 | US$ 5/月(通常 $72 → 年払い $60、50%オフ) | US$ 20/月(通常 $288 → 年払い $120、50%オフ) |
| 支払い方法 | − | 年払い (Billed Yearly 50%off)または月払い (Billed Monthly) | 年払い (Billed Yearly 50%off)または月払い (Billed Monthly) |
| 月間クレジット | − | 300 Credits | 1200 Credits |


Wan2.1のライセンス
Wan2.1はApache 2.0ライセンスのもとで公開されているため、商用利用を含め、自由に改変・再配布することが認められています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 | |
| 配布 | |
| 特許使用 | |
| 私的使用 | |
Wan2.1の使い方
Wan2.1を動かすのに必要な動作環境は以下の通りです。
■Pythonのバージョン
Python3.8以上
■RAMの使用量
8GBで、1.3Bモデルの480P動画生成が可能だが、16GB以上推奨
また、Wan2.1には、以下のような3つの利用方法があります。
ローカル環境での利用(Windows・Mac)
Windows環境
PythonとCUDA対応GPU環境を用意します。
PyTorch 2.4+ (CUDA対応版) をインストールし、GitHubリポジトリをクローン、そして依存ライブラリをpipで導入。
その後モデルファイルをHuggingFaceからダウンロードします。環境構築が完了すれば、以下のようなスクリプトを実行することで、Text-to-Videoを試すことが可能です。
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --prompt "(入力プロンプト)"Mac環境
残念ながら2025年2月現在でWan2.1は、Appleシリコン対応 (MPS) していません。
1.3BモデルをCPU/MPSでかろうじて動かすのが限界で、実行に非常に時間を要します。もし、Appleシリコンで利用する場合は、サポートのアップデートを待つか、GoogleColabのGPU環境での利用を検討しましょう。
クラウドベースでの利用
GoogleColab
Colab上でもWan2.1を実行することができます。
基本的な手順はWindowsと同じで、GPU対応のランタイムを選択し、GitHubリポジトリをクローン&依存関係をインストール後、モデルをダウンロードしてスクリプトを実行するといった流れです。
Alibaba Cloud PAI ModelGallery
Alibaba Cloud PAI ModelGalleryは、ローカル環境の構築が難しい方や企業・業務利用でクラウドベースの安定した実行環境が必要な方向けのデプロイ手段。
Platform for AIのModelGallery機能を利用することで、GitHubからのモデル手動ダウンロードや複雑な環境設定を行うことなく、数クリックでWan2.1をデプロイし、Web UIまたはAPI経由で利用できます。
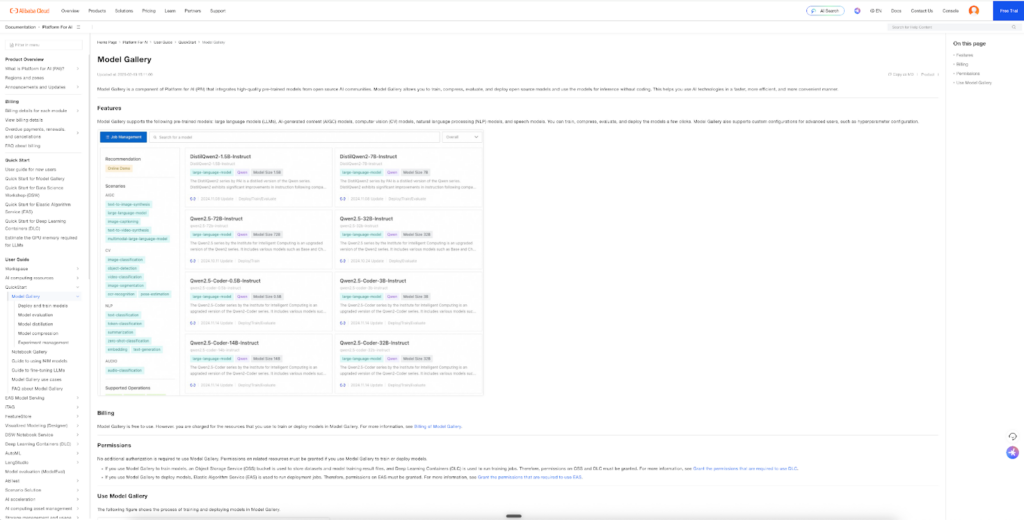
WebUIでの利用
Hugging Face
