- GLM-OCRは、0.9Bの軽量モデルで大規模モデルに匹敵する性能、$0.03/百万トークンの低コストでAPIもローカル展開も可能
- 手書き・多言語・数式・表・コード・印章まで、従来のOCRが苦手としてきた実用シーンでの高精度認識を実現
- MIT Licenseのオープンソースで自社製品への組み込み自由、ローカル環境でのデータプライバシー保護にも対応
「紙の書類をデータ化したいけど、今のOCRは誤字が多くて修正が大変…」
「手書きの申込書や、複雑なレイアウトの請求書の読み取り精度が上がらない…」
「海外拠点とのやり取りで、多言語が混在したドキュメントの処理に手間取っている…」
企業のDX推進を担う情報システム部門の皆様なら、一度はこうした課題に直面したことがあるのではないでしょうか。ペーパーレス化が進む現代においても、紙媒体の情報をいかに効率よく、正確にデジタル資産へと変換するかは、多くの企業にとって共通の課題です。
従来のOCR技術は確かに進化してきましたが、手書き文字や専門的な記号、複雑な表構造など、特定の条件下ではまだまだ精度に課題が残るのも事実。結局、人の手による確認や修正作業から解放されず、「完全な自動化」には程遠いと感じている方も少なくないでしょう。
もし、これらの課題を解決し、さらにコストを抑えながら導入できる新しいOCR技術があるとしたら、興味はありませんか?
この記事では、2026年2月に登場したばかりの次世代OCRモデル「GLM-OCR」について、その驚くべき性能から具体的な活用シーン、気になる料金体系まで、どこよりも詳しく、そして分かりやすく解説していきます。あなたの会社の文書処理業務を、次のステージへと引き上げるヒントがここにあります。
\生成AIを活用して業務プロセスを自動化/
GLM-OCRの概要
GLM-OCRの全体像を把握しましょう。このモデルは、単なる文字認識ツールではなく、文書の「意味」を理解することを目指して開発されました。
登場した背景 – 従来のOCRが抱えていた課題
これまで多くの企業で利用されてきたOCRは、主に画像からテキスト情報を抽出することに特化していました。しかし、ビジネスの現場で扱う書類は、単純なテキストばかりではありません。例えば、以下のような課題がありました。
- 報告書に含まれるグラフや表、論文の数式、プログラムのコードなどが正しく認識されない。
- 印刷された活字は読めても、手書きの文字や、デザイン性の高いフォントの認識精度が低い。
- 高い精度を求めると、大規模なモデルが必要になり、API利用料やサーバー維持費といったコストが跳ね上がる。
なお、生成AI-OCRについて詳しく知りたい方は下記の記事をご覧ください。

