- 1兆パラメータ規模のMixture-of-Experts (MoE) アーキテクチャを採用
- 「SWE-Bench Verified(コード問題集)」で71.3%を記録し、GPT-5に匹敵
- MITライセンスをベースとした「Modified MIT License(修正MIT)」のもと公開
2025年11月7日、中国のスタートアップMoonshot AI社が最新の大規模言語モデル「Kimi K2 Thinking」を公開しました!
— Kimi.ai (@Kimi_Moonshot) November 6, 2025
Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.SOTA on HLE (44.9%) and BrowseComp (60.2%)
Built… pic.twitter.com/lZCNBIgbV2
このモデルは1兆パラメータ規模のMixture-of-Experts (MoE) アーキテクチャを採用し、複雑な問題に対して人間の介入なしに数百ステップにわたる推論を行えることが特徴です。
完全オープンソースで公開されたにもかかわらず、主要なベンチマークでOpenAIのGPT-5やAnthropicのClaude 4.5といった最先端の商用モデルを上回る性能を示し、AIコミュニティに衝撃を与えています。
本記事では、このKimi K2 Thinkingの概要や性能、既存モデルとの違い、ライセンスや料金体系、使い方などを詳しく解説し、その凄さに迫っていきます。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
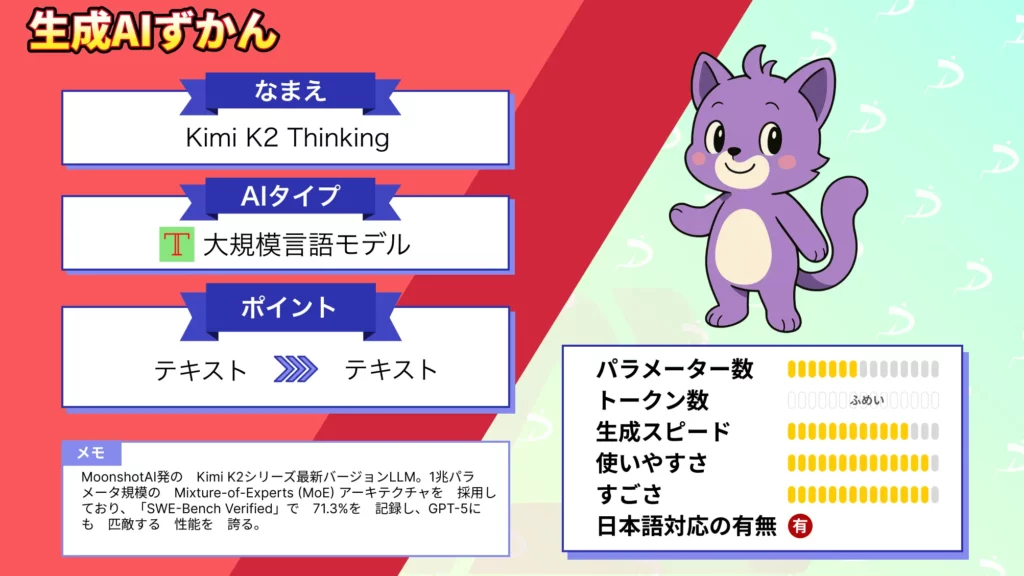
Kimi K2 Thinkingの概要
Kimi K2 Thinkingは、Moonshot AI社が開発した大規模言語モデルKimi K2シリーズの最新かつ最強バージョンです。
基本となるモデル構造は総パラメータ数1兆(推論時に動的に活性化されるパラメータは約320億)という巨大なMoEモデルで、前世代モデルKimi K2をベースに「思考力(Thinking)」を大幅に強化したエージェント志向のLLMとなっています。
最大の特徴は、チェーン・オブ・ソート(逐次思考)による段階的な推論とツールの動的呼び出しが統合された点です。
モデルは、回答を生成する過程で内部的に「思考内容」を保持しながら、必要に応じて外部の関数や検索などのツールを最大200~300回連続で呼び出すことができます。
これは、従来モデルが30~50ステップ程度で推論精度が劣化していたのを大きく上回り、長いタスクでも安定して自己完結的に処理を続けられることを意味しています。
また、コンテキストウィンドウは256kトークンという非常に長大な文脈に対応しており、長文のドキュメントや複数情報源を跨ぐ分析にも適しています。
加えてINT4量子化にネイティブ対応しているため、推論時の計算効率が飛躍的に向上しているのもポイントです。Moonshot独自の量子化対応訓練により精度を落とすことなく推論速度が2倍近く高速化されており、巨大モデルで懸念されるレイテンシやメモリ使用量を大幅に削減しています。


Kimi K2 Thinkingの性能
Kimi K2 Thinkingの性能は、多くのベンチマークで現行最高クラスの結果を収めています。
