- Meta発、複雑に混ざり合った音声データから、特定の音だけを抽出・分離・除去できる最先端AIモデル
- 画像分野で反響を呼んだ「Segment Anything Model (SAM)」のコンセプトを音声領域に拡張したもの
- テキスト・視覚(ビジュアル)・時間の3種類のプロンプトによって、柔軟にターゲット音を指定可能
2025年12月17日、Meta社は、音声編集の常識を覆す画期的なAIモデル「SAM Audio」を公開しました!
これは、画像分野で大きな反響を呼んだ「Segment Anything Model (SAM)」のコンセプトを音声領域に拡張したもので、まるで音声版「Photoshop」のように、どんな音でも自在に抜き出し・消去できると注目を集めています。
例えば、バンド演奏の動画から、ボーカルやギターの音だけをワンクリックで取り出したり、屋外で録画した映像から、交通ノイズをテキスト入力だけで、綺麗に除去したりすることも夢ではないとのこと。
そこで本記事では、SAM Audioの概要や性能、ライセンス情報や使い方までを徹底的に解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
SAM Audioの概要

SAM Audioは、複雑に混ざり合った音声データから、特定の音だけを抽出・分離・除去できる最先端AIモデルです。
最大の特徴は、テキスト・視覚(ビジュアル)・時間の3種類のプロンプトによって、柔軟にターゲット音を指定できる点にあります。
具体的には、ユーザーは、①「犬の鳴き声」や「ギターの音」など自然言語の指示を入力したり、②動画の場合は画面上の音の発生源(例えば鳴いている犬や話者)を直接クリックして指定したり、③音声波形上で時間範囲を選択して「この区間に含まれる音」を指示することができます。


これらのプロンプトは単独でも組み合わせても利用可能で、ユーザーの意図通りに細かな音のコントロールが可能です。
さらに、SAM Audioは、従来バラバラに存在した音声処理ツールを1つに統合した汎用モデルである点も重要です。