GLM-OCRとは – 新しいアプローチ
GLM-OCRは、単に文字の形を読み取るのではなく、文書全体の構造や文脈を理解する「マルチモーダルOCRモデル」として設計されています。これは、人間が書類を読むときに、文字だけでなく、レイアウトや図表の位置関係からも情報を得ているのと同じアプローチです。
具体的には、Zhipu AIが開発するGLM(General Language Model)シリーズの視覚言語モデル「GLM-V」のアーキテクチャを基盤としています。わずか0.9B(9億)という、近年の大規模言語モデルと比較して非常に軽量なパラメータサイズでありながら、業界標準のベンチマークでトップクラスのスコアを記録しました。
開発元のZ.AIは、その性能について、大規模モデルであるGoogleのGemini-3-Proに「迫る性能(approaching performance)」であると報告しています。
この「軽量・高精度」の実現が、GLM-OCRを次世代のOCR技術として注目させる大きな理由となっています。
なお、同じOCRの機能を持つMistral OCR 3について、以下の記事で記載しております。詳しく知りたい方は、併せてご確認ください。
驚きの精度を支えるGLM-OCRの「2段階処理」の仕組み
GLM-OCRがなぜこれほど高い精度を誇るのか、そのカギは「レイアウト解析」と「並列認識」という、役割の異なる2つのステップにあります。それぞれのエキスパートが連携プレーをすることで、複雑な文書も正確に読み解いていくのです。
まずは書類の「設計図」を作成(レイアウト解析)
はじめに、文書の「設計図」を作る専門家、「PP-DocLayout-V3」が登場します。このモジュールが、書類全体をスキャンして「ここが見出し、ここが本文、これは表だね」というように、各パーツの配置を瞬時に見抜きます。たとえ書類が少し斜めになっていたり、本のページがカーブしていたりしても問題ありません。人間が目で見るのと同じように、全体の構造を柔軟に理解してくれます。
各パーツを専門家チームが一斉に処理(並列認識)
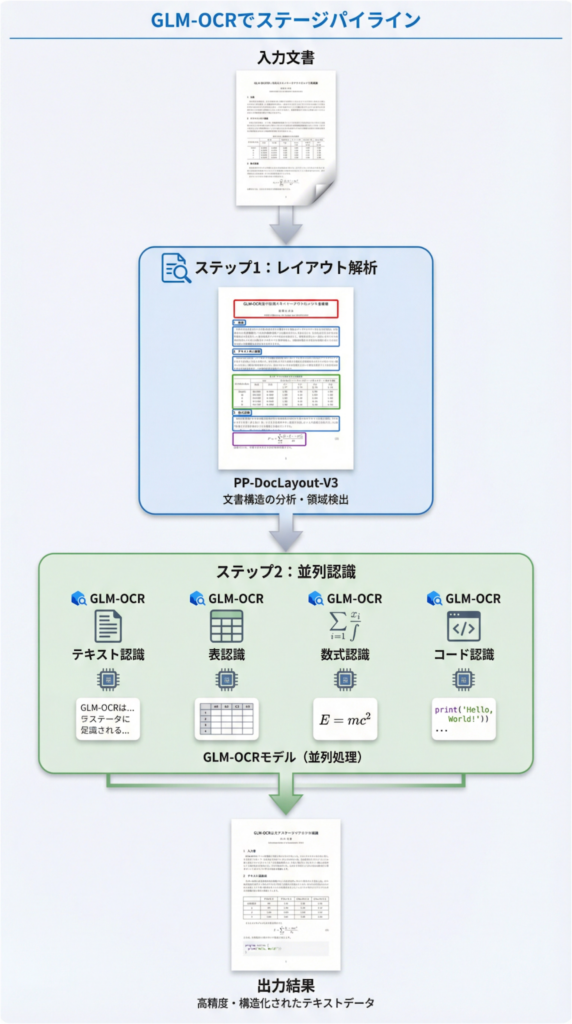
設計図が出来上がると、次はその図面をもとに、各分野の専門家チームが一斉に作業に取り掛かります。レイアウト解析で切り分けられた「テキスト部分」「表部分」「数式部分」などを、GLM-OCRモデルがそれぞれ得意な方法で同時に処理していくイメージです。テキストはテキスト、表は表として、それぞれの特性に合わせた最適なアプローチを採ることで、プロセス全体としてのスピードと正確さを両立させています。
賢い学習法「MTP」が実現する、軽くてパワフルな頭脳
GLM-OCRのすごさは、その構造だけではありません。実は、モデルの「学習方法」にも、その賢さの秘密が隠されています。それが「Multi-Token Prediction (MTP)」という、いわば学習のショートカット術です。
多くのモデルが、英単語を一つひとつ覚えるように「This」「is」「a」「pen」と順番に学習していくのに対して、MTPは「This is a pen」と、いくつかの単語をまとめてフレーズとして一気に覚えてしまいます。
この「まとめ食い」のような学習スタイルは、非常に効率的です。短時間でたくさんの知識を吸収できるため、GLM-OCRは0.9Bというスリムな体型でありながら、何倍も体の大きなモデルと肩を並べるほどのパフォーマンスを発揮できる、というわけです。