例えば総合的な推論力を測る「Humanity’s Last Exam (HLE)」では、ツール使用ありの設定で44.9%という正解率を達成し、同条件のGPT-5 (41.7%)やClaude 4.5 (32.0%)を上回りました。
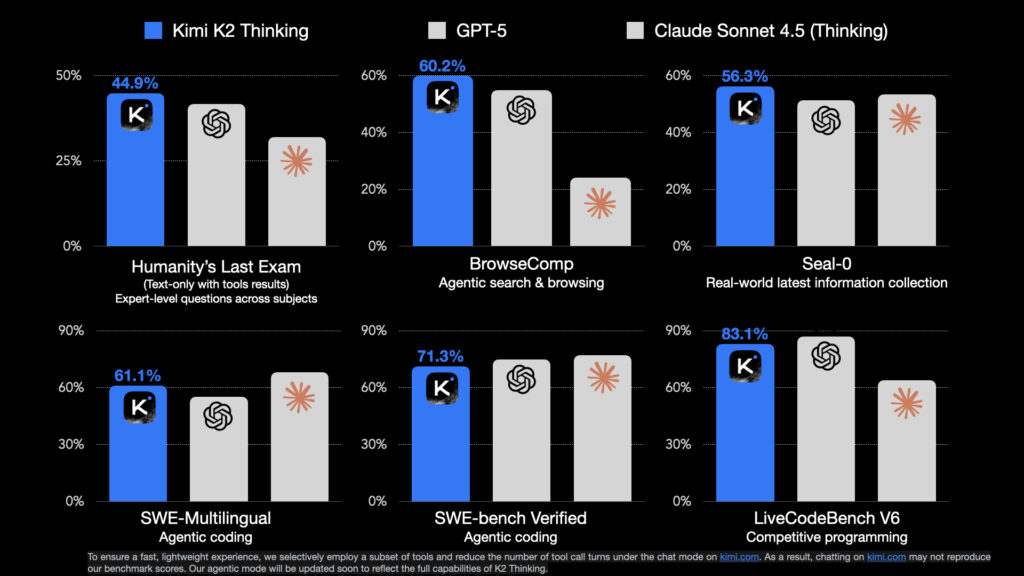
また、ウェブ検索を伴うエージェント推論テストの「BrowseComp」でも60.2%のスコアを記録し、GPT-5の54.9%やClaude 4.5の24.1%に対して大差でリードしています。
コーディング能力に関しても、「SWE-Bench Verified(コード問題集)」で71.3%、「LiveCodeBench v6(対話型コーディングテスト)」で83.1%と高い正解率を示し、最新のGPT-5と肩を並べるかそれ以上の結果を残しています。
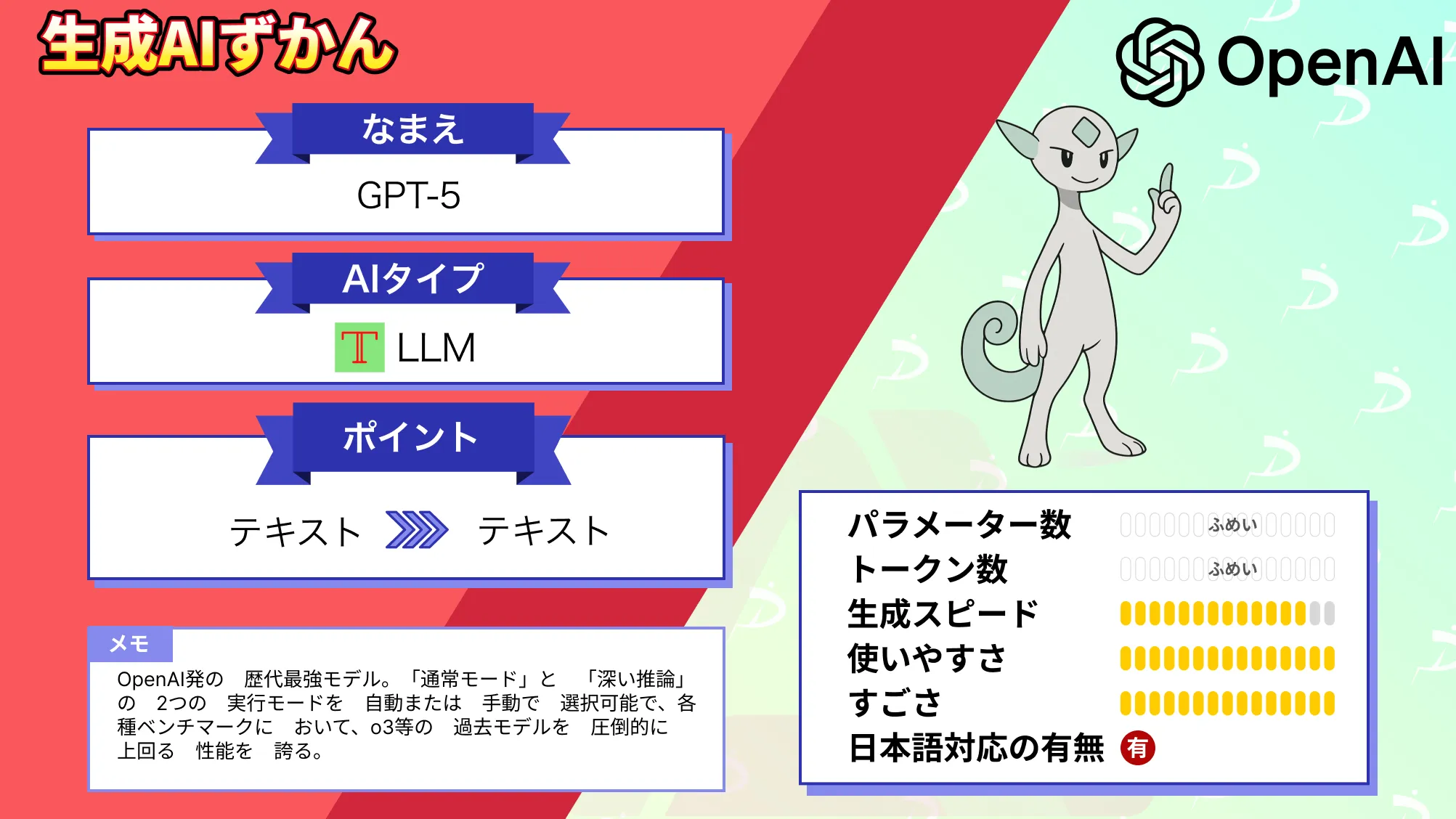
なお、GPT-5について詳しく知りたい方は、以下の記事も参考にしてみてください。
Kimi K2との違い
Kimi K2 Thinkingは、名前の通りKimi K2をベースに「Thinking(思考)」能力を強化したモデルであり、前世代のKimi K2と比べていくつかの違いがあります。
まず、推論アプローチの違いとして、Kimi K2が通常の対話型LLMであったのに対し、K2 Thinkingは思考過程を逐次描写しながら回答する特殊モード(チェーン・オブ・ソート)を備えています。
Kimi K2では、リリース当初「思考モード(Thought-mode)は未対応」だったため、モデル内部の推論過程をユーザーが直接見ることはできませんでした。
一方、K2 Thinkingでは、出力に最終回答とは別にreasoning_contentと呼ばれる思考ログを含めることが可能で、モデルがどのように考えステップを踏んだかが透明化されています。
次にツール使用について、Kimi K2は基本的にテキスト応答のみでしたが、K2 Thinkingでは訓練段階から外部ツールを挟んだ対話に最適化されており、ユーザーの要求に応じて自律的に関数や検索エンジンを呼び出す能力を持ちます。
これによって、ウェブ検索や計算、コード実行などを会話の途中でモデル自身が判断して行えるようになりました。
さらに長時間の安定動作も大きな改良点です。K2 Thinkingは最大300ステップ近い連続した思考・ツール実行にも耐え得るよう調整されており、長いタスクでも目的志向の挙動を維持することができるようになっています。
従来のKimi K2や他モデルでは30ステップ以上になると文脈が拡散し破綻しがちだったため、この「長時間安定性」の向上は実運用上非常に重要です。
なお、Kimi K2について詳しく知りたい方は、以下の記事も参考にしてみてください。

Kimi K2 Thinkingのライセンス
Kimi K2 Thinkingの提供ライセンスは、基本的にMITライセンスをベースとした「Modified MIT License(修正MIT)」となっています。
これはオープンソースとして公開されたKimi K2シリーズに共通する方針で、個人・企業を問わずモデルの利用、改変、再配布が自由に認められる緩めの規約です。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 |  | ※ユーザー1億人超のサービスはUIに名称表示義務 |
| 改変 | | |
| 配布 | | |
| 特許使用 | | |
| 私的使用 | |
Kimi K2 Thinkingの料金