従来の音源分離ソフトでは「ボーカル・ドラム・ベース」など、限定的なカテゴリごとの分離が主流でしたが、SAM Audioは、特定の音色や楽器に縛られないオープンボキャブラリー型の分離を実現しています。
言い換えると、学習データに含まれるあらゆる種類の音響イベントを対象にできて、ユーザーが想像する「任意の音」を分離可能な柔軟性を備えている、ということです。
これによって、音楽制作・ポッドキャスト編集・映像制作・科学研究・アクセシビリティ支援などの幅広い分野で、SAM Audioはプロ顔負けの音声編集を誰にでも手軽にもたらしてくれるわけです。


SAM Audioの性能
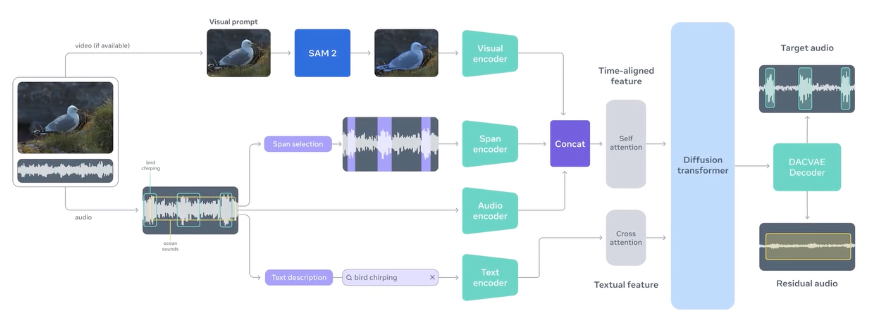
モデルのアーキテクチャには、Diffusion Transformer(拡散変換器)という生成モデル技術が採用され、効率的に高品質な音声分離を行い、音声信号そのものは、一度DAC-VAEと呼ばれるオーディオコーデックで圧縮して処理するなど、独自の工夫も凝らされています。
また、モデル内部には、Perception Encoder Audiovisual (PE-AV)という共通エンジンが組み込まれており、音声と映像の特徴を統合的に扱う役割を果たします。
こうした先進的な設計と、大規模な学習データ(実音源と合成音源を含む多種多様な音声データ)による訓練の結果、SAM Audioは従来モデルを上回る性能を発揮しています。
Meta社の評価では、新たに策定したベンチマーク「SAM Audio-Bench」を用いたテストで、SAM Audioが幅広いタスクで最先端モデル比で優れた結果を示しました。
例えば、一般的な環境音の分離では既存手法(競合モデルのSoloAudioなど)に対し、36%も高い勝率を記録し、楽器ごとの音源分離では、専門特化モデルと同等以上の品質を達成しています。
さらに処理スピードも実用的で、1秒の音声を0.7秒程度で処理できるリアルタイム超え(RTF≈0.7)の高速性を実現しました。
SAM Audioのライセンス
Meta社は、SAM Audioをオープンソースとして公開し、開発者コミュニティに貢献しています。