GLM-OCRの特徴
次に、企業担当者の皆様が気になるGLM-OCRの具体的な強みや特長について、競合との比較も交えながら解説します。
圧倒的な性能とコスト効率の両立
GLM-OCRの最大の特長は、卓越した性能と優れたコスト効率を両立させている点です。
客観的な評価が示す性能
開発元のZ.AIによると、GLM-OCRは多様な文書の読解能力を測るためのベンチマークテスト「OmniDocBench V1.5」において、94.62点というスコアを記録し、総合1位の評価を獲得したと報告されています。
一方で、2026年2月4日時点で公開されている第三者機関「2077AI」のOmniDocBench V1.5リーダーボードでは、GLM-OCRはまだ掲載されていません。参考として、同リーダーボードの上位モデルのスコアを以下に示します。
| モデル | パラメータサイズ | OmniDocBench V1.5スコア |
|---|---|---|
| PaddleOCR-VL-1.5 | 0.9B | 94.5 |
| PaddleOCR-VL | 0.9B | 91.93 |
| MinerU2.5 | 1.2B | 90.67 |
| Qwen3-VL-235B-A22B-Instruct | 235B | 89.15 |
| Gemini-2.5 Pro | – | 88.03 |
このように、GLM-OCRが公式に主張するスコアは非常に高いものですが、他のモデルも日々進化しており、客観的な評価軸で比較検討することが重要です。
驚異的なコストパフォーマンス
これだけの性能を持ちながら、APIの利用料金は100万トークンあたりわずか$0.03(入出力ともに)という低価格に設定されています。これは、他の主要なAIモデルと比較しても非常に安価であり、大量の文書を処理する必要がある企業にとって、大きなコストメリットをもたらします。
実用シーンに最適化された多様な認識能力
ベンチマークのスコアもさることながら、GLM-OCRが本当に評価されるべきは、ビジネスの現場で直面する様々な課題に対応できる、その柔軟性と実用性です。
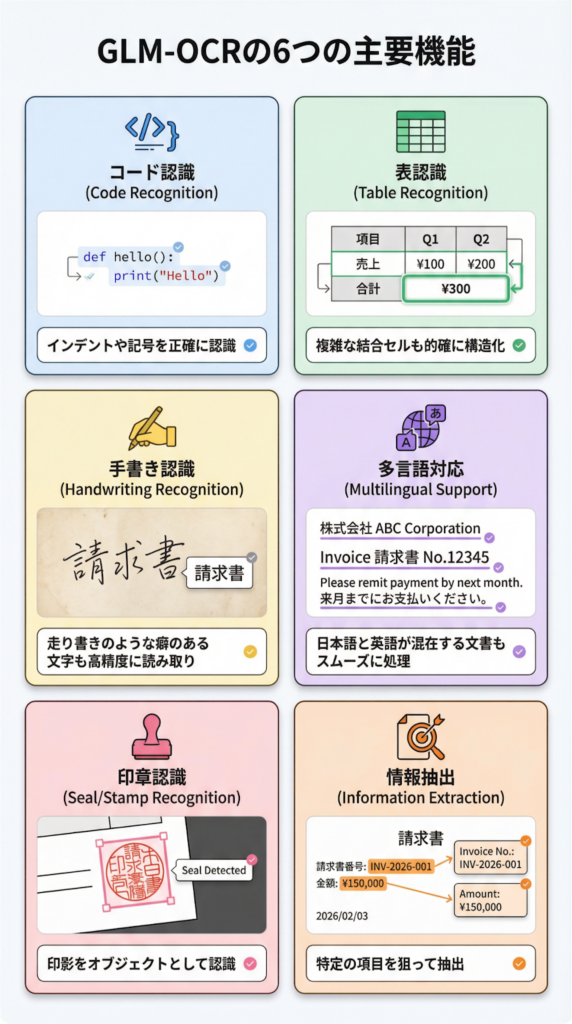
公式の内部評価では、以下の6つの実用的なシナリオで、その有効性が確認されています。
- プログラムコードのインデントや記号を正確に認識。
- 複雑な結合セルや複数行にわたる項目も的確に構造化。
- 走り書きのような癖のある文字も、文脈から判断して高精度に読み取り。
- 日本語と英語が混在するような文書もスムーズに処理。
- 契約書などで使われる印影も、文字としてではなくオブジェクトとして認識。
- 請求書番号や金額など、特定の項目を狙って抽出。
GLM-OCRの安全性・制約
高機能なツールを導入する際には、セキュリティや利用上の注意点も重要です。GLM-OCRを安心して利用するために、知っておくべきポイントを整理しました。
API利用とローカル展開におけるセキュリティ
GLM-OCRは、利用形態に応じてセキュリティレベルを選択できるのが大きな利点です。
APIサービスを利用する場合
通信は暗号化され、APIキーによってアクセスが管理されます。手軽に利用を開始できますが、データを外部のサーバーに送信することになります。提供元であるZhipu AIのプライバシーポリシーに準拠した運用となります。
ローカル環境で展開する場合
GLM-OCRの大きな魅力の一つが、自社のサーバーに「自分たち専用のOCR環境」を構築できる点です。オープンソースなので、外部のサービスにデータを送る必要が一切なく、すべての処理が社内で完結します。
個人情報や企業秘密など、データの取り扱いに細心の注意が求められる金融、医療、法務といった分野の企業様にとっては、これは何よりもうれしいポイントではないでしょうか。どんなに厳重なセキュリティ対策が施されたクラウドサービスでも、「データを外部に送信する」という行為に不安を感じることはあるかもしれません。
その点、ローカル環境であれば、大切な情報をがっちりと自社内でガードしながら、高精度なOCRの恩恵を受けることができます。
利用前に確認したいインプットの制限
現在のバージョンでは、APIを利用する際にいくつかの入力制限が設けられています。大量処理を検討する際には、これらの仕様を確認しておくことが重要です。
| 項目 | 制限内容 |
|---|---|
| 対応フォーマット | PDF, JPG, PNG |
| 画像サイズ | 1ファイルあたり10MBまで |
| PDFサイズ | 1ファイルあたり50MBまで |
| PDFページ数 | 1ファイルあたり100ページまで |
これらの制限は、今後のアップデートで緩和される可能性もありますが、現時点でのシステム設計においては考慮に入れておく必要があります。
GLM-OCRの料金
GLM-OCRの料金体系はシンプルかつ柔軟で、企業の規模や用途に合わせて最適なプランを選択できます。
API利用と無料オプションの選択肢
大きく分けて、手軽な「API利用」と、自由度の高い「ローカル展開」の2つの選択肢があります。
| 項目 | API利用(従量課金) | ローカル展開(無料オプション) |
|---|---|---|
| 料金 | $0.03 / 100万トークン(入力・出力共通) | モデル自体のライセンスは無料 |
| メリット | 初期投資が不要で、使った分だけの支払いで済む。サーバーの管理やメンテナンスの手間がかからない。 | ランニングコストはサーバーの維持費のみ。データプライバシーを完全に保護できる。自社のシステムに合わせて自由にカスタマイズ可能。 |
| 向いている企業 | まずはスモールスタートで効果を試したい企業、処理量が月ごとに変動する企業 | 大量の文書を定常的に処理する企業、機密情報を扱う企業、独自のOCRサービスを構築したい企業 |