Kimi K2 Thinking自体はモデルの重みが公開されたオープンソースプロジェクトであるため、自前でサーバやGPU環境を用意して実行する限り基本的に無料で利用可能です。
これはライセンス上の制約がほぼ無いことからも明らかで、研究者や個人がローカルで動かす場合や、企業が社内検証で利用する場合などにライセンス料は一切発生しません。
開発者向けにはMoonshot AIのプラットフォーム経由で公式APIが提供されていて、このAPI利用は従量課金制となっており、リクエストしたトークン数に応じて料金が発生します。以下に主な利用形態ごとの料金イメージをまとめます。
| 利用方法 | 料金 |
|---|---|
| セルフホスト | 無料(計算リソースは必要) |
| 公式Web(チャットUI) | 無料 |
| Moonshot公式API (入力トークン・キャッシュ有) | $0.15 / 100万トークン |
| Moonshot公式API (入力トークン・キャッシュ無) | $0.60 / 100万トークン |
| Moonshot公式API (出力トークン) | $2.50 / 100万トークン |
APIの「キャッシュ有/無」とは、以前に処理した同一または類似の入力を再利用できる場合に料金が割引される仕組みです。Moonshotプラットフォームでは結果をキャッシュしておき、キャッシュヒット時は$0.15/百万トークンで済むよう設計されています。
Kimi K2 Thinkingの使い方
Kimi K2 Thinkingは、一般ユーザー向けのチャットUIを使った方法と、開発者向けのAPI経由の方法で利用できます。それぞれ順を追って説明します。
ChatUIでの使い方
シンプルにK2 Thinkingを試すには、Moonshot AIが提供する公式チャットサービス「Kimi」を利用する方法があります。
まずブラウザで【公式サイト】(https://www.kimi.com/)にアクセスし、メールアドレス等でアカウント登録を行ってください。
登録後、ウェブ上のチャット画面からKimi K2 Thinkingと対話が可能になります。
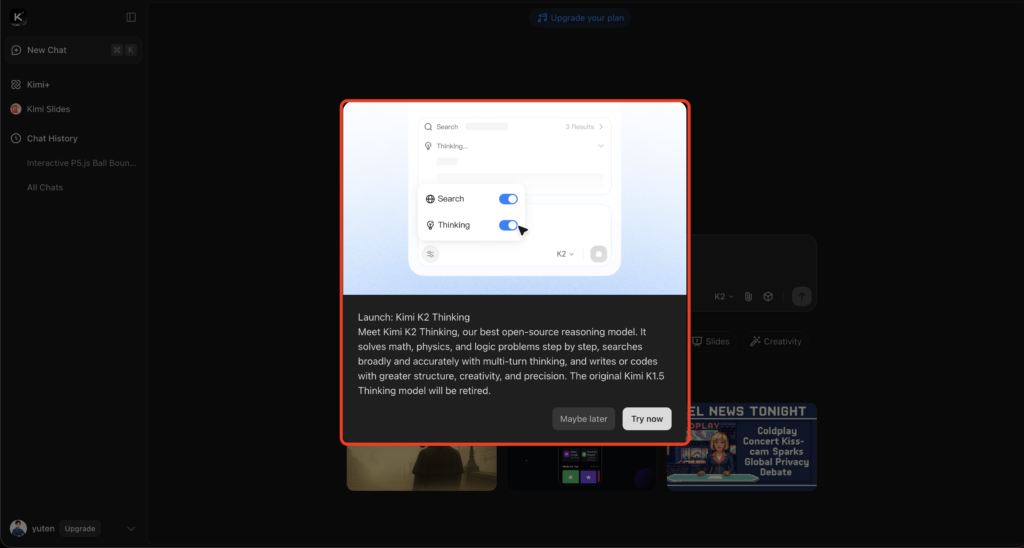
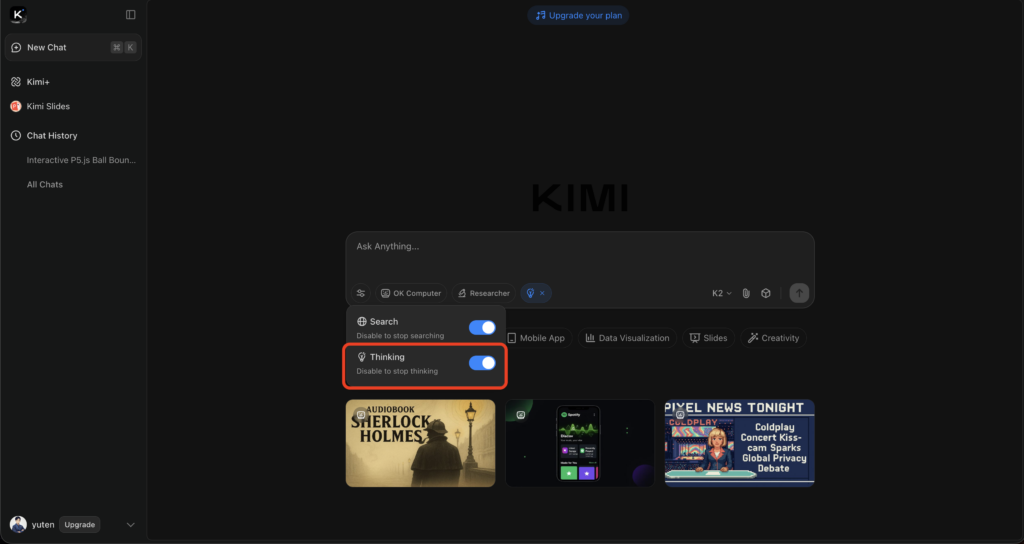
ChatGPTのようにテキストベースの対話を行えるインターフェースで、質問や指示を日本語で入力し、モデルからの回答を得ることができます。
リリース直後から英語・中国語はもちろん日本語での対話にも対応しており、専門的な知識がなくても気軽に最先端モデルの実力を試せます。
例えばプログラミングのコード補助を依頼したり、一般常識の質問をしたりといったことも自然な日本語でやり取りできます。現状、この公式Webチャットは無料で無制限に利用可能なため、まずはこのUIで色々と質問してみるのがおすすめです。
API経由での使い方
自分のアプリケーションやサービスにK2 Thinkingを統合したい開発者向けには、Moonshot AIの提供する公式APIを利用する方法があります。
まず、Moonshotのプラットフォームサイト(platform.moonshot.ai)上で開発者登録を行い、APIキーを発行します。
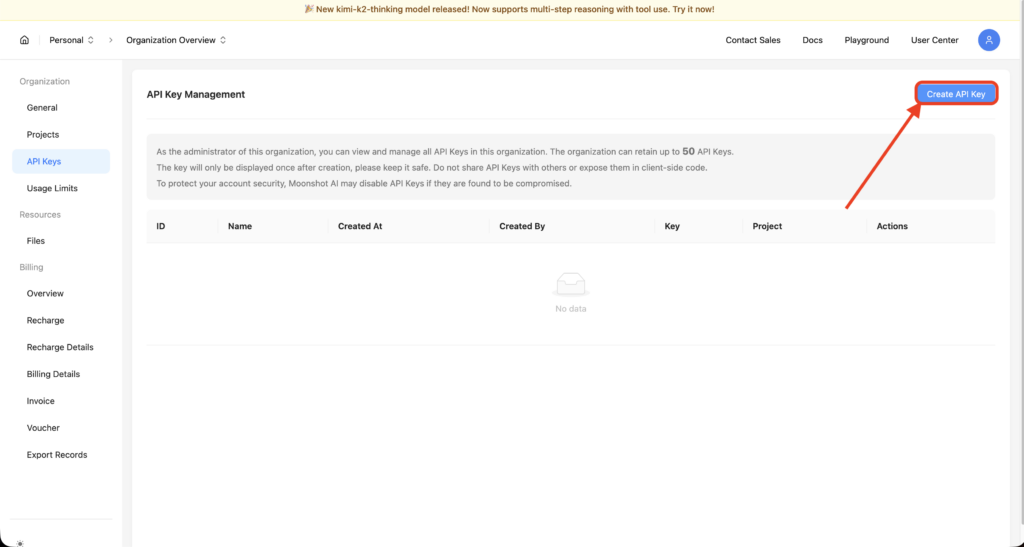
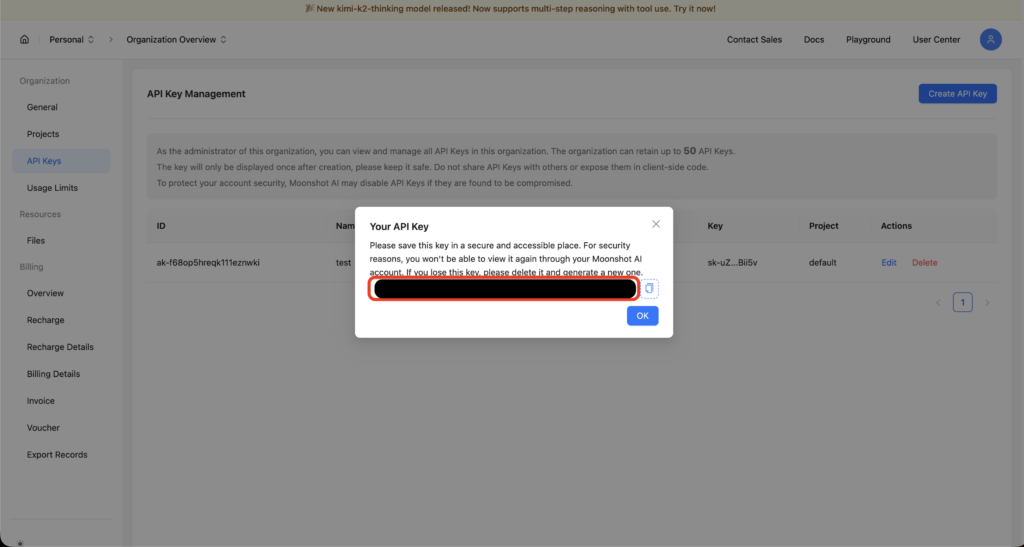
次にそのAPIキーを使い、OpenAIのAPIに似た形式でHTTPリクエストを送信してモデルを呼び出します。