環境構築不要でWan2.1を試す方法として、Hugging Face上のデモがあります。
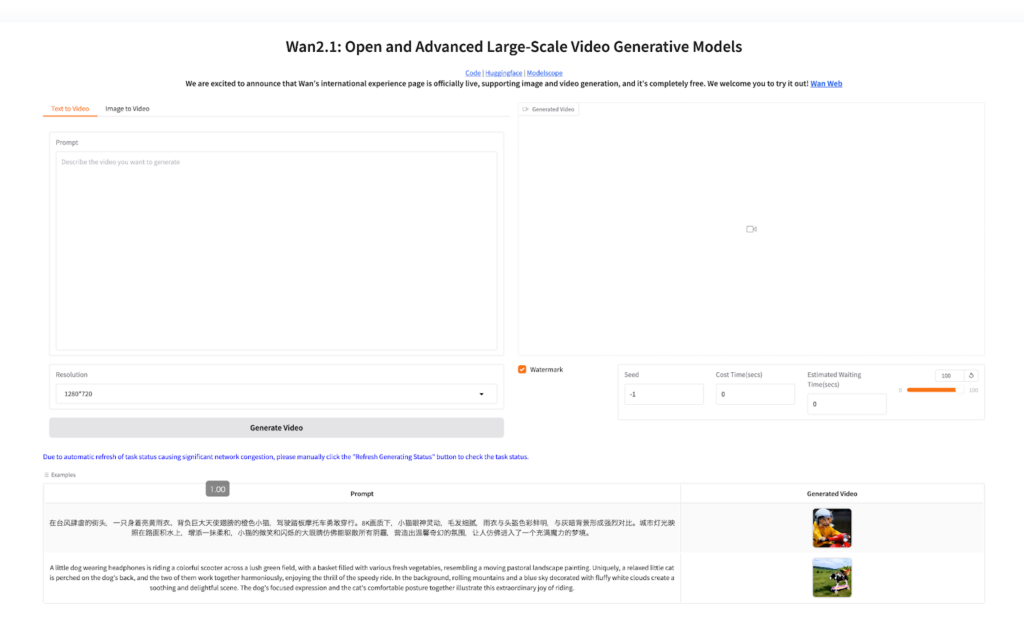
このデモでは、バックエンドでWan2.1モデルがホストされており、英語または中国語のテキストから5秒前後の短い動画を生成することができます。また、Image-to-Videoも試すことができるようです。
簡易GUI・導入補助ツール
ローカル環境でWan2.1を手軽に使うにはそれなりのハードルがあります。
そのためコミュニティが開発した簡易インストーラーやワークフローなどを使うことによって、手軽に利用が可能。
ComfyUI Desktopは、Wan2.1を最も簡単に始められます。
公式サイトから専用インストーラーをダウンロードするだけで、Python環境、ComfyUI本体、必要な依存関係がすべて自動インストールされます。
インストール完了後、内蔵テンプレートから「ワークフロー>テンプレート>ビデオ>Wan 2.1」を選択すれば、不足しているモデルファイルも自動検出され、ダウンロードボタンが表示されます。
EasyWanVideoは、Windows環境に特化した一括環境構築ツール。
Zuntan03が開発したこのツールは、空フォルダを作成し、EasyWanVideoInstaller.batを実行するだけで、ComfyUI、Wan2.1関連ノード、推奨モデル設定がすべて自動セットアップされます。
| ツール名 | 対象OS | 特徴 | 推奨環境 | ダウンロード元 |
|---|---|---|---|---|
| ComfyUI Desktop | Windows/Mac | 公式・自動インストール | VRAM 8GB+ | 公式サイト |
| EasyWanVideo | Windows | I2V特化・日本語対応 | VRAM 12GB+, RAM 32GB+ | GitHub |
ワークフロー配布サイトとしてはCivitaiがおすすめ。
Civitaiには、コミュニティメンバーが作成したWan2.1用ComfyUIワークフローが数百個公開されており、用途別に検索・ダウンロードできます。
推奨パラメータ
Wan2.1で高品質な動画を生成するには、適切なパラメータ設定が必要です。
guide_scaleは、プロンプトへの忠実度を制御するパラメータの一つです。
この値が高いほど、プロンプトの指示に厳密に従った動画が生成されますが、過度に高くすると不自然なアーティファクトが発生する可能性があります。公式推奨値は、T2V-14Bモデルで5.0、T2V-1.3Bモデルで6.0です。
sample_shiftは、生成プロセスのノイズスケジューリングを制御するパラメータ。
解像度によって最適値が異なり、720P生成時は5.0、480P生成時は3.0がよいでしょう。
sample_stepsは、生成の反復回数です。
ステップ数が多いほど高品質になりますが、生成時間も増加します。T2Vモデルのデフォルトは50ステップ、I2Vモデルは40ステップです。
解像度と安定性
Wan2.1では、モデルと解像度の組み合わせによって安定性が大きく異なります。
T2V-1.3Bモデルは720P解像度での動画生成が可能ですが、公式では480P推奨としています。コミュニティからの報告では、720P生成時に480Pと比較して不安定になる傾向があるとされていますが、公式ドキュメントでは明示されていませんでした。