GLM-OCRのライセンス
オープンソースソフトウェアをビジネスで利用する上で、ライセンスの確認は避けて通れません。GLM-OCRは、商用利用においても柔軟なライセンス体系を採用しています。
商用利用も可能なオープンソースライセンス
GLM-OCRのモデル本体は「MIT License」という、緩やかな条件のライセンスで公開されています。これは、要約すると以下の行為を自由に行えることを意味します。
| 許可される行為 | 内容 |
|---|---|
| 商用利用 | 自社の有料サービスに組み込んで提供することができます |
| 改変 | 自社のニーズに合わせてモデルを改良することができます |
| 再配布 | 改変したモデルを配布することも可能です |
ライセンスについて、一つだけ知っておきたいポイントがあります。GLM-OCRの正確なレイアウト解析を支えている「PP-DocLayout-V3」という相棒コンポーネントは、「Apache License 2.0」という別のライセンスで提供されています。
そのため、GLM-OCRのフル機能を使うシステムを組む場合は、それぞれのルールを守る、という形になります。
「ライセンスが2種類あると、手続きが面倒なのでは?」と心配になるかもしれませんが、ご安心ください。
GLM-OCRの使い方
GLM-OCRを試すために、Google Colabを使用して、環境を構築することができます。
- Google Colabを開き、新しいノートブックを作成します。
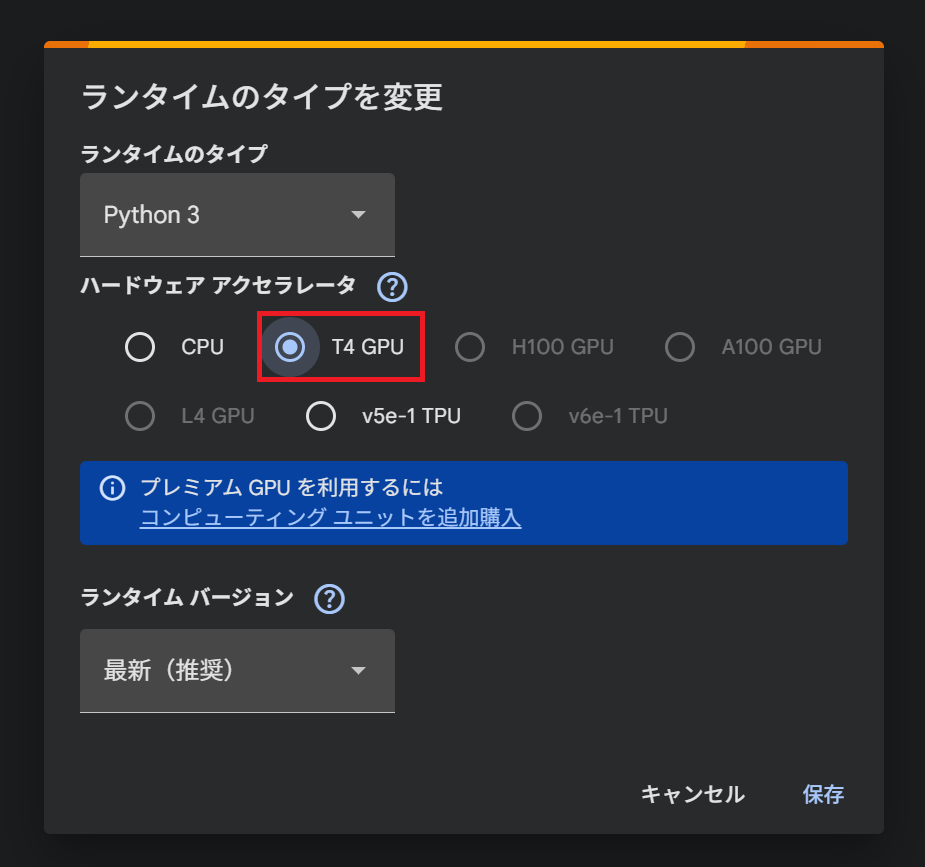
- Colabのメニューから ランタイム > ランタイムのタイプを変更 を選択し、ハードウェアアクセラレータで T4 GPU を選択します。
- 以下のコマンドを実行し、必要なライブラリのインストールを行います。
コマンド
!pip install git+https://github.com/huggingface/transformers.git
!pip install torch torchvision torchaudio
!pip install accelerate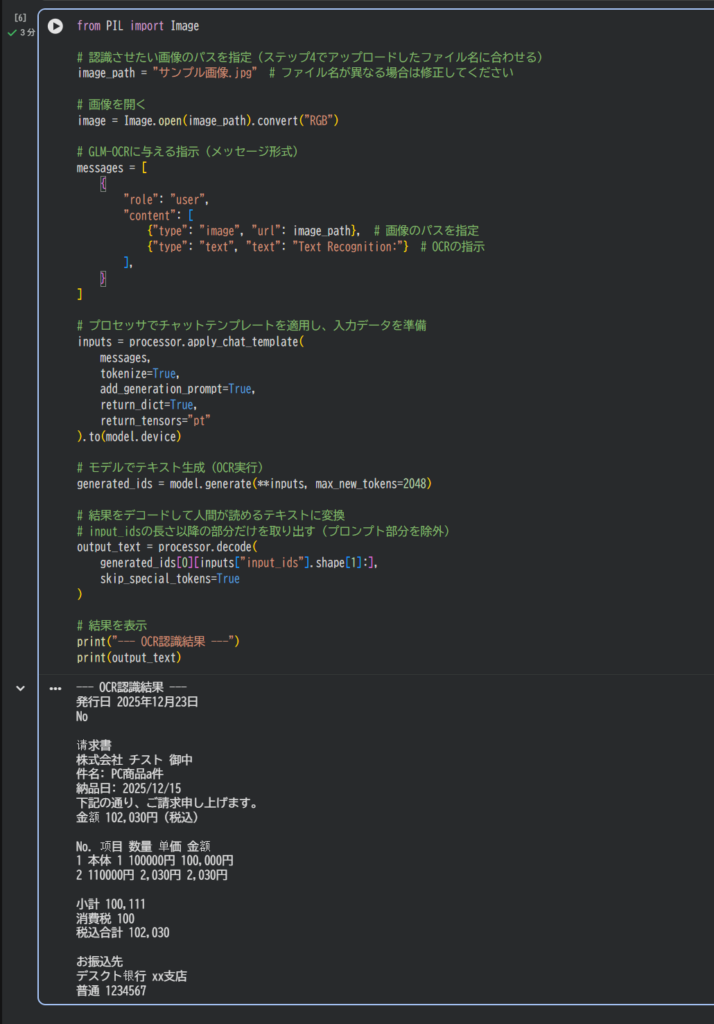
- 次のセルに、モデルを読み込むためのPythonコードを記述します。
コード
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText
from PIL import Image
# モデルのパスを指定
MODEL_PATH = "zai-org/GLM-OCR"
# プロセッサ(入力データの前処理役)を読み込み
processor = AutoProcessor.from_pretrained(MODEL_PATH, trust_remote_code=True)