具体的には、エンドポイントURLやリクエストフォーマットはOpenAIのChat Completion APIと互換性があるため、既存のOpenAI用SDK(例えばopenaiのPythonパッケージなど)を流用してエンドポイントURLとモデル名を差し替えるだけで利用することができます。
モデル名は "kimi-k2-thinking" を指定して、メッセージ(ユーザー発話やシステムプロンプト)をJSONで渡すと、モデルからの回答がJSONで返ってきます。基本的な使い方はOpenAI APIとほぼ同様なので、扱いやすいと思います。


Kimi K2 Thinking vs GPT-5で比較検証してみた
それでは実際にKimi K2 Thinkingの性能を確認するべく、GPT-5と比較検証していきましょう。数理タスクとコーディングタスクの2つで両モデルのアウトプットを比較します。
数理タスク
プロンプトはこちら
あなたは厳密な数値計算を行うアシスタントです。以下の要件に従って計算してください。
回答は日本語で、最終結果のみを出力します。
思考過程・途中式は出力しません。
必要な場合のみ、根拠は100字以内で簡潔に記します。
四捨五入は JIS の「四捨五入(0.5以上切り上げ)」で、指定の小数点桁に丸めてください。
課題:
ある勉強会に会場席200・オンライン席500が用意されています。
申込は一般Aが260名、一般Bが180名、学生が140名でした。
一般Aは会場席を優先的に割り当て、残りはオンラインに回します。
一般Bは会場とオンラインを申込比で按分して割り当てます(会場上限内)。
学生は残った会場席があればそこから割り当て、残りはオンラインです。
出席率は一般A 92.5%、一般B 88.0%、学生 81.0% とします。
参加費は一般A 3,800円、一般B 3,200円、学生 1,000円です(いずれも税込み)。
求める値:
会場出席者の見込み人数(小数点以下四捨五入、整数)
オンライン出席者の見込み人数(同上)
想定売上合計(円、整数)
出力フォーマット(厳守):
最終回答:
会場出席見込み=XXX
オンライン出席見込み=YYY
想定売上合計=ZZZ
根拠: (100字以内)GPT-5の出力結果はこちら
最終回答:
会場出席見込み=185
オンライン出席見込み=327
想定売上合計=1534180
根拠: 会場200席は一般Aで満席。他はオンライン。各区分に出席率を掛け、四捨五入し、売上は期待出席数×単価の総和。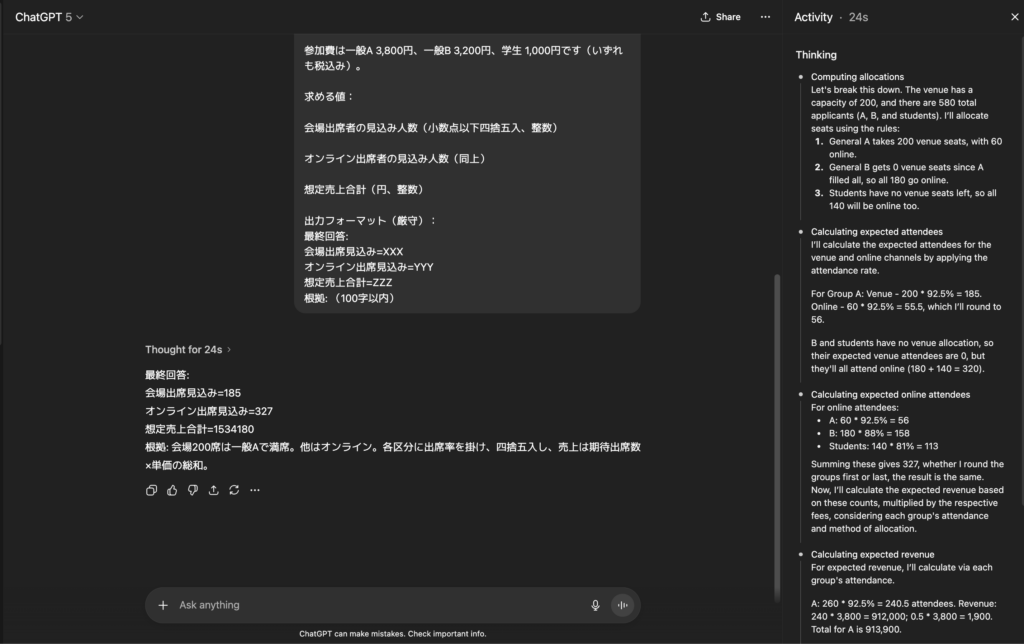
Kimi K2 Thinkingの出力結果はこちら
最終回答:
会場出席見込み=185
オンライン出席見込み=327
想定売上合計=1534180
根拠: 一般Aが会場200席を確保、他はオンラインのみ。各区分の申込数に出席率を乗じ計算、四捨五入。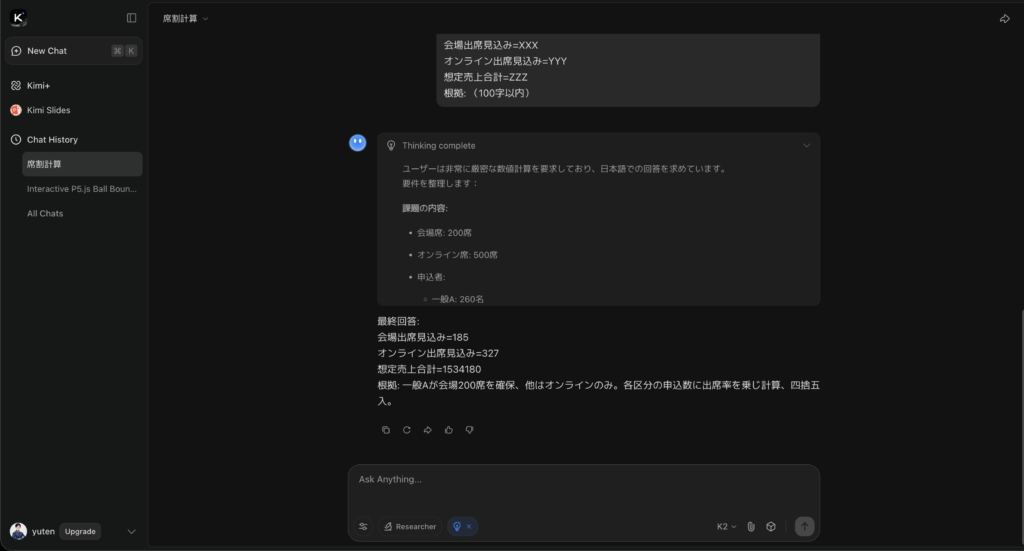
最終回答までにかかった時間はGPT-5が25秒ほど、Kimi K2 Thinkingが60秒ほど。どちらも正解で素晴らしいです。
両モデルの相違点を挙げるとするならば、Kimi K2 Thinkingの方が時間をかけている分、かなり深く、パターンごとに細かく思考している印象です。
続いてコーディングタスクについても検証してみましょう。
コーディングタスク
プロンプトはこちら