低VRAM環境での運用方法
T2V-1.3Bモデルは約8.19GB VRAMを必要とし、RTX 4090などのコンシューマー向けGPUで動作可能です。
ただし、8GB VRAMのGPUでは、公式要件の8.19GBをわずかに下回るため、–offload_model True や –t5_cpu などのメモリ最適化オプションが必要になる場合があります。
メモリ最適化の他に量子化モデルを使う方法もあります。量子化モデルを使えばファイルサイズとメモリ消費を削減できます。
Mac環境での利用
Wan2.1の公式実装はCUDAを前提としているため、Apple Silicon搭載Macではそのままでは動作しません。
Apple Silicon搭載MacでWan2.1を使用する場合には、MPSを使用します。MPSを使用する場合には、CPUフォールバック用にPYTORCH_ENABLE_MPS_FALLBACK=1を設定、–offload_model True および –t5_cpu によるメモリ使用量の調整をする必要があります。
Wan2.1をGoogleColab上で使ってみた
今回は、GoogleColab A100 GPUで「Text-to-Video」を試してみます。
1.ランタイム設定
「ランタイムの変更」を選択し、「A100 GPU」を選択します。
2.リポジトリのクローンと依存パッケージインストール
以下コードを実行します。
#GitHubから Wan2.1 リポジトリをクローン
!git clone https://github.com/Wan-Video/Wan2.1.git
%cd Wan2.1
#必要なライブラリをインストール(PyTorch 2.4+、diffusers、transformers、opencv-python など)
!pip install -r requirements.txt
#Hugging Face CLI のインストール(モデルダウンロード用)
!pip install "huggingface_hub[cli]"
#GPUが認識されているか確認
import torch
print("PyTorch version:", torch.__version__)
print("GPU available:", torch.cuda.is_available())
print("GPU device:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "None")3.モデルダウンロード
今回は、Text-to-Video 1.3Bモデル(480p向け)をダウンロードします。
※筆者はここで実行完了までに15分ほどかかったので、時間に余裕を持って試してみてください。
#Text-to-Video 1.3B モデルをダウンロード
!huggingface-cli download Wan-AI/Wan2.1-T2V-1.3B --local-dir /content/Wan2.1-T2V-1.3B4.モデル実行
さあ、いよいよモデル実行です!
Promptはこちら
A futuristic robot explores a devastated spaceship. The scene is highlighted by cinematic lighting and high-definition detail.