# モデル本体を読み込み
# torch_dtype="auto"でGPUに最適化し、device_map="auto"で自動的にGPUに配置
model = AutoModelForImageTextToText.from_pretrained(
MODEL_PATH,
torch_dtype=torch.float16, # 半精度で読み込みメモリを節約
device_map="auto",
trust_remote_code=True
)
print("モデルの準備が完了しました。")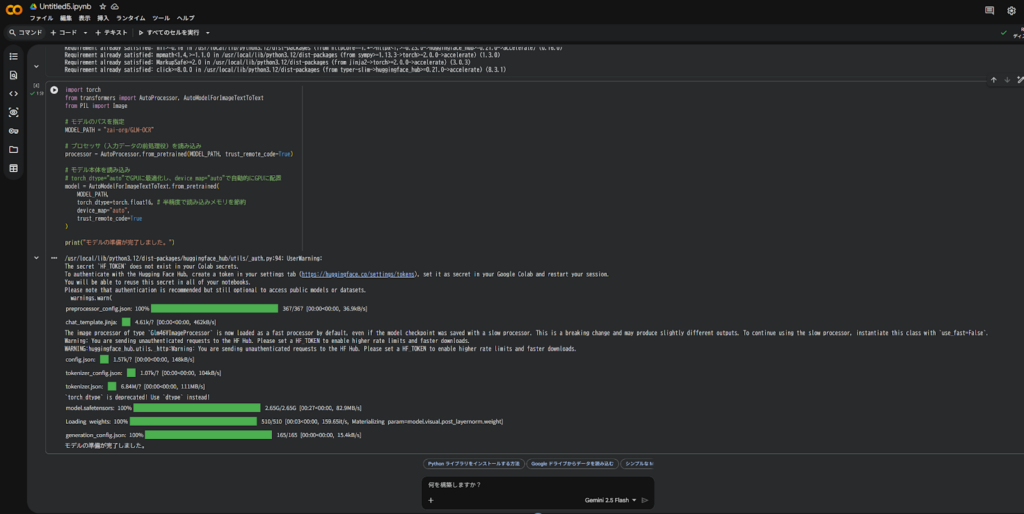
ここまでで、モデルの読み込みが完了しました。
【業界別】GLM-OCRの活用シーン
これまでの説明で、GLM-OCRが非常にポテンシャルの高い技術であることが理解できたでしょう。ここでは、より具体的に「自社のどの業務で使えるのか?」を示すために、業界別・課題別の活用シーンをご紹介します。
金融・保険業界
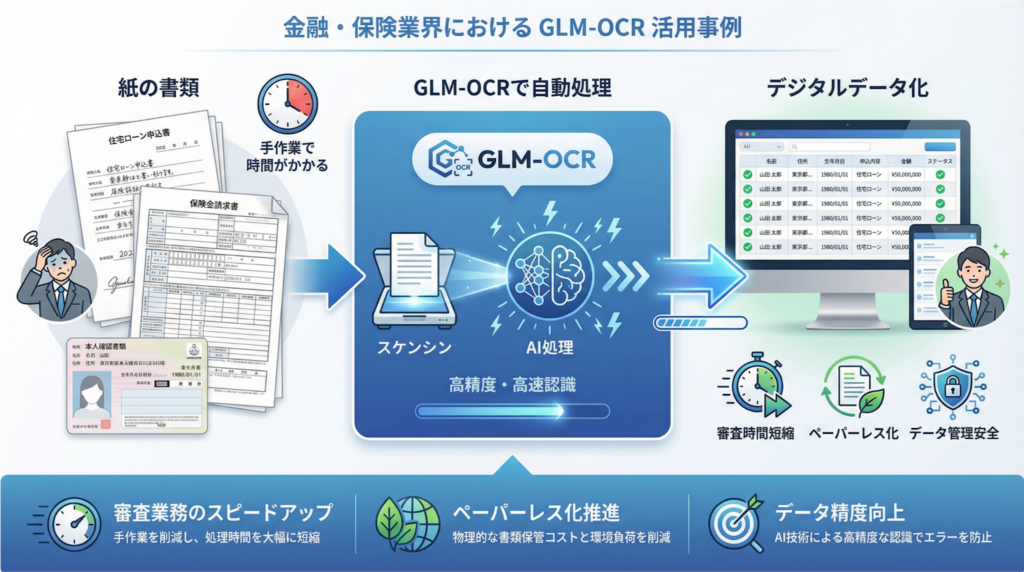
住宅ローン申込書(手書き)、保険金請求書(複雑な表形式)、本人確認書類(IDカード)などの情報を、正確かつ迅速にデータ化。審査業務のスピードアップとペーパーレス化を強力に推進します。
なお、金融・保険業界における生成AIの活用方法については下記の記事をご覧ください。
金融業界はこちら