ただし、そのライセンスは、一般的なOSSライセンスではなく、Meta独自の「SAM License」と呼ばれるものです。これは事実上、研究目的でも商用目的でも自由に利用・改変・再配布が可能な一方、モデルの不適切な悪用を防ぐためのいくつかの制限事項も盛り込まれています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 |  | ・営利目的での利用が許可 ・ただし軍事目的・核関連など一部禁止分野あり |
| 改変 | | |
| 配布 | | ・同じSAM Licenseで提供、ライセンス文書を付与する必要あり |
| 特許使用 | | |
| 私的使用 | |
SAM Audioの料金
SAM Audioは、ライセンス料金やサブスクリプション費用といった直接的なコストは一切発生しません。
Meta社が提供するオンラインデモ環境「Segment Anything Playground」にアクセスすれば、誰でも無料で本モデルの機能を試すことができます。
また、モデルのコードおよび学習済みパラメータもオープンソースで公開されていて、GitHubやHugging Faceから自由にダウンロードしてローカル環境で実行可能です。
| プラン | 料金 |
|---|---|
| Webデモ利用 | 無料 |
| モデルダウンロード | 無料 |
SAM Audioの使い方
SAM Audioの使い方は、大きく分けて①ブラウザ上のPlaygroundで試す方法と②ローカル環境でモデルを動かす方法の2通りがあります。
①Playgroundでの使い方
1番お手軽にSAM Audioを試用するには、Meta社が提供するウェブアプリケーション「Segment Anything Playground」を利用します。
ブラウザでPlaygroundサイトにアクセスすると、SAM Audioを含む最新モデル群が一覧表示されるので、そこから「SAM Audio」を選択します。
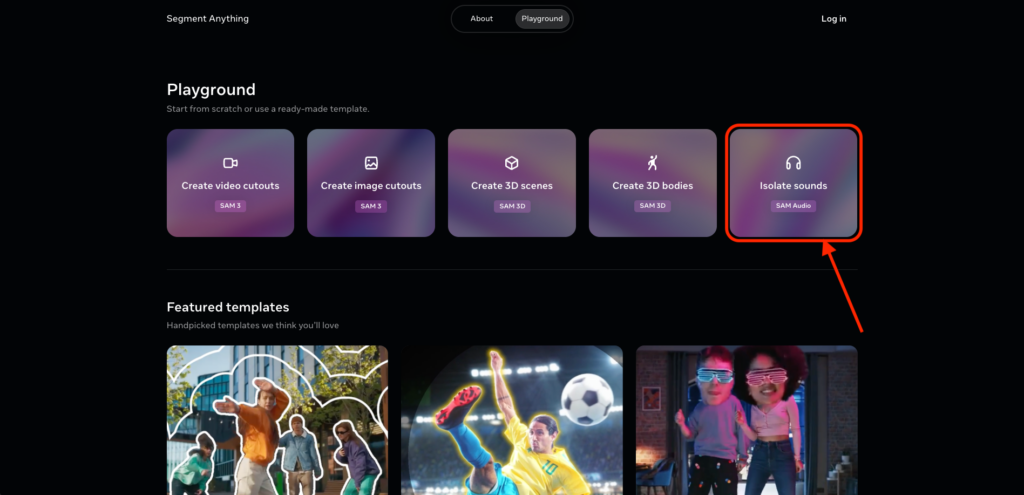
サイト登録やログインは不要で、サイト上に用意されたサンプル音声/動画を使うこともできますし、自分の手持ちのファイル(音声ファイルや動画ファイル)をアップロードすることもできます。
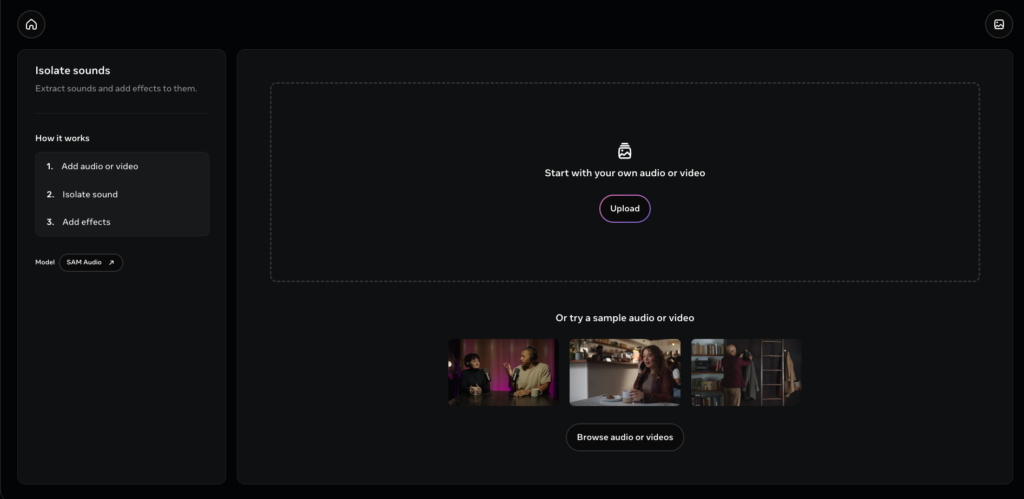