和訳:
未来的なロボットが、荒廃した宇宙船内を探索する。シネマティックなライトと高精細なディテールが際立つシーン。ひとまず、サクッとテストしたいので、以下のようなパラメータで実行します。
!python generate.py --task t2v-1.3B --size 832*480 \
--ckpt_dir /content/Wan2.1-T2V-1.3B \
--prompt "$A futuristic robot explores a devastated spaceship. The scene is highlighted by cinematic lighting and high-definition detail." \
--sample_guide_scale 6 \
--sample_shift 5 \
--frame_num 24 \
--sample_steps 20 \
--t5_cpu \
--offload_model True \
--save_file text_to_video_quick.mp4上記のコードは、2〜3分ほどで実行完了しました。
これで「text_to_video_quick.mp4」というファイルが保存されているので、以下コードでColab上にファイルを表示します。
from IPython.display import HTML, display
from base64 import b64encode
def show_video(filename, width=480):
with open(filename, 'rb') as f:
mp4 = f.read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
display(HTML(f'<video width="{width}" controls><source src="{data_url}" type="video/mp4"></video>'))
# テスト結果表示
show_video('text_to_video_quick.mp4', width=480)パラメータ設定をかなり低めに抑えたのですがこの品質。予想以上のクオリティでした。
プロンプトは変えず、パラメータだけ上方修正して、再度実行してみます。
実行時間は5分ほど。これもまたキレイな映像に仕上がっています。
Wan2.1をComfyUIで使ってみた
では、次はWan2.1をComfyUIを使って、より視覚的に動画生成を行ってみます。
検証環境は先程と同じくGoogleColabで行います。
コードはGithubでComfyUI-Managerとして公開されているページにあるGoogleColab用のノートブックを参考にします。
※Googleドライブ上にモデルファイルなどを配置するので13GB以上の空きを確保しておきましょう。
GoogleColab上でComfyUIの初期セットアップ
一番最初のコードは初期設定のセットアップになります。
コード実行後、Googleドライブとの連携確認があるので、よく読んで進めてください。
■初期設定
# #@title Environment Setup
from pathlib import Path
OPTIONS = {}
USE_GOOGLE_DRIVE = True #@param {type:"boolean"}
UPDATE_COMFY_UI = True #@param {type:"boolean"}
USE_COMFYUI_MANAGER = True #@param {type:"boolean"}
INSTALL_CUSTOM_NODES_DEPENDENCIES = True #@param {type:"boolean"}
OPTIONS['USE_GOOGLE_DRIVE'] = USE_GOOGLE_DRIVE
OPTIONS['UPDATE_COMFY_UI'] = UPDATE_COMFY_UI
OPTIONS['USE_COMFYUI_MANAGER'] = USE_COMFYUI_MANAGER
OPTIONS['INSTALL_CUSTOM_NODES_DEPENDENCIES'] = INSTALL_CUSTOM_NODES_DEPENDENCIES
current_dir = !pwd
WORKSPACE = f"{current_dir[0]}/ComfyUI"
if OPTIONS['USE_GOOGLE_DRIVE']:
!echo "Mounting Google Drive..."
%cd /
from google.colab import drive
drive.mount('/content/drive')
WORKSPACE = "/content/drive/MyDrive/ComfyUI"
%cd /content/drive/MyDrive
![ ! -d $WORKSPACE ] && echo -= Initial setup ComfyUI =- && git clone https://github.com/comfyanonymous/ComfyUI
%cd $WORKSPACE
if OPTIONS['UPDATE_COMFY_UI']:
!echo -= Updating ComfyUI =-
# Correction of the issue of permissions being deleted on Google Drive.
![ -f ".ci/nightly/update_windows/update_comfyui_and_python_dependencies.bat" ] && chmod 755 .ci/nightly/update_windows/update_comfyui_and_python_dependencies.bat
![ -f ".ci/nightly/windows_base_files/run_nvidia_gpu.bat" ] && chmod 755 .ci/nightly/windows_base_files/run_nvidia_gpu.bat
![ -f ".ci/update_windows/update_comfyui_and_python_dependencies.bat" ] && chmod 755 .ci/update_windows/update_comfyui_and_python_dependencies.bat
![ -f ".ci/update_windows_cu118/update_comfyui_and_python_dependencies.bat" ] && chmod 755 .ci/update_windows_cu118/update_comfyui_and_python_dependencies.bat
![ -f ".ci/update_windows/update.py" ] && chmod 755 .ci/update_windows/update.py
![ -f ".ci/update_windows/update_comfyui.bat" ] && chmod 755 .ci/update_windows/update_comfyui.bat
![ -f ".ci/update_windows/README_VERY_IMPORTANT.txt" ] && chmod 755 .ci/update_windows/README_VERY_IMPORTANT.txt
![ -f ".ci/update_windows/run_cpu.bat" ] && chmod 755 .ci/update_windows/run_cpu.bat
![ -f ".ci/update_windows/run_nvidia_gpu.bat" ] && chmod 755 .ci/update_windows/run_nvidia_gpu.bat
!git pull
!echo -= Install dependencies =-
!pip3 install accelerate
!pip3 install einops transformers>=4.28.1 safetensors>=0.4.2 aiohttp pyyaml Pillow scipy tqdm psutil tokenizers>=0.13.3
!pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
!pip3 install torchsde
!pip3 install kornia>=0.7.1 spandrel soundfile sentencepiece
if OPTIONS['USE_COMFYUI_MANAGER']:
%cd custom_nodes
# Correction of the issue of permissions being deleted on Google Drive.
![ -f "ComfyUI-Manager/check.sh" ] && chmod 755 ComfyUI-Manager/check.sh
![ -f "ComfyUI-Manager/scan.sh" ] && chmod 755 ComfyUI-Manager/scan.sh
![ -f "ComfyUI-Manager/node_db/dev/scan.sh" ] && chmod 755 ComfyUI-Manager/node_db/dev/scan.sh
![ -f "ComfyUI-Manager/node_db/tutorial/scan.sh" ] && chmod 755 ComfyUI-Manager/node_db/tutorial/scan.sh
![ -f "ComfyUI-Manager/scripts/install-comfyui-venv-linux.sh" ] && chmod 755 ComfyUI-Manager/scripts/install-comfyui-venv-linux.sh
![ -f "ComfyUI-Manager/scripts/install-comfyui-venv-win.bat" ] && chmod 755 ComfyUI-Manager/scripts/install-comfyui-venv-win.bat
![ ! -d ComfyUI-Manager ] && echo -= Initial setup ComfyUI-Manager =- && git clone https://github.com/ltdrdata/ComfyUI-Manager
%cd ComfyUI-Manager
!git pull
%cd $WORKSPACE
if OPTIONS['INSTALL_CUSTOM_NODES_DEPENDENCIES']:
!echo -= Install custom nodes dependencies =-
!pip install GitPython
!python custom_nodes/ComfyUI-Manager/cm-cli.py restore-dependencies各種ファイルの配置
初期セットアップ実行後、GoogleドライブにComfyUIというフォルダが新規作成されています。
モデル・テキストエンコーダー・VAEが必要なのでComfyUIのWikiを参照してダウンロードしてください。
大きいモデルだと時間がかかってしまうため、今回は「wan2.1_t2v_1.3B_bf16.safetensors」を使います。
■ファイルの配置図
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_t2v_1.3B_fp16.safetensors #モデル
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # テキストエンコーダー
│ └── vae/
│ └── wan_2.1_vae.safetensors # vaeGoogleColab上でComfyUIを実行する
下記コードを実行してComfyUIを起動します。
!wget -P ~ https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb
!dpkg -i ~/cloudflared-linux-amd64.deb
import subprocess
import threading
import time
import socket
import urllib.request
def iframe_thread(port):
while True:
time.sleep(0.5)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = sock.connect_ex(('127.0.0.1', port))
if result == 0:
break
sock.close()
print("\nComfyUI finished loading, trying to launch cloudflared (if it gets stuck here cloudflared is having issues)\n")
p = subprocess.Popen(["cloudflared", "tunnel", "--url", "http://127.0.0.1:{}".format(port)], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
for line in p.stderr:
l = line.decode()
if "trycloudflare.com " in l:
print("This is the URL to access ComfyUI:", l[l.find("http"):], end='')
#print(l, end='')
threading.Thread(target=iframe_thread, daemon=True, args=(8188,)).start()
!python main.py --dont-print-server実行中に下記のような表示がでれば成功です!