保険業界はこちら

製造・物流業界
紙の作業指示書や、手書きの検品チェックシート、配送伝票などをデジタル化。現場のデータをリアルタイムで基幹システムに連携し、生産性向上や在庫管理の最適化に貢献します。
なお、製造・物流業界における生成AIの活用方法については下記の記事をご覧ください。
製造業界はこちら

物流業界はこちら

医療・製薬業界
医師の手書きカルテや、膨大な研究論文、治験データなどを解析。構造化されたデータとしてデータベースに蓄積することで、研究開発の加速や診断支援システムの構築をサポートします。
なお、医療・薬業界における生成AIの活用方法については下記の記事をご覧ください。
医療業界はこちら

薬業界はこちら

法務・知財業界
過去の判例や契約書の束から、必要な条文や関連情報を瞬時に検索。リーガルテック領域における情報収集・分析業務を大幅に効率化します。
なお、法務業界における生成AIの活用方法については下記の記事をご覧ください。

学術・教育機関
図書館に眠る貴重な古文書や、学生の手書きレポートをデジタルアーカイブ化。数式や専門記号も正確に認識するため、理系分野の研究にも活用できます。

【課題別】GLM-OCRが解決できること
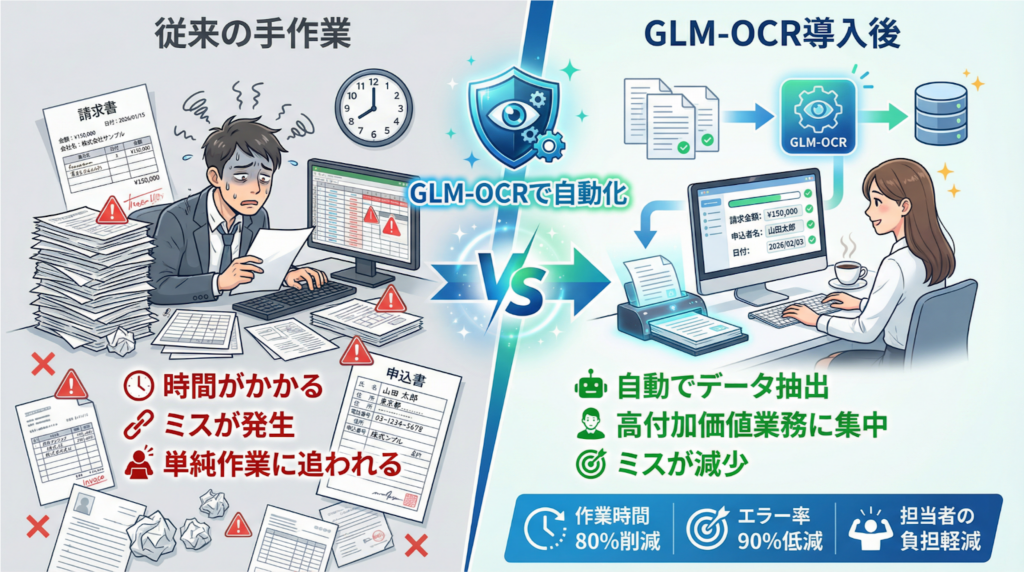
GLM-OCRを活用すれば、様々な課題の解決・負担軽減が期待できます。ここでは、代表的な課題と導入効果を解説します。
RAG(検索拡張生成)の精度が上がらない
大規模言語モデル(LLM)に情報を与える前の「前処理」としてGLM-OCRを活用。高精度にテキストと構造を抽出することで、LLMが参照する情報の質が向上し、結果としてAIチャットボットなどの応答精度が飛躍的に向上します。
なお、RAGに関しては下記の記事をご覧ください。