アップロードが完了すると、画面上に音声の波形や(動画の場合は映像プレビュー)が表示され、SAM Audioによる編集が可能な状態になります。
②ローカル環境でモデルを使用する方法
より自由度高くSAM Audioを活用したい開発者向けに、Metaは、モデルのコードと学習済みモデルを公開しています。
Python環境があれば、自分のPCやサーバ上で、SAM Audioによる音源分離をプログラム的に実行可能です。
まず、GitHub上の公式リポジトリをクローンするか、Python用パッケージとしてインストールします(リポジトリ直下でpip install .を実行すると必要なライブラリが導入されます)。
また、モデルのチェックポイント(重みファイル)は容量が大きいので、Hugging Faceのモデル配布ページからダウンロードする形になっています。
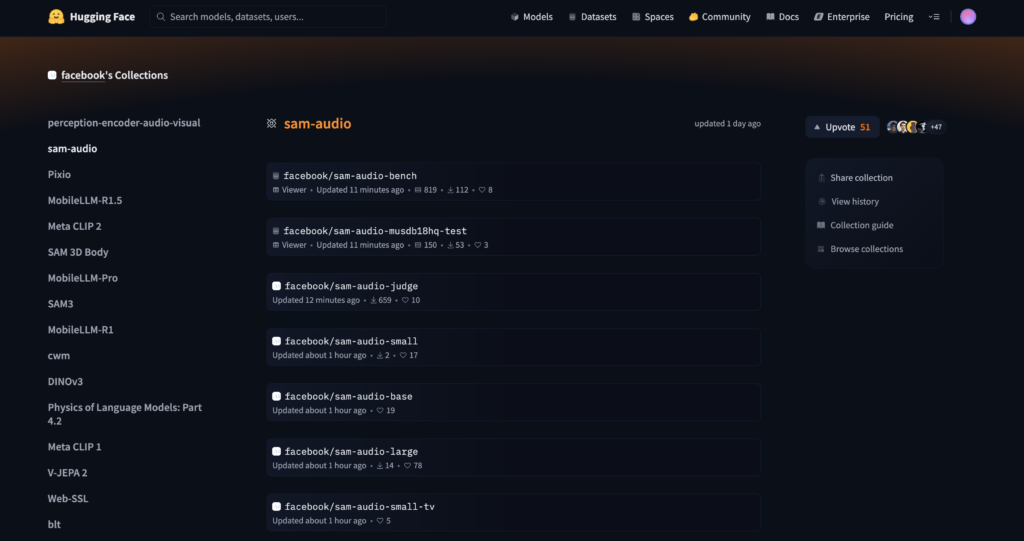
初回利用時には、Hugging Face上で利用申請(ワンクリックでSAM Licenseに同意)を行い、認可を受けておく必要があります。認可された後は、コード中からHugging Face経由でモデルを自動取得できます。
セットアップができたら、実際に音声分離を行うコードは非常にシンプルです。以下がコード例です。
from sam_audio import SAMAudio, SAMAudioProcessor
# 1. モデルとプロセッサのロード(大規模版モデルを使用)
model = SAMAudio.from_pretrained("facebook/sam-audio-large").to("cuda").eval()
processor = SAMAudioProcessor.from_pretrained("facebook/sam-audio-large")
# 2. 入力音声データとテキスト説明からバッチを作成
audio_file = "input.wav" # 分離したい音源ファイルパス
description = "犬の鳴き声" # 抽出・除去したい音の内容を指定