URLをクリックすると少し時間がかかりますがComfyUIの画面が表示されます。
This is the URL to access ComfyUI: https://anderson-br-benz-converted.trycloudflare.comComfyUIでWan2.1を使う
ComfyUIが起動したらWan2.1のワークフローを作成するのですが、今回はComfyUIのWikiにサンプルがあるのでJson形式のファイルをダウンロードして利用します。
ComfyUIを表示し「上部メニューのワークフロー→開く」をクリックしてダウンロードしたJsonファイルを開きます。初期設定と配置しているモデルが違うとエラーが出ますが後で変更するので問題ありません。
また、SaveWEBMのノードでエラーが出るかもしれませんが、こちらも今回は使用しないのでそのままでOKです。
モデルの変更
読み込んだサンプルのワークフローと、実際に配置されているモデルが異なっているとエラーが出てしまいますのでモデルを変更しておきましょう。
「拡散モデルを読み込む」の「unset_name」の箇所がモデルの指定場所です。左右の三角ボタンをクリックすれば配置されているモデルを指定することができます。
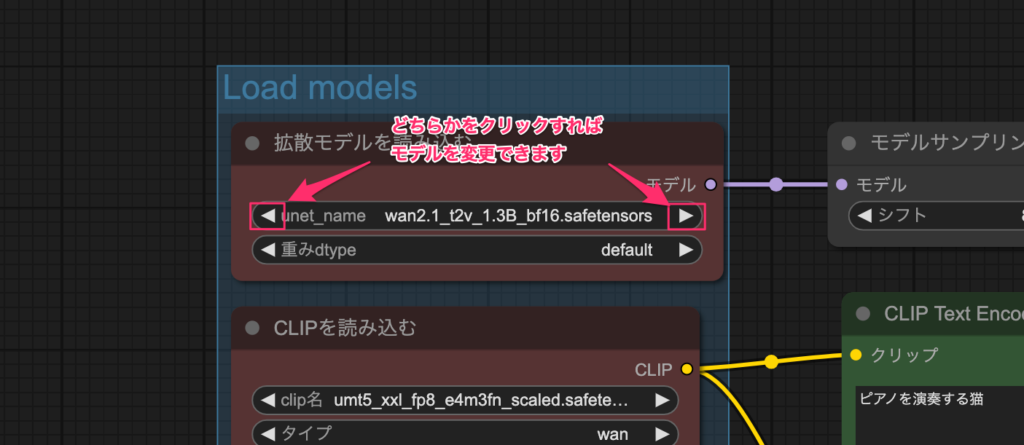
プロンプトの入力と実行
ワークフロー中央の緑のボックスがプロンプト、紫色のボックスがネガティブプロンプトを入力するエリアです。
最初からサンプルテキストが入っていますが、両方削除してまずはシンプルなプロンプトで試してみましょう。今回はネガティブプロンプトはなしで、プロンプトに「A cat playing piano」とだけ入力します。
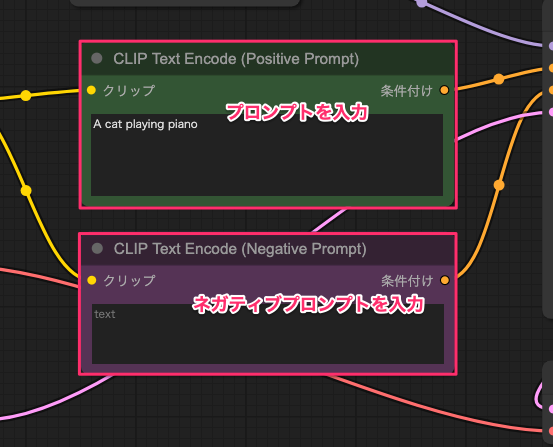
プロンプトを入力したあとは画面下部の「実行する」ボタンをクリックすればOKです。
今回のプロンプトは「ピアノを弾く猫」というシンプルなものでしたが、1秒ほどの動画で概ねプロンプト通りの内容のものが生成されました。
今回、Google Colab T4 GPUでも何度か試したのですが、リソース不足でモデル実行ができませんでした。体感ですが、A100 GPU以上の環境が必須だと感じました。
今回はここまでのご紹介となりますが、気になる方はぜひ、「他のプロンプト」や「Image-to-Video」も試してみてください!
Wan2.1についてのよくある質問
まとめ
最後に改めて、「Wan2.1」の特徴をまとめます。
- オープンソースで公開、テキストや画像から高品質な動画を生成できる
- SoraやLuma、Pikaを大きく上回る性能を持つ
- 「拡散モデル×VAE」の組み合わせでよりリアルな動画生成を実現
- Apache 2.0ライセンスのもとで、無償で利用可能
- 利用方法はローカル、クラウド、WebUIの3つ
日々進化する動画生成AI領域から目が離せませんね!

最後に
いかがだったでしょうか?
Wan2.1などの動画生成AIを活用し、プロダクトや事業の可能性を広げませんか?最先端の生成AI導入に向けた具体的な活用方法や、最適な実装手法について専門家が詳しくご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