あなたはPythonエンジニアです。標準ライブラリのみで実装してください(re, json, datetime, csv, decimal, itertools, collections などは可、外部ライブラリ不可)。
出力はコードブロック(python ... )に関数定義を示し、その直後に最終JSONのみを別コードブロック(json ... )で出力します。
思考過程や説明、実行ログは出力しません。
小数計算はDecimalで厳密に扱い、金額は**円単位に四捨五入(0.5以上切り上げ)**してください。
仕様:
与えられたCSV(UTF-8、ヘッダあり)を読み取り、店舗×カテゴリの税込売上合計とgrand_totalを算出してJSONで返す関数 aggregate(csv_text: str) -> dict を実装してください。
列: order_id,timestamp,store,category,item,unit_price,qty
通貨表記のゆらぎ(¥, 円, カンマ区切り、全角/半角スペース)は正規化して円として解釈します。
税率: food は 8%, それ以外は 10%。
返品は qty < 0 としてマイナス計上します。
同一 order_id が複数行ある場合は、timestamp が最も新しいものだけを採用します(他は無視)。timestamp はISO 8601(例: 2025-11-05T10:02:00+09:00)。
小計=unit_price * qty、税込=小計×(1+税率)。最終的に店舗×カテゴリ単位で合算し、金額は円整数に四捨五入してください。
出力JSONのキー順・構造は次の通り:
{
"by_store": {
"<store>": {
"<category>": <税込合計(円整数)>,
...
},
...
},
"grand_total": <全店舗全カテゴリの税込合計(円整数)>
}
テスト用入力(この文字列をそのまま関数に渡して集計し、結果JSONを出力してください):
order_id,timestamp,store,category,item,unit_price,qty
A001,2025-11-05T10:02:00+09:00,Shibuya,food,Onigiri,¥120,3
A002,2025-11-05T10:05:00+09:00,Shibuya,goods,Notebook,JPY 220,2
A001,2025-11-05T10:06:00+09:00,Shibuya,food,Onigiri,¥130,3
A003,2025-11-05T11:00:00+09:00,Shinjuku,food,Bento,1,000,1
A004,2025-11-05T11:10:00+09:00,Shibuya,goods,Pen,80円,5
A005,2025-11-05T11:20:00+09:00,Shinjuku,goods,Notebook,¥220,1
A006,2025-11-05T12:00:00+09:00,Shibuya,food,Bento,¥1,000,-1
出力フォーマット(厳守):
# ここに関数定義を記述
{ ... 最終結果 ... }GPT-5の出力結果はこちら
from decimal import Decimal, ROUND_HALF_UP, getcontext
from datetime import datetime
import csv
import re
from io import StringIO