データ入力担当者の負担が大きい
請求書や申込書など、定型・非定型の様々なフォーマットから必要な項目(例:請求金額、申込者名)を自動で抽出。単純なデータ入力作業から従業員を解放し、より付加価値の高い業務へのシフトを促します。
なお、生成AIを活用したデータ入力については下記の記事をご覧ください。

海外拠点との書類のやり取りが煩雑
中国語、英語、フランス語、スペイン語、ロシア語、ドイツ語、日本語、韓国語など、多言語に対応。日本語・英語・中国語などが混在した文書も一度で処理できます。言語ごとにOCRを使い分ける手間をなくし、グローバルな文書管理を一元化します。
なお、書類作成段階で課題を多く抱えている企業担当者様へ。以下の記事で解決策の一つをご提案しております。詳しくは下記記事をご確認ください。

GLM-OCRを実際に使ってみた
前項で記載した実装環境を使用して、実際に使用してみました。
- Google Colabにて作成したノートブックへアクセスします。
- 認識させたい画像をアップロードします。
(1)Colabの左側にあるフォルダアイコンをクリックして、ファイルブラウザを開きます。
(2)ファイル > アップロード をクリックし、OCRで試したい画像ファイルを選択します。
アップロードした画像は以下になります。

- 以下のコードをセルに入力し、実行して読み取りを実行します。
コード
from PIL import Image
# 認識させたい画像のパスを指定(ステップ4でアップロードしたファイル名に合わせる)
image_path = "サンプル画像.jpg" # ファイル名が異なる場合は修正してください
# 画像を開く
image = Image.open(image_path).convert("RGB")
# GLM-OCRに与える指示(メッセージ形式)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": image_path}, # 画像のパスを指定
{"type": "text", "text": "Text Recognition:"} # OCRの指示
],
}
]
# プロセッサでチャットテンプレートを適用し、入力データを準備
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
# モデルでテキスト生成(OCR実行)
generated_ids = model.generate(**inputs, max_new_tokens=2048)
# 結果をデコードして人間が読めるテキストに変換
# input_idsの長さ以降の部分だけを取り出す(プロンプト部分を除外)
output_text = processor.decode(
generated_ids[0][inputs["input_ids"].shape[1]:],
skip_special_tokens=True
)
# 結果を表示
print("--- OCR認識結果 ---")
print(output_text)- 実行結果は以下の様になりました。
手書き部分の日本語読み取りについては、まだまだ正確に読み取れていない部分もありますが、印刷部のテキストや手書きの数字部分については正確に読み込めているので、見積書や請求書など数値を読み込む必要のある場面で、大いに活躍できるのではないかと感じました。
まとめ
この記事では、次世代OCRモデル「GLM-OCR」について、その技術的な背景から具体的な活用方法まで解説してきました。
GLM-OCRは、単なる「文字を読む」ツールではありません。文書の構造を理解し、手書き文字や数式といった複雑な情報も的確に捉え、それをビジネスで活用しやすい形に整えてくれます。いわば「賢い文書整理アシスタント」と言えるでしょう。
「軽量・高精度・低コスト」という三拍子に加え、商用利用しやすいオープンソースライセンスであることから、これまでコストや精度の問題でOCR導入をためらっていた企業にとって、待望のソリューションと言えます。
2026年2月に登場したばかりのこの新しい技術は、まだ発展の途上にあります。今後、さらに多くの言語への対応や、エッジデバイスでの活用など、その可能性は広がっていくでしょう。GLM-OCRの導入を検討することは、競合他社に先駆けて、文書処理DXの大きな一歩を踏み出すことに繋がります。

最後に
いかがだったでしょうか?
弊社では、GLM-OCRをはじめとする最新のAI技術を活用した業務改善コンサルティングから、システム開発、導入支援までをワンストップで提供しております。
お客様の具体的な業務内容や課題をヒアリングした上で、最適な導入プランをご提案いたします。PoC(概念実証)の実施や、小規模な部門へのトライアル導入も可能です。
ご興味をお持ちいただけましたら、お気軽にご連絡ください。専門のコンサルタントが、貴社のDX推進を全力でサポートいたします。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。