batch = processor(audios=[audio_file], descriptions=[description]).to("cuda")
# 3. 音源分離の実行
result = model.separate(batch)
# 4. 結果の取得(target: 抽出された音、residual: 残りの音)
target_waveform = result.target[0].cpu().numpy()
residual_waveform = result.residual[0].cpu().numpy()SAM Audioを使ってみた
それでは、実際にSAM Audioを使ってみます。
今回はSora 2で生成した以下の「ポッドキャスト配信している男性2人の動画」を入力とします。オリジナル音声としては、男性2人の声と軽いバックBGMですね。
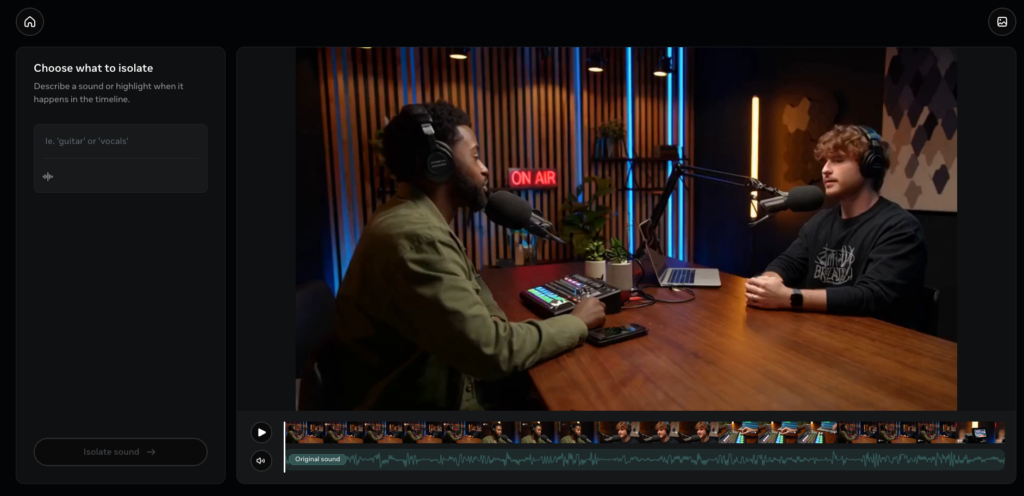
プロンプトは「voice」とします。
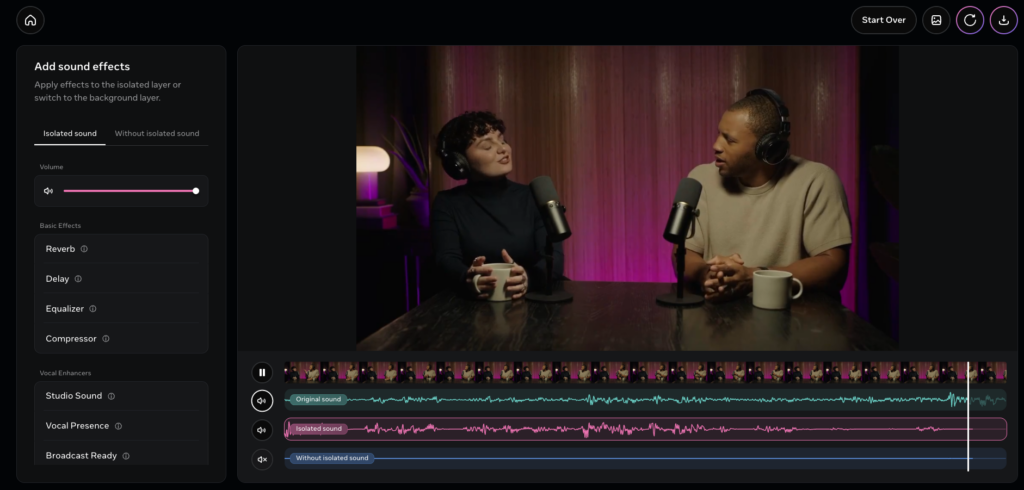
すると、以下の画像のように3段階の音声波形とボリュームなどの設定表示が出ました。
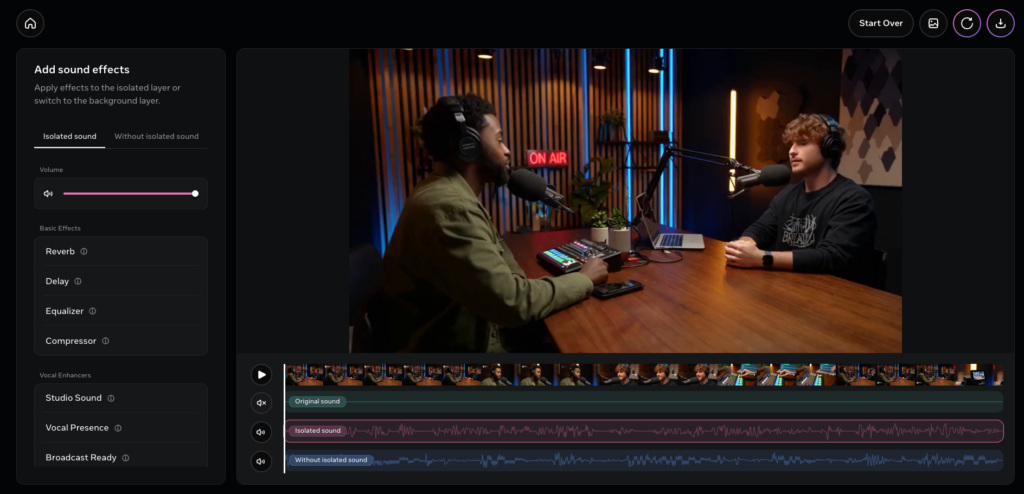
音声だけ抽出された動画はこちら
BGMだけ抽出された動画はこちら
特定の音だけをキレイに抽出・分離できていることがわかりますね。
今回はあまり複雑でない音声を入力として扱いましたが、より複雑なパターンでも抽出できるかと思いますので、木になる方は、ぜひ一度試してみてください!
まとめ
SAM Audioは、複雑に混ざり合った音声データから、特定の音だけを抽出・分離・除去できる最先端AIモデルです。
「聞こえないものを聞こえるようにし、消せない音を消せるようにする」ような機能は、クリエイターから研究者まで幅広いユーザーに恩恵をもたらしてくれそうです。
特に、これまでプロ用ツールと職人的スキルが必要だった音源のクリーンアップ作業が、誰でもPC一つで実現できるようになっているのはかなり可能性が広がりそうですね。
気になった方はぜひ試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