from collections import defaultdict
getcontext().prec = 28
def aggregate(csv_text: str) -> dict:
def parse_price(s: str) -> Decimal:
# Normalize currency string to Decimal yen
s = s.strip()
s = re.sub(r'\s+', '', s) # remove all spaces (half/full width)
s = s.replace('¥', '¥')
# keep digits, minus and dots/commas, then remove commas
s = re.sub(r'[^\d\-\.,]', '', s)
s = s.replace(',', '')
if s in ('', '-', '--', '.'):
return Decimal('0')
return Decimal(s)
f = StringIO(csv_text)
reader = csv.DictReader(f)
latest = {}
for row in reader:
oid = row['order_id']
ts = datetime.fromisoformat(row['timestamp'])
if (oid not in latest) or (ts > latest[oid][0]):
latest[oid] = (ts, row)
sums = defaultdict(Decimal) # key: (store, category)
for _, row in latest.values():
store = row['store']
category = row['category']
price = parse_price(row['unit_price'])
try:
qty = Decimal(str(int(row['qty'])))
except ValueError:
qty = Decimal('0')
subtotal = price * qty
rate = Decimal('0.08') if category.strip().lower() == 'food' else Decimal('0.10')
gross = subtotal * (Decimal('1') + rate)
sums[(store, category)] += gross
by_store = {}
for (store, category), amount in sums.items():
rounded = int(amount.quantize(Decimal('1'), rounding=ROUND_HALF_UP))
by_store.setdefault(store, {})[category] = rounded
# Ensure deterministic order by sorting stores and categories
ordered_by_store = {}
for store in sorted(by_store):
ordered_by_store[store] = {k: by_store[store][k] for k in sorted(by_store[store])}
grand = sum(Decimal(v) for s in by_store.values() for v in s.values())
# grand should be computed from unrounded sums; recompute carefully:
grand_unrounded = sum(sums.values(), Decimal('0'))
grand_total = int(grand_unrounded.quantize(Decimal('1'), rounding=ROUND_HALF_UP))
return {
"by_store": ordered_by_store,
"grand_total": grand_total
}{
"by_store": {
"Shibuya": {
"food": -659,
"goods": 924
},
"Shinjuku": {
"food": 1080,
"goods": 242
}
},
"grand_total": 1587
}Kimi K2 Thinkingの出力結果はこちら
import csv
from datetime import datetime
from decimal import Decimal, ROUND_HALF_UP, InvalidOperation
from collections import defaultdict
import re
def aggregate(csv_text: str) -> dict:
latest_orders = {}
reader = csv.DictReader(csv_text.strip().splitlines())
for row in reader:
order_id = row['order_id'].strip()
timestamp_str = row['timestamp'].strip()
price_str = row['unit_price'].strip()
qty_str = row['qty'].strip()
try:
timestamp = datetime.fromisoformat(timestamp_str)
price = normalize_price(price_str)
qty = int(qty_str)
store = row['store'].strip()
category = row['category'].strip()
if order_id not in latest_orders or timestamp > latest_orders[order_id][0]:
latest_orders[order_id] = (timestamp, {
'store': store,
'category': category,
'price': price,
'qty': qty
})
except (ValueError, InvalidOperation):
continue
store_category_totals = defaultdict(lambda: defaultdict(Decimal))
for timestamp, data in latest_orders.values():
store = data['store']
category = data['category']
price = data['price']
qty = data['qty']
subtotal = price * qty
tax_rate = Decimal('1.08') if category.lower() == 'food' else Decimal('1.10')
tax_included = subtotal * tax_rate
store_category_totals[store][category] += tax_included
result = {'by_store': {}, 'grand_total': 0}
grand_total = 0
for store, categories in store_category_totals.items():
result['by_store'][store] = {}
for category, total in categories.items():
rounded_total = int(total.quantize(Decimal('1'), rounding=ROUND_HALF_UP))
result['by_store'][store][category] = rounded_total
grand_total += rounded_total
result['grand_total'] = grand_total
return result
def normalize_price(price_str: str) -> Decimal:
cleaned = re.sub(r'\s+', '', price_str, flags=re.UNICODE)
cleaned = re.sub(r'[¥JPY円]', '', cleaned, flags=re.IGNORECASE)
cleaned = cleaned.replace(',', '')
if not cleaned:
raise ValueError('Empty price')
return Decimal(cleaned){
"by_store": {
"Shibuya": {
"food": -659,
"goods": 924
},
"Shinjuku": {
"food": 1080,
"goods": 242
}
},
"grand_total": 1587
}どちらも出力値は正確で仕様への遵守も概ねいい感じです。通貨の正規化などの処理も問題なく正解にたどり着いてくれています。
比較検証の結果、Kimi K2 ThinkingはGPT-5と肩を並べるかそれ以上の性能であるということは、間違いではなさそうです!
まとめ
Kimi K2 Thinkingは、オープンソースAIの新たなマイルストーンとも言える存在です。
1兆パラメータの巨大モデルでありながら動的思考と長時間の自律動作を実現し、その性能はGPT-5やClaude 4.5といった最先端の閉源モデルに肩を並べています。
しかも修正MITライセンスによって非常に自由に利用できるため、研究者から企業まで幅広い層がこの最先端モデルを活用できる状況が生まれました。
これは、「最高性能のAI=限られた企業だけのもの」という従来の図式を大きく変える出来事です。
実際、本モデルの登場により「もはや高額な商用APIに頼らなくても、自前でトップクラスのAIを運用できるのではないか」という声も上がっています。
気になる方はぜひ一度試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。 ︎株式会社WEELのサービスを詳しく見る。
︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